Hello-SimpleAI/HC3
收藏Hugging Face2023-01-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Hello-SimpleAI/HC3
下载链接
链接失效反馈资源简介:
---
task_categories:
- text-classification
- question-answering
- sentence-similarity
- zero-shot-classification
language:
- en
- zh
tags:
- ChatGPT
- SimpleAI
- Detection
- OOD
size_categories:
- 10K<n<100K
license: cc-by-sa-4.0
---
# Human ChatGPT Comparison Corpus (HC3)
We propose the first human-ChatGPT comparison corpus, named **HC3** dataset.
This dataset is introduced in our paper:
- Paper: [***How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection***](https://arxiv.org/abs/2301.07597)
Code, models and analysis are available on our GitHub:
- GitHub: [**Chatgpt-Comparison-Detection project** 🔬](https://github.com/Hello-SimpleAI/chatgpt-comparison-detection)
# Dataset Copyright
If the source datasets used in this corpus has a specific license which is stricter than CC-BY-SA, our products follow the same. If not, they follow CC-BY-SA license.
See [dataset copyright](https://github.com/Hello-SimpleAI/chatgpt-comparison-detection#dataset-copyright).
# Citation
Checkout this papaer [arxiv: 2301.07597](https://arxiv.org/abs/2301.07597)
```
@article{guo-etal-2023-hc3,
title = "How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection",
author = "Guo, Biyang and
Zhang, Xin and
Wang, Ziyuan and
Jiang, Minqi and
Nie, Jinran and
Ding, Yuxuan and
Yue, Jianwei and
Wu, Yupeng",
journal={arXiv preprint arxiv:2301.07597}
year = "2023",
}
```
任务类别:
- 文本分类(text-classification)
- 问答(question-answering)
- 句子相似度(sentence-similarity)
- 零样本分类(zero-shot-classification)
语言:
- 英语
- 汉语
标签:
- ChatGPT
- SimpleAI
- 检测(Detection)
- 分布外(Out-of-Distribution, OOD)
样本规模:
- 1万 < 样本数量 < 10万
许可证:CC-BY-SA-4.0
# 人类与ChatGPT对比语料库(HC3)
我们提出了首个人类与ChatGPT的对比语料库,命名为HC3数据集。
该数据集的相关细节可参见我们的论文:
- 论文:[***ChatGPT与人类专家的差距有多近?对比语料库、评估与检测方法***](https://arxiv.org/abs/2301.07597)
代码、模型与分析内容可在我们的GitHub仓库获取:
- GitHub:[**ChatGPT对比检测项目🔬**](https://github.com/Hello-SimpleAI/chatgpt-comparison-detection)
# 数据集版权声明
若本语料库所使用的源数据集存在比CC-BY-SA更严格的专有许可证,则本产品遵循该更严格的许可证条款;否则遵循CC-BY-SA许可证。
