smoltalk-ko-translate
收藏Hugging Face2024-12-18 更新2024-12-19 收录
下载链接:
https://huggingface.co/datasets/youjunhyeok/smoltalk-ko-translate
下载链接
链接失效反馈官方服务:
资源简介:
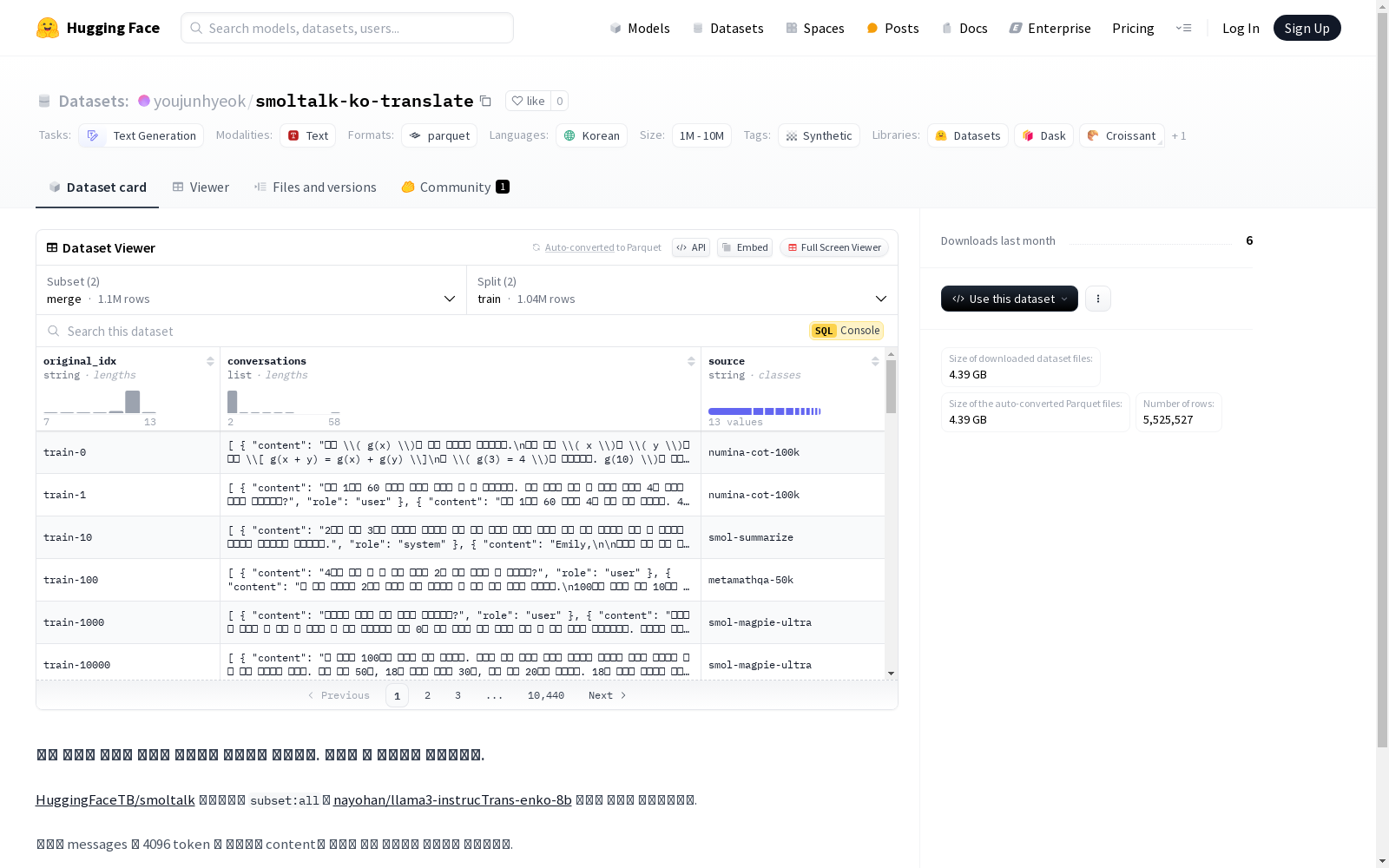
该数据集包含两个配置:'merge'和'split'。'merge'配置包含对话数据,每个对话有原始索引、内容和角色信息,以及数据来源。'split'配置则进一步细分了对话数据,增加了对话索引。数据集分为训练集和测试集,分别包含大量样本。数据集的语言为韩语,标签为'synthetic',大小在1M到10M之间。数据集用于文本生成任务。
创建时间:
2024-12-18
原始信息汇总
数据集概述
数据集信息
配置 merge
- 特征:
original_idx: 类型为stringconversations: 列表类型,包含以下字段:content: 类型为stringrole: 类型为string
source: 类型为string
- 分割:
train: 包含 1,043,917 个样本,大小为 4,496,569,309 字节test: 包含 54,948 个样本,大小为 236,450,018 字节
- 下载大小: 2,189,165,000 字节
- 数据集大小: 4,733,019,327 字节
配置 split
- 特征:
original_idx: 类型为stringconversation_idx: 类型为stringcontent: 类型为stringrole: 类型为stringsource: 类型为string
- 分割:
train: 包含 4,205,413 个样本,大小为 4,652,568,891 字节test: 包含 221,249 个样本,大小为 244,079,529 字节
- 下载大小: 2,201,252,839 字节
- 数据集大小: 4,896,648,420 字节
数据文件
- 配置
merge:train:merge/train-*test:merge/test-*
- 配置
split:train:split/train-*test:split/test-*
任务类别
- 文本生成
语言
- 韩语 (
ko)
标签
- 合成数据 (
synthetic)
数据集大小类别
- 1M < n < 10M
搜集汇总
数据集介绍
构建方式
smoltalk-ko-translate数据集的构建基于HuggingFaceTB/smoltalk数据集的`subset:all`,通过使用nayohan/llama3-instrucTrans-enko-8b模型进行翻译生成。在构建过程中,原始数据集中的消息内容若超过4096个token,则该记录未被翻译,以确保翻译质量和数据集的完整性。
