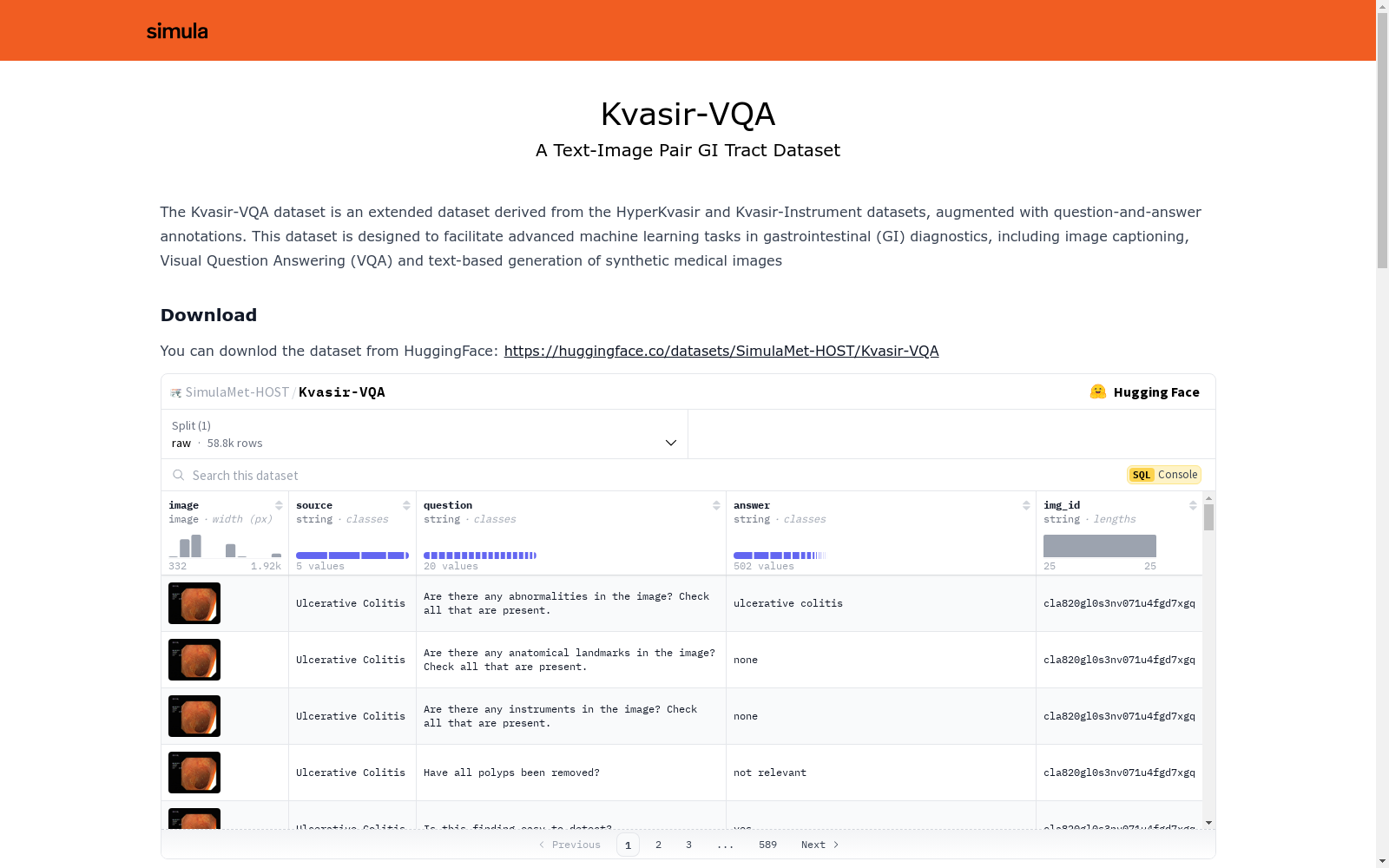
有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
中国交通事故深度调查(CIDAS)数据集
交通事故深度调查数据通过采用科学系统方法现场调查中国道路上实际发生交通事故相关的道路环境、道路交通行为、车辆损坏、人员损伤信息,以探究碰撞事故中车损和人伤机理。目前已积累深度调查事故10000余例,单个案例信息包含人、车 、路和环境多维信息组成的3000多个字段。该数据集可作为深入分析中国道路交通事故工况特征,探索事故预防和损伤防护措施的关键数据源,为制定汽车安全法规和标准、完善汽车测评试验规程、
北方大数据交易中心 收录
UniProt
UniProt(Universal Protein Resource)是全球公认的蛋白质序列与功能信息权威数据库,由欧洲生物信息学研究所(EBI)、瑞士生物信息学研究所(SIB)和美国蛋白质信息资源中心(PIR)联合运营。该数据库以其广度和深度兼备的蛋白质信息资源闻名,整合了实验验证的高质量数据与大规模预测的自动注释内容,涵盖从分子序列、结构到功能的全面信息。UniProt核心包括注释详尽的UniProtKB知识库(分为人工校验的Swiss-Prot和自动生成的TrEMBL),以及支持高效序列聚类分析的UniRef和全局蛋白质序列归档的UniParc。其卓越的数据质量和多样化的检索工具,为基础研究和药物研发提供了无可替代的支持,成为生物学研究中不可或缺的资源。
www.uniprot.org 收录
OpenSonarDatasets
OpenSonarDatasets是一个致力于整合开放源代码声纳数据集的仓库,旨在为水下研究和开发提供便利。该仓库鼓励研究人员扩展当前的数据集集合,以增加开放源代码声纳数据集的可见性,并提供一个更容易查找和比较数据集的方式。
github 收录
网易云音乐数据集
该数据集包含了网易云音乐平台上的歌手信息、歌曲信息和歌单信息,数据通过爬虫技术获取并整理成CSV格式,用于音乐数据挖掘和推荐系统构建。
github 收录
Wind Turbine Data
该数据集包含风力涡轮机的运行数据,包括风速、风向、发电量等参数。数据记录了多个风力涡轮机在不同时间点的运行状态,适用于风能研究和风力发电系统的优化分析。
www.kaggle.com 收录