【我遇到的问题】 • 现象:该数据集的下载链接已失效 【相关信息】 • 可考虑访问这个链接获取类似文件~https://www.selectdataset.com/dataset/3688356173feccbcf1f1e490ddc6bc72
HMDB51
收藏Papers with Code2024-05-15 收录
下载链接:
https://paperswithcode.com/dataset/hmdb51
下载链接
链接失效反馈官方服务:
资源简介:
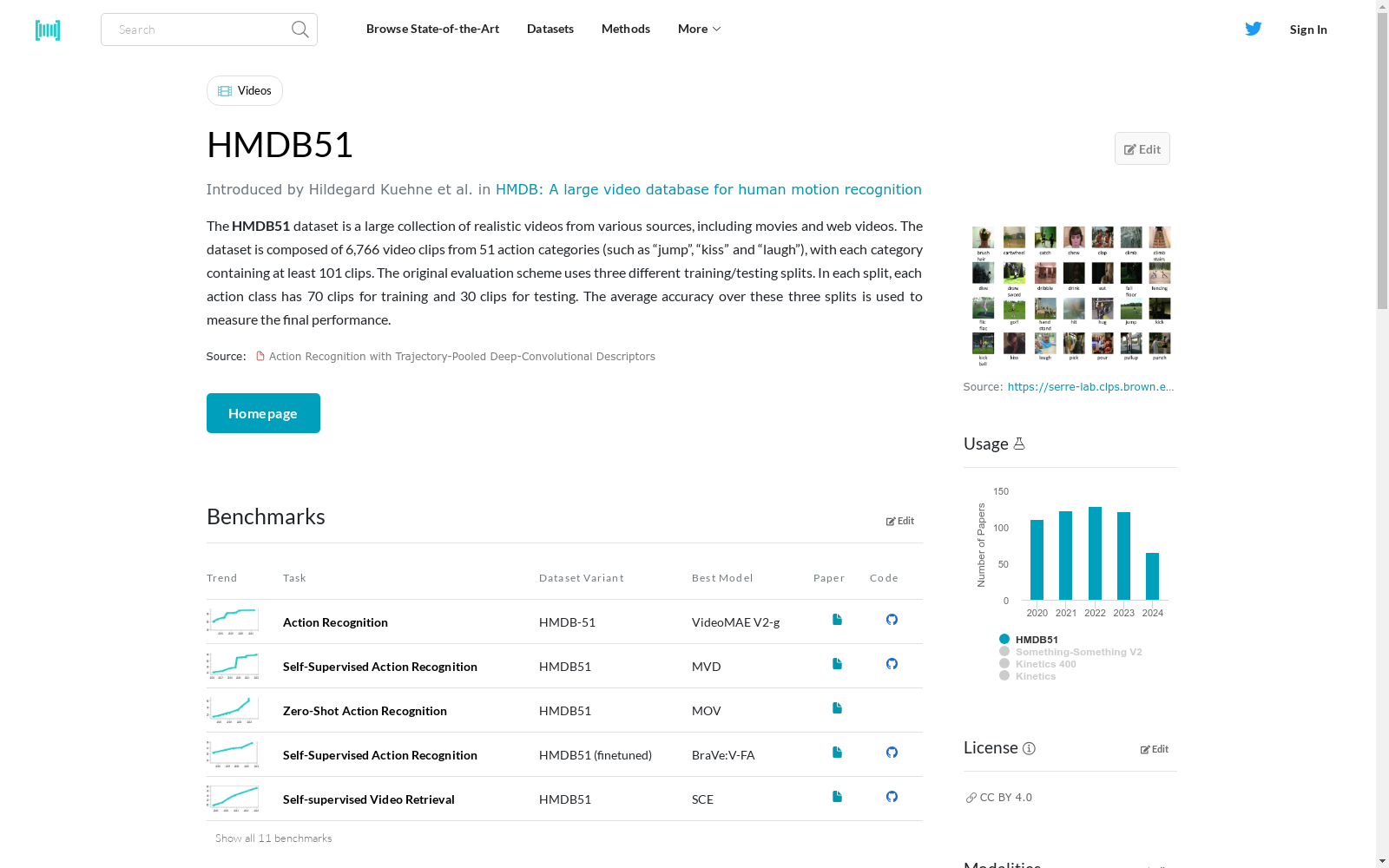
The HMDB51 dataset is a large collection of realistic videos from various sources, including movies and web videos. The dataset is composed of 6,766 video clips from 51 action categories (such as “jump”, “kiss” and “laugh”), with each category containing at least 101 clips. The original evaluation scheme uses three different training/testing splits. In each split, each action class has 70 clips for training and 30 clips for testing. The average accuracy over these three splits is used to measure the final performance.