特点
该数据集的主要特点在于其翻译后的内容包含了韩语(ko)语言,适用于韩语文本生成任务。数据集分为两个配置:`merge`和`split`,分别对应不同的数据结构和分割方式。此外,数据集的规模较大,训练集包含超过400万条样本,测试集也有数十万条样本,适合大规模的文本生成模型训练与评估。
使用方法
smoltalk-ko-translate数据集可用于韩语文本生成任务,用户可以通过HuggingFace的datasets库加载该数据集。数据集提供了两种配置,用户可根据需求选择适合的配置进行加载。加载后,用户可以利用数据集中的对话内容进行模型训练或评估,尤其适用于需要处理韩语对话数据的自然语言处理任务。
背景与挑战
背景概述
smoltalk-ko-translate数据集是基于HuggingFaceTB/smoltalk数据集的子集,通过nayohan/llama3-instrucTrans-enko-8b模型进行韩语到英语的翻译。该数据集的创建旨在为文本生成任务提供高质量的多语言对话数据,尤其是在处理长文本内容时,确保翻译的准确性和连贯性。其核心研究问题是如何在多语言环境中保持对话的自然流畅性,同时避免翻译过程中出现的重复或冗余现象。该数据集的发布对多语言对话生成领域具有重要意义,尤其是在跨语言对话模型的训练和评估方面。
当前挑战
smoltalk-ko-translate数据集在构建过程中面临的主要挑战包括:首先,如何有效处理超过4096个token的长文本内容,确保这些内容在翻译过程中不被遗漏或截断。其次,翻译过程中出现的重复或冗余现象,这不仅影响数据集的质量,还可能对后续模型的训练产生负面影响。此外,如何在保持翻译准确性的同时,确保对话的连贯性和自然性,也是该数据集面临的重要挑战。这些问题的解决对于提升多语言对话生成模型的性能至关重要。
常用场景
经典使用场景
smoltalk-ko-translate数据集在自然语言处理领域中,主要用于支持韩语到其他语言的机器翻译任务。其经典使用场景包括构建和评估翻译模型,特别是在处理对话内容时,能够有效捕捉语言间的细微差异和语境依赖性。通过该数据集,研究者可以训练出更加精准和流畅的翻译模型,提升跨语言沟通的效率。
解决学术问题
该数据集解决了机器翻译领域中常见的学术问题,如长文本翻译中的信息丢失、语境理解不足以及语言间的文化差异处理。通过提供高质量的韩语对话翻译数据,研究者能够更好地训练模型,使其在处理复杂语境和多轮对话时表现更为出色,从而推动机器翻译技术的进步。
衍生相关工作
基于smoltalk-ko-translate数据集,研究者们开发了多种先进的翻译模型和算法,如基于Transformer的翻译架构优化、多语言模型融合技术等。这些工作不仅提升了翻译质量,还为跨语言信息处理领域提供了新的研究方向和方法论,推动了相关技术的快速发展。
以上内容由遇见数据集搜集并总结生成


