alexshengzhili/mllm-dpo
收藏Hugging Face2024-04-13 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/alexshengzhili/mllm-dpo
下载链接
链接失效反馈官方服务:
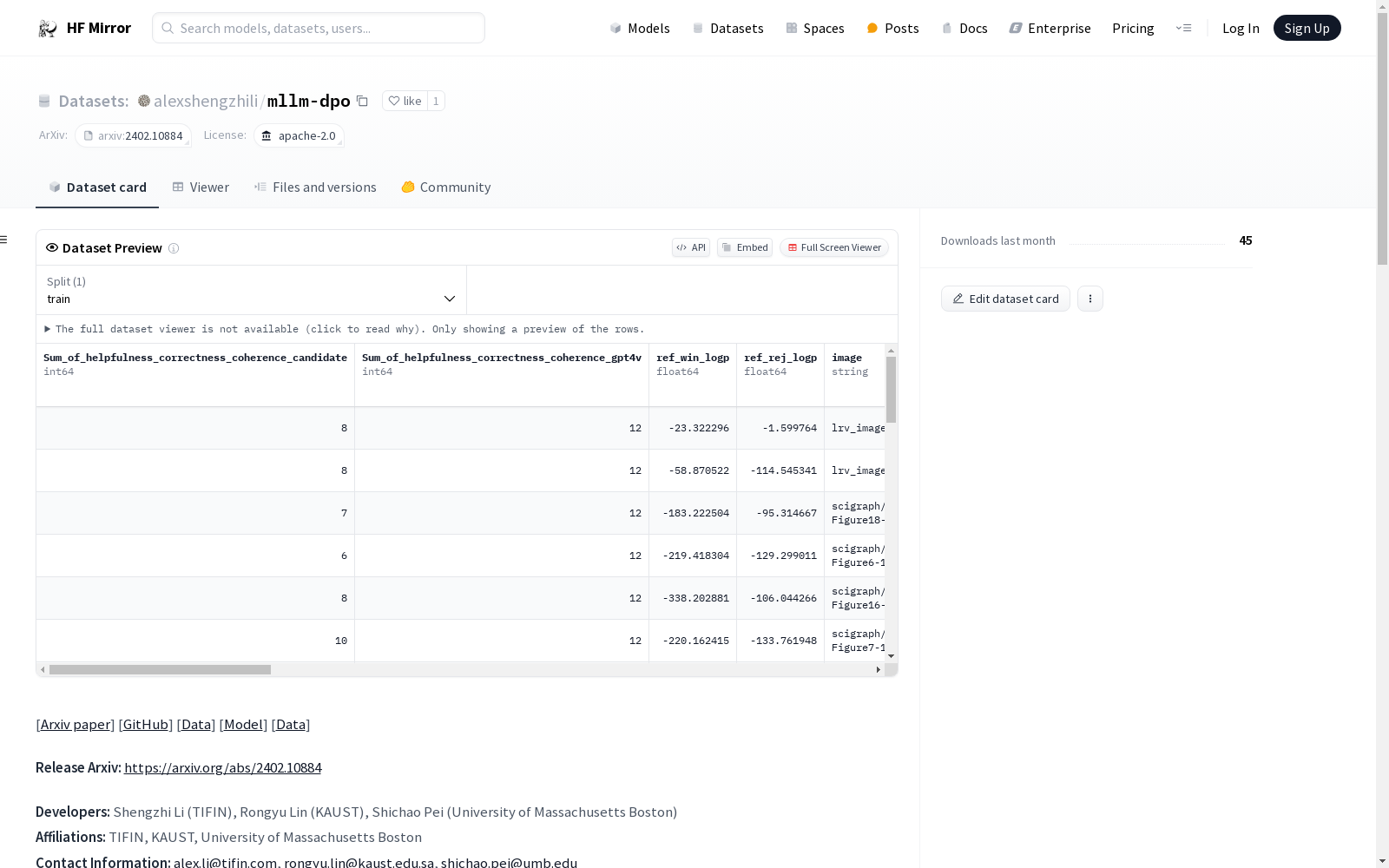
资源简介:
---
license: apache-2.0
---
[[Arxiv paper](https://arxiv.org/abs/2402.10884)]
[[GitHub](https://github.com/findalexli/mllm-dpo)]
[[Data](https://huggingface.co/datasets/alexshengzhili/llava-preference-dpo)]
[[Model](https://huggingface.co/alexshengzhili/llava-v1.5-13b-dpo/edit/main/README.md)]
[[Data](https://huggingface.co/datasets/alexshengzhili/mllm-dpo)]
**Release Arxiv:** [https://arxiv.org/abs/2402.10884](https://arxiv.org/abs/2402.10884)
**Developers:** Shengzhi Li (TIFIN), Rongyu Lin (KAUST), Shichao Pei (University of Massachusetts Boston)
**Affiliations:** TIFIN, KAUST, University of Massachusetts Boston
**Contact Information:** alex.li@tifin.com, rongyu.lin@kaust.edu.sa, shichao.pei@umb.edu
## Overview
The llava-v1.5-13b-dpo model and corresponding data set is designed to enhance the instruction-following capabilities of multi-modal large language models (MLLMs), particularly in scenarios where visual instruction tuning might degrade language proficiency. This model leverages a novel Direct Preference Optimization (DPO) method, along with a curated 6K-entry VQA preference dataset, to achieve superior performance on multi-modal tasks and benchmarks.
## Intended Use
- **Primary Applications:** This model is intended for tasks requiring the integration of text and image modalities, including but not limited to visual question answering (VQA), image captioning, and multi-modal instruction following.
- **Target Audience:** Researchers and practitioners in the fields of natural language processing, computer vision, and multi-modal AI.