HMDB51数据集(HMDB51 dataset)是一个收录多来源写实视频的大型合集,来源涵盖电影与网络视频。该数据集包含51个动作类别下的6766个视频片段,动作类别包括“跳跃”“亲吻”“大笑”等,每个类别至少包含101个片段。其原始评估方案采用三种不同的训练/测试划分,在每种划分中,每个动作类别的70个片段用于训练,剩余30个用于测试。最终模型性能通过这三种划分上的平均准确率进行评估。
搜集汇总
数据集介绍
构建方式
HMDB51数据集的构建基于对人类动作的广泛分类,涵盖了51种不同的动作类别。该数据集由来自各种来源的视频片段组成,包括电影和在线视频平台。每个视频片段经过精心标注,确保其动作类别的一致性和准确性。通过这种多源、多类别的构建方式,HMDB51为动作识别研究提供了丰富的数据资源。
使用方法
HMDB51数据集主要用于动作识别和视频分析领域的研究。研究人员可以通过该数据集训练和评估动作识别模型,探索不同算法在复杂场景下的表现。使用HMDB51时,通常需要将视频数据预处理为帧序列或特征向量,然后应用机器学习或深度学习方法进行模型训练。数据集的标注信息可用于监督学习,确保模型能够准确识别和分类各种动作。
背景与挑战
背景概述
HMDB51数据集,由Kuehne等人于2011年创建,是视频分析领域的重要资源。该数据集包含了51个动作类别,每个类别至少有101个视频片段,总计约7000个视频。HMDB51的构建旨在解决视频动作识别这一核心问题,为研究人员提供了一个标准化的基准,以评估和比较不同算法在动作识别任务中的性能。其影响力在于推动了视频分析技术的发展,尤其是在深度学习方法兴起后,HMDB51成为了验证模型有效性的重要工具。
当前挑战
HMDB51数据集在构建和应用过程中面临多项挑战。首先,视频数据的多样性和复杂性使得动作识别任务异常困难,尤其是在处理不同光照、视角和背景变化时。其次,数据集的标注工作量大,且需要高度专业化的知识,以确保标注的准确性和一致性。此外,随着技术的进步,HMDB51在处理高分辨率视频和实时分析方面的局限性也逐渐显现,这要求研究人员不断探索新的方法和模型以应对这些挑战。
发展历史
创建时间与更新
HMDB51数据集由Kuehne等人于2011年创建,旨在推动动作识别领域的发展。该数据集的最新版本于2011年发布,至今未有官方更新。
重要里程碑
HMDB51数据集的创建标志着动作识别领域的一个重要里程碑。它包含了51个动作类别,每个类别至少有100个视频片段,总计约7000个视频。这些视频来源于电影、公共视频数据库和YouTube,涵盖了广泛的人类动作,如跳跃、挥手和笑等。HMDB51的发布极大地推动了基于视频的动作识别研究,成为该领域的一个基准数据集,被广泛用于评估和比较不同的动作识别算法。
当前发展情况
尽管HMDB51自发布以来未有更新,但它仍然是动作识别领域的一个重要参考数据集。随着深度学习技术的快速发展,HMDB51在评估新型算法和模型方面依然具有重要价值。许多最新的研究论文和算法仍然使用HMDB51进行性能评估,证明了其在该领域的持久影响力。此外,HMDB51的成功也激励了更多大规模和多样化的动作识别数据集的创建,进一步推动了该领域的研究进展。
发展历程
- HMDB51数据集首次发表,由Hollywood Motion Picture Database项目团队创建,包含51种动作类别的视频片段。
- HMDB51数据集首次应用于视频动作识别研究,成为该领域的重要基准数据集之一。
- HMDB51数据集被广泛应用于深度学习模型的训练和评估,推动了视频理解技术的发展。
- HMDB51数据集的扩展版本HMDB51-2018发布,增加了新的视频片段和动作类别,进一步丰富了数据集的内容。
- HMDB51数据集在多个国际计算机视觉会议上被引用和讨论,持续影响着视频分析和理解的研究方向。
常用场景
经典使用场景
在计算机视觉领域,HMDB51数据集以其丰富的动作类别和高质量的视频片段而著称。该数据集广泛应用于动作识别任务中,研究人员利用其多样化的动作类别和复杂的背景变化,开发和验证各种动作识别算法。通过在HMDB51上的实验,学者们能够评估模型在不同动作和环境下的泛化能力和鲁棒性,从而推动动作识别技术的发展。
解决学术问题
HMDB51数据集在解决动作识别领域的学术研究问题中发挥了重要作用。它提供了丰富的动作类别和多样化的视频样本,帮助研究人员克服了动作识别中常见的挑战,如动作类别的多样性、背景复杂性和视角变化等。通过在HMDB51上的实验,学者们能够深入研究动作识别算法的性能和局限性,推动了该领域的理论和方法创新。
实际应用
HMDB51数据集在实际应用中具有广泛的价值。例如,在视频监控系统中,利用HMDB51训练的动作识别模型可以自动检测和分类监控视频中的各种动作,提高安全监控的效率和准确性。此外,在体育分析和医疗康复等领域,HMDB51数据集也为开发智能分析工具提供了重要的数据支持,帮助实现更精准的动作分析和评估。
数据集最近研究
最新研究方向
在动作识别领域,HMDB51数据集作为经典基准,近期研究聚焦于提升模型对复杂动作的识别精度。研究者们通过引入多模态融合技术,结合视频帧与音频信息,显著增强了模型对动作细节的捕捉能力。此外,基于注意力机制的深度学习模型在该数据集上的应用也取得了显著进展,有效提升了对长尾动作的识别效果。这些前沿研究不仅推动了动作识别技术的发展,也为智能监控、人机交互等应用场景提供了更为精准的技术支持。
相关研究论文
- 1HMDB: A Large Video Database for Human Motion RecognitionUniversity of Texas at Austin · 2011年
- 2Temporal Segment Networks: Towards Good Practices for Deep Action RecognitionUniversity of Oxford · 2016年
- 3Two-Stream Inflated 3D ConvNet for Human Action RecognitionDeepMind · 2018年
- 4A Closer Look at Spatiotemporal Convolutions for Action RecognitionFacebook AI Research · 2018年
- 5SlowFast Networks for Video RecognitionFacebook AI Research · 2019年
以上内容由遇见数据集搜集并总结生成


