RubikBench
收藏Hugging Face2026-02-03 更新2026-02-05 收录
下载链接:
https://huggingface.co/datasets/Magolor/RubikBench
下载链接
链接失效反馈官方服务:
资源简介:
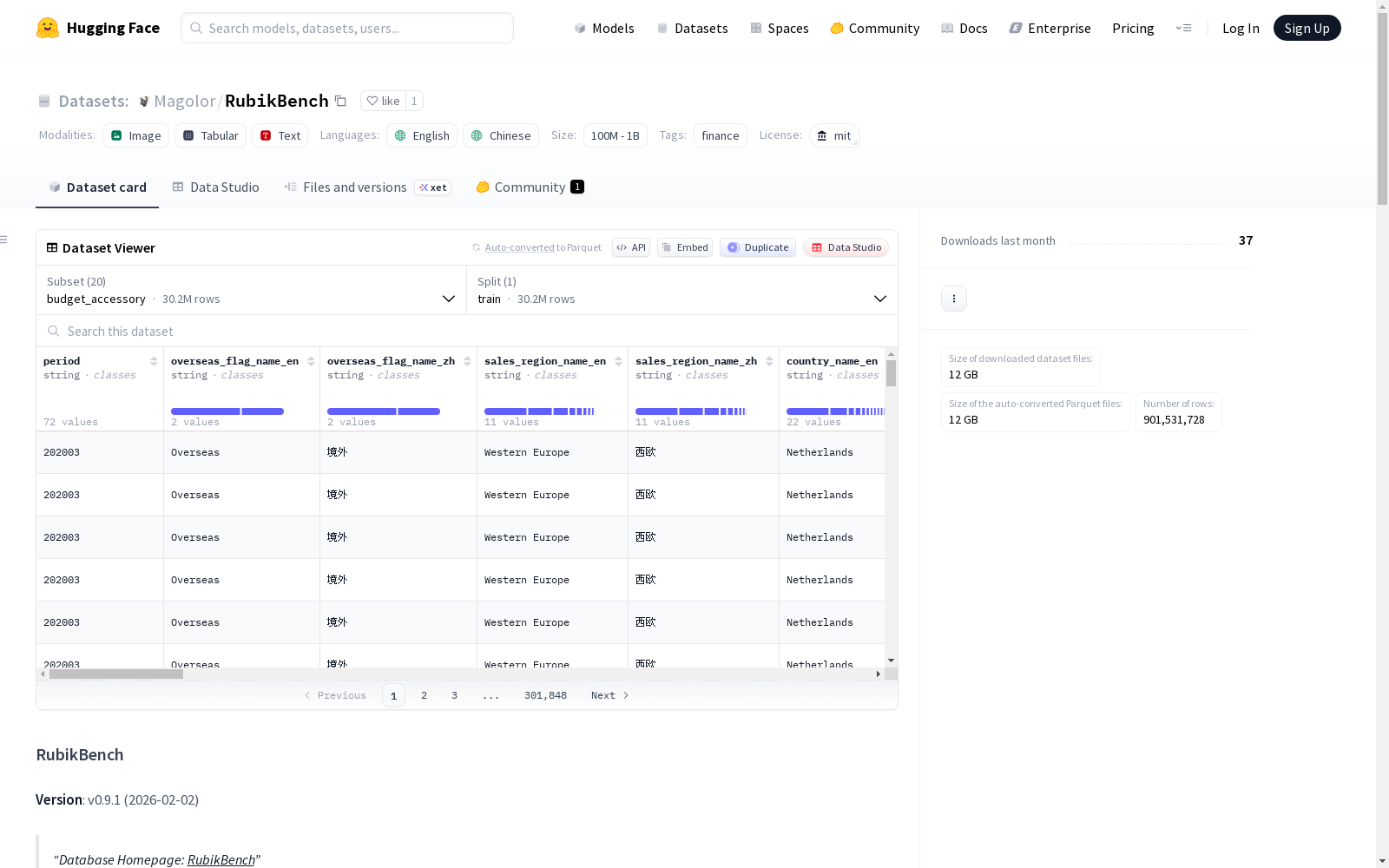
RubikBench 是一个企业级规模的财务数据库,专为自然语言到 SQL(NL2SQL)的研究和评估设计。该数据库包含虚构的国际汽车制造和销售公司 APEX 的财务数据,支持与公司运营、销售和财务绩效相关的各种分析查询。数据库主要覆盖中国、美国和欧洲市场,因此数据为双语(英文和中文),并使用三种货币(CNY、USD 和 EUR)。数据值为合成数据,但模式结构严格模拟真实企业财务数据库,确保对 NL2SQL 系统开发和评估的实用性。数据库包含 20 张表,总计约 9.015 亿行数据,时间跨度为 2020 年 1 月至 2025 年 12 月(72 个月)。数据格式支持 DuckDB(推荐)和 parquet(用于 HuggingFace)。数据库还包含丰富的实体统计信息,如区域、产品、客户、经销商等多层次维度。
创建时间:
2026-01-27
搜集汇总
数据集介绍
构建方式
在金融数据分析领域,RubikBench数据集通过模拟一家虚构的国际汽车制造与销售企业APEX的财务运营,构建了一个规模庞大的企业级财务数据库。该数据集以真实世界大型企业财务数据库为蓝本,精心设计了涵盖预算、收入、损益及销售分类账等20张数据表,总计超过9亿条记录。数据生成过程融合了多语言与多货币环境,包含中英文双语标签以及人民币、美元和欧元三种货币单位,时间跨度从2020年1月持续至2025年12月,按月粒度覆盖了72个完整周期。其结构设计紧密贴合实际企业财务系统的复杂模式,确保了数据在模式层面的高度真实性。
特点
RubikBench数据集展现出多维度、层次化的实体结构,涵盖了区域、产品、客户、经销商等多个业务维度,并具备精细的层级划分。数据规模达到约38GB的DuckDB格式或11GB的Parquet格式,体现了海量企业数据的典型特征。作为专为自然语言到SQL转换研究设计的基准,该数据集不仅提供了宽表模式和领域特定知识,还包含了多样化的度量指标与数据口径,能够有效模拟真实企业环境中遇到的查询复杂性。其双语支持和多货币场景进一步增强了数据集的实用价值与研究广度。
使用方法
研究人员可通过HuggingFace平台获取RubikBench的Parquet格式文件,并利用DuckDB等分析型数据库系统进行高效查询处理。数据集按预算表、收入表及大型分类账等类别进行了配置划分,用户可根据具体研究需求选择加载相应的数据子集。在自然语言到SQL的任务评估中,该数据集适用于测试模型对复杂企业财务查询的理解与生成能力,包括跨表关联、多条件筛选及聚合计算等典型场景。其提供的丰富实体层次与时间序列数据也为时序预测、财务分析等下游任务提供了坚实的基础。