## Training Data
The MM-LLM-DPO model was trained using a lightweight (6k entries) VQA preference dataset, where answers were annotated for 5 quality metrics in a granular fashion. The dataset was designed to address the diversity and complexity gap typically observed in VQA datasets.
## Evaluation
The model demonstrates significant improvements over baseline models like Vicuna and LLaVA on various benchmarks:
- **MT-Bench:** Achieved a score of 6.73, surpassing Vicuna's 6.57 and LLaVA's 5.99.
- **Visual Instruction Performance:** Recorded a +4.9% improvement on MM-Vet and +6% on LLaVA-Bench.
| Model Name | MM-Vet | LLaVA-bench | PoPe | MM-Bench | MT-bench | AlpacaEval |
|------------|--------|-------------|-------|----------|----------|------------|
| **Vicuna-1.5-13b [16]** | - | - | - | - | 6.57 | 81.4 |
| **LLaVA-1.5-13b [10]** | 36.3 | 73.1 | 0.859 | 67.4 | 5.99 | 79.3 |
| **LLaVA-RLHF-13b [23]**| 37.2 | 76.8 | 0.869 | 60.1 | 6.18 | 81.0 |
| **Standard SFT** | 36.5 | 63.7 | 0.850 | 65.4 | 5.01 | 50.2 |
| **SteerLM** | 35.2 | 67.0 | 0.878 | 65.1 | 5.70 | 68.8 |
| **Rejection-sampling** | 38.0 | 70.6 | 0.883 | 67.6 | 6.22 | 74.9 |
| **llava-v1.5-13b-dpo** | 41.2 | 79.1 | 0.870 | 66.8 | 6.73 | 86.4 |
*We applied the last four Standard sft, SteerLM, Rejection Sampling and DPO, and found DPO to be most performant
## Ethical Considerations
This model was developed with a focus on mitigating modality conflict and catastrophic forgetting in MLLMs. Users are encouraged to consider the potential biases and limitations inherent in the training data and model outputs, especially when deploying the model in diverse and sensitive contexts.