详见[数据集版权说明](https://github.com/Hello-SimpleAI/chatgpt-comparison-detection#dataset-copyright)。
# 引用方式
请引用此论文[arxiv: 2301.07597](https://arxiv.org/abs/2301.07597):
@article{guo-etal-2023-hc3,
title = "How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection",
author = "Guo, Biyang and
Zhang, Xin and
Wang, Ziyuan and
Jiang, Minqi and
Nie, Jinran and
Ding, Yuxuan and
Yue, Jianwei and
Wu, Yupeng",
journal={arXiv preprint arxiv:2301.07597}
year = "2023",
}
提供机构:
Hello-SimpleAI
原始信息汇总
数据集概述
数据集名称
- Human ChatGPT Comparison Corpus (HC3)
数据集任务类别
- 文本分类
- 问答
- 句子相似度
- 零样本分类
支持语言
- 英语
- 中文
标签
- ChatGPT
- SimpleAI
- 检测
- OOD
数据集大小
- 10K<n<100K
许可证
- CC-BY-SA-4.0
数据集版权
- 如果源数据集的许可证比CC-BY-SA更严格,则遵循源数据集的许可证;否则,遵循CC-BY-SA许可证。
引用信息
- 论文标题:How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection
- 作者:Guo, Biyang 等
- 年份:2023
- 预印本链接:arXiv:2301.07597
搜集汇总
数据集介绍
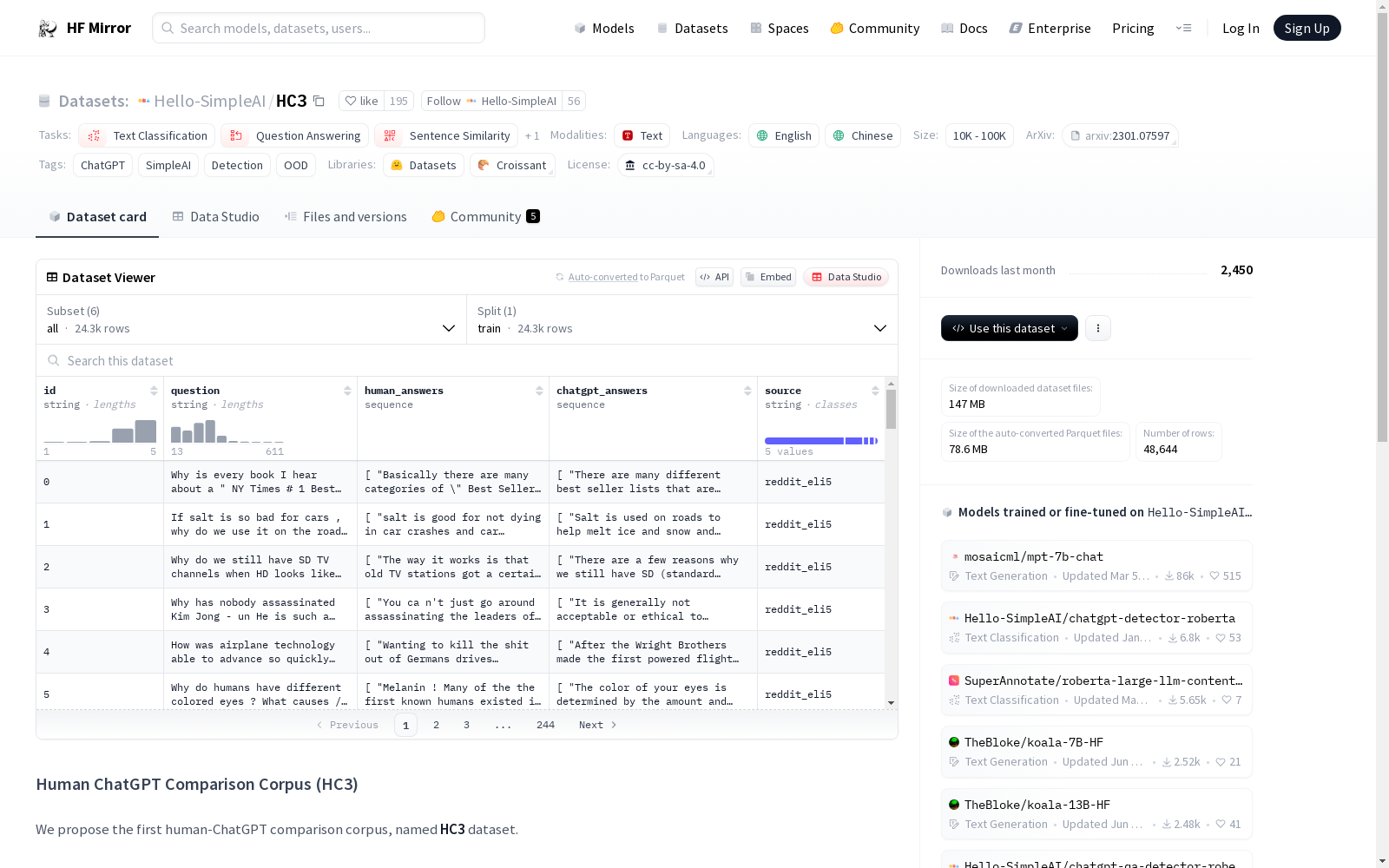
构建方式
HC3数据集的构建旨在创建一个可供比较人类专家与ChatGPT性能的语料库。该数据集通过精心挑选和设计,涵盖了文本分类、问题回答、句子相似度和零样本分类等多个任务类别,其中语言涵盖了英文和中文。构建过程中,数据集严格遵循了相应的版权法规,确保了数据使用的合法性和合规性。
特点
HC3数据集的特点在于其独特的人类与人工智能对比分析设计,提供了10K至100K规模的数据量,足以支持多种自然语言处理任务的研究。数据集的标签包含了ChatGPT、SimpleAI、检测和OOD等,这些标签有助于研究人员快速定位到数据集的特定用途。此外,数据集遵循CC-BY-SA 4.0协议,保证了数据的开放性和共享性。
使用方法
使用HC3数据集,研究者可以依据数据集中的任务类别和语言进行相应的自然语言处理研究。数据集的获取和引用需遵循其开放版权协议,同时建议用户在研究和论文中引用相关论文,以完整展现数据集的学术背景和研究价值。具体使用时,用户可通过数据集提供的GitHub链接获取代码、模型和分析结果,以便更深入地进行研究和应用。
背景与挑战
背景概述
在人工智能领域的自然语言处理任务中,评估机器生成文本与人类专家水平的接近程度是一项关键的研究课题。为此,Hello-SimpleAI团队于2023年提出了HC3数据集,该数据集是人类与ChatGPT对话输出的比较语料库。HC3的构建旨在为文本分类、问题回答、句子相似度以及零样本分类等任务提供评价标准,其语言覆盖英文和中文。该数据集的推出,对于理解高级对话系统的性能,以及促进自然语言生成技术的进步具有显著影响。
当前挑战
HC3数据集在构建过程中面临着多重挑战。首先,确保数据质量与一致性是一项艰巨的任务,因为需要精确地区分人类与机器生成的文本。其次,数据集的规模与多样性对于模型的泛化能力至关重要,而在此规模下的数据收集与标注工作极具挑战。此外,构建有效的评价体系来量化机器与人类专家之间的差异,也是HC3数据集需要解决的关键问题。
常用场景
经典使用场景
在自然语言处理领域,HC3数据集以其独特的设计理念成为研究的热点。该数据集主要用于文本分类、问题回答、句子相似性以及零样本分类等任务。其经典使用场景在于,通过对ChatGPT生成文本与人类专家回答的比较,评估模型的表现,进而提升自然语言生成模型的准确性、流畅性和逻辑性。
实际应用
在实用层面,HC3数据集的应用场景广泛,不仅能够用于训练和评估聊天机器人、智能客服等AI应用,还可以在内容审核、情感分析等领域发挥作用,提高相关系统的智能化水平和服务质量。
衍生相关工作
HC3数据集的推出,激发了学术界对人工智能生成内容与人类创作差异性的深入探讨,衍生出了一系列相关研究。这些研究涉及模型的可解释性、生成文本的多样性以及人工智能伦理等方面,为人工智能领域的发展提供了新的研究方向和思考视角。
以上内容由遇见数据集搜集并总结生成