背景与挑战
背景概述
在自然语言处理与数据库技术交叉领域,面向企业级复杂场景的自然语言到SQL转换研究长期面临高质量基准数据匮乏的困境。RubikBench数据集应运而生,由Magolor团队于2026年初创建并发布,旨在为自然语言到SQL研究提供一个企业级规模的金融数据库基准。该数据集模拟了一家虚构的国际汽车制造与销售公司APEX的财务运营,涵盖预算、收入、损益及销售分类账等多维度数据,时间跨度从2020年1月至2025年12月,包含约9亿条记录,并以双语形式呈现。其核心研究问题聚焦于如何在大规模、多语言、多货币的复杂企业财务数据库上,推动自然语言查询系统的实用化评估与性能突破,对金融科技与智能数据分析领域具有重要的基准参考价值。
当前挑战
RubikBench数据集所针对的自然语言到SQL转换任务,在金融领域面临多重挑战:企业财务数据库通常具有宽表结构、复杂的实体层次关系以及领域特定的业务逻辑,要求模型能够精准理解涉及多表连接、聚合计算及多维筛选的复杂查询意图。在数据集构建过程中,挑战主要体现在如何合成既符合真实企业数据库模式又保持逻辑一致性的海量数据,同时需平衡多语言文本、多货币单位以及跨区域业务规则的整合,确保生成的数据既能反映现实复杂性,又避免引入不合理的偏差或噪声,从而为模型评估提供可靠且具有区分度的测试环境。
常用场景
经典使用场景
在自然语言处理与数据库交互的交叉领域,RubikBench数据集以其企业级财务数据的复杂结构,为自然语言到SQL(NL2SQL)系统的研发与评估提供了经典场景。该数据集模拟了一家跨国汽车制造销售公司的财务运营,涵盖预算、收入、损益及销售分类账等多维度表格,其宽表架构、双语数据及多货币设定,精准复现了真实企业环境中NL2SQL任务所面临的挑战,如跨表关联、领域知识融合与多语言查询解析。
实际应用
在实际应用层面,RubikBench为金融科技与商业智能领域提供了宝贵的测试平台。企业可利用该数据集训练智能财务助手,实现通过自然语言直接查询销售趋势、预算执行或损益状况,大幅降低数据分析门槛。其双语特性尤其适用于跨国企业的多区域运营,支持中英文混合查询,助力开发适应全球化业务的自动化报表系统,提升决策效率与数据可访问性。
衍生相关工作
围绕RubikBench,学术界与工业界已衍生出一系列经典研究工作,主要集中在NL2SQL模型的架构创新与评估框架构建。例如,基于其复杂模式的研究推动了针对宽表与多表连接的专用模型设计,同时在多语言SQL生成、时序推理及领域适应等领域催生了新的评估基准。这些工作不仅深化了对企业级NL2SQL技术挑战的理解,也为后续大规模财务数据分析系统的标准化测评奠定了基础。
以上内容由遇见数据集搜集并总结生成