## Limitations
- The model's training dataset, while addressing key gaps in VQA datasets, is relatively small at 6k entries. This may limit the model's generalizability across broader or more diverse multi-modal tasks.
- Performance enhancements, particularly in language instruction capabilities post-visual tuning, are based on the current scope of evaluated benchmarks and datasets. The model's efficacy may vary in different or more challenging contexts.
## Acknowledgments
This work was made possible through the contributions of Shengzhi Li, Rongyu Lin, and Shichao Pei, and supported by their respective institutions.
## Citation
Please cite this work as:
```bibtex
@misc{li2024multimodal,
title={Multi-modal preference alignment remedies regression of visual instruction tuning on language model},
author={Shengzhi Li and Rongyu Lin and Shichao Pei},
year={2024},
eprint={2402.10884},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
许可证:Apache-2.0
[[Arxiv论文](https://arxiv.org/abs/2402.10884)]
[[GitHub仓库](https://github.com/findalexli/mllm-dpo)]
[[数据集](https://huggingface.co/datasets/alexshengzhili/llava-preference-dpo)]
[[模型](https://huggingface.co/alexshengzhili/llava-v1.5-13b-dpo/edit/main/README.md)]
[[数据集](https://huggingface.co/datasets/alexshengzhili/mllm-dpo)]
**论文发布地址:** [https://arxiv.org/abs/2402.10884](https://arxiv.org/abs/2402.10884)
**开发者:** 李盛智(TIFIN)、林容宇(阿卜杜拉国王科技大学,KAUST)、裴世超(马萨诸塞大学波士顿分校)
**所属机构:** TIFIN、阿卜杜拉国王科技大学(KAUST)、马萨诸塞大学波士顿分校
**联系方式:** alex.li@tifin.com, rongyu.lin@kaust.edu.sa, shichao.pei@umb.edu
## 概述
llava-v1.5-13b-dpo模型及对应数据集旨在增强多模态大语言模型(Multi-modal Large Language Model, MLLM)的指令遵循能力,尤其针对视觉指令微调可能降低语言能力的场景。本模型采用了一种新颖的直接偏好优化(Direct Preference Optimization, DPO)方法,并结合了精心构建的6000条规模的视觉问答(Visual Question Answering, VQA)偏好数据集,从而在多模态任务与基准测试中取得更优性能。
## 预期用途
- **核心应用场景**:本模型适用于需要融合文本与图像模态的任务,包括但不限于视觉问答(VQA)、图像字幕生成以及多模态指令遵循。
- **目标受众**:自然语言处理、计算机视觉及多模态人工智能领域的研究人员与从业者。
## 训练数据
MM-LLM-DPO模型使用一个轻量化的(6000条数据)VQA偏好数据集进行训练,该数据集针对答案从5个质量维度进行了精细化标注。本数据集旨在弥补现有VQA数据集普遍存在的多样性与复杂度缺口。
## 模型评估
本模型在多项基准测试中显著优于Vicuna与LLaVA等基线模型:
- **MT-Bench**:得分达6.73,超过Vicuna的6.57与LLaVA的5.99。
- **视觉指令性能**:在MM-Vet基准上提升4.9%,在LLaVA-Bench基准上提升6%。
| 模型名称 | MM-Vet | LLaVA-bench | PoPe | MM-Bench | MT-bench | AlpacaEval |
|------------|--------|-------------|-------|----------|----------|------------|
| **Vicuna-1.5-13b [16]** | - | - | - | - | 6.57 | 81.4 |
| **LLaVA-1.5-13b [10]** | 36.3 | 73.1 | 0.859 | 67.4 | 5.99 | 79.3 |
| **LLaVA-RLHF-13b [23]**| 37.2 | 76.8 | 0.869 | 60.1 | 6.18 | 81.0 |
| **标准监督微调(Standard SFT)** | 36.5 | 63.7 | 0.850 | 65.4 | 5.01 | 50.2 |
| **SteerLM** | 35.2 | 67.0 | 0.878 | 65.1 | 5.70 | 68.8 |
| **拒绝采样(Rejection-sampling)** | 38.0 | 70.6 | 0.883 | 67.6 | 6.22 | 74.9 |
| **llava-v1.5-13b-dpo** | 41.2 | 79.1 | 0.870 | 66.8 | 6.73 | 86.4 |
*我们对标准监督微调(Standard SFT)、SteerLM、拒绝采样(Rejection Sampling)与DPO四种方法进行了对比实验,结果显示DPO的综合性能最优。
## 伦理考量
本模型的开发聚焦于缓解多模态大语言模型中的模态冲突与灾难性遗忘问题。我们鼓励用户在将模型部署于多样化且敏感的场景时,充分考虑训练数据与模型输出中潜在的偏见与局限性。
## 局限性
- 本模型的训练数据集虽弥补了VQA数据集的部分关键缺口,但规模仅为6000条,相对较小,这可能限制模型在更广泛或更多样化的多模态任务中的泛化能力。
- 性能提升(尤其是视觉微调后语言指令能力的提升)基于当前评估的基准测试与数据集范围,模型在不同或更具挑战性的场景中的效果可能存在差异。
## 致谢
本研究得益于李盛智、林容宇与裴世超的贡献,并得到其所属机构的支持。
## 引用格式
请按以下格式引用本工作:
bibtex
@misc{li2024multimodal,
title={Multi-modal preference alignment remedies regression of visual instruction tuning on language model},
author={Shengzhi Li and Rongyu Lin and Shichao Pei},
year={2024},
eprint={2402.10884},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
提供机构:
alexshengzhili
原始信息汇总
数据集概述
模型与数据集设计
- 目的: 提升多模态大型语言模型(MLLMs)的指令遵循能力,特别是在视觉指令调优可能降低语言熟练度的场景中。
- 技术: 采用直接偏好优化(DPO)方法和6K条目VQA偏好数据集。
预期用途
- 主要应用: 文本和图像模态整合任务,如视觉问答(VQA)、图像标注和多模态指令遵循。
- 目标用户: 自然语言处理、计算机视觉和多模态AI领域的研究者和实践者。
训练数据
- 数据集: 使用6K条目的轻量级VQA偏好数据集,针对5个质量指标进行细致标注。
评估
- 性能提升: 在多个基准测试中超越基线模型,如Vicuna和LLaVA。
- 具体成绩: 在MT-Bench上得分6.73,MM-Vet上提升4.9%,LLaVA-Bench上提升6%。
伦理考量
- 关注点: 用户应考虑训练数据和模型输出中可能存在的偏见和局限性,特别是在多样化和敏感环境中部署时。
限制
- 数据集大小: 6K条目的数据集可能限制模型在更广泛或多样的多模态任务中的泛化能力。
- 性能评估: 性能提升基于当前评估的基准和数据集,可能在不同或更具挑战性的环境中表现不同。
致谢
- 贡献者: Shengzhi Li, Rongyu Lin, Shichao Pei。
- 支持机构: TIFIN, KAUST, University of Massachusetts Boston。
引用信息
- 引用格式: bibtex @misc{li2024multimodal, title={Multi-modal preference alignment remedies regression of visual instruction tuning on language model}, author={Shengzhi Li and Rongyu Lin and Shichao Pei}, year={2024}, eprint={2402.10884}, archivePrefix={arXiv}, primaryClass={cs.CL} }
搜集汇总
数据集介绍
构建方式
该数据集的构建基于一个轻量级的6K条目视觉问答(VQA)偏好数据集,旨在通过细粒度的质量指标注释答案,以解决传统VQA数据集中常见的多样性和复杂性不足的问题。通过这种精细化的数据集设计,模型能够更有效地进行多模态指令跟随能力的训练,特别是在视觉指令调整可能降低语言熟练度的情况下。
特点
此数据集的显著特点在于其采用了新颖的直接偏好优化(DPO)方法,这种方法在多模态任务中表现出色,尤其是在多模态指令跟随和视觉问答任务中。此外,数据集的构建考虑了模态冲突和灾难性遗忘的问题,确保模型在多模态环境中的稳定性和高效性。
使用方法
该数据集主要用于需要文本和图像模态集成的任务,如视觉问答、图像描述生成和多模态指令跟随等。目标用户包括自然语言处理、计算机视觉和多模态AI领域的研究人员和实践者。使用时,建议结合具体的任务需求和模型评估指标,如MT-Bench、MM-Vet和LLaVA-Bench等,以全面评估模型的性能。
背景与挑战
背景概述
在多模态大语言模型(MLLMs)领域,视觉指令调优往往会导致语言能力的退化,这一问题引起了广泛关注。为了解决这一核心研究问题,Shengzhi Li(TIFIN)、Rongyu Lin(KAUST)和Shichao Pei(University of Massachusetts Boston)等研究人员于2024年提出了llava-v1.5-13b-dpo模型及其配套数据集。该模型通过引入直接偏好优化(DPO)方法,结合精心设计的6K条目VQA偏好数据集,旨在提升MLLMs在多模态任务中的指令遵循能力。这一研究不仅填补了现有VQA数据集在多样性和复杂性方面的空白,还显著提升了模型在多模态任务和基准测试中的表现,对自然语言处理和计算机视觉领域具有重要影响。
当前挑战
尽管llava-v1.5-13b-dpo模型在多模态任务中表现出色,但其构建过程中仍面临若干挑战。首先,训练数据集规模相对较小,仅包含6K条目,这可能限制了模型在更广泛或更多样化多模态任务中的泛化能力。其次,模型在视觉指令调优后对语言指令能力的提升主要基于当前评估的基准和数据集,其在不同或更具挑战性环境中的有效性尚需进一步验证。此外,模型在处理多模态数据时可能存在潜在的偏见和局限性,特别是在敏感和多样化应用场景中,这些因素需引起用户的高度重视。
常用场景
经典使用场景
在多模态大语言模型(MLLMs)的指令遵循能力提升中,alexshengzhili/mllm-dpo数据集展现了其经典应用场景。该数据集特别适用于需要整合文本和图像模态的任务,如视觉问答(VQA)、图像描述生成以及多模态指令遵循。通过引入新颖的直接偏好优化(DPO)方法,结合精心设计的6K条目VQA偏好数据集,该模型在多模态任务和基准测试中表现卓越,显著提升了模型的多模态任务处理能力。
衍生相关工作
基于alexshengzhili/mllm-dpo数据集,衍生了一系列相关经典工作。例如,研究者们进一步探索了DPO方法在不同模态数据集上的适用性,开发了更高效的模态对齐算法。此外,该数据集还激发了对多模态数据集构建和评估标准的深入研究,推动了多模态AI领域的技术进步。这些工作不仅丰富了多模态学习的理论基础,也为实际应用提供了强有力的技术支持。
数据集最近研究
最新研究方向
在多模态大语言模型(MLLMs)领域,最新的研究方向聚焦于提升模型在视觉指令调整后仍能保持语言能力的稳定性。alexshengzhili/mllm-dpo数据集及其对应的llava-v1.5-13b-dpo模型,通过引入直接偏好优化(DPO)方法,成功解决了视觉指令调整可能导致的语言能力下降问题。该研究不仅在多模态任务和基准测试中取得了显著的性能提升,还在MT-Bench、MM-Vet和LLaVA-Bench等关键指标上超越了现有模型。这一进展对于推动多模态AI技术在自然语言处理和计算机视觉交叉领域的应用具有重要意义,尤其是在视觉问答(VQA)和图像描述等任务中,展现了其潜在的广泛应用前景。
以上内容由遇见数据集搜集并总结生成


