MUSCIMA++
收藏arXiv2017-03-15 更新2024-06-21 收录
下载链接:
https://ufal.mff.cuni.cz/muscima
下载链接
链接失效反馈官方服务:
资源简介:
MUSCIMA++是由查尔斯大学数学与物理学院形式与应用语言学研究所创建的一个手写音乐符号数据集,包含140页手写音乐,共计91255个手动标注的音乐符号和82261个符号对之间的明确关系。该数据集支持训练和评估符号分类、符号定位和音乐图谱组装模型,适用于单独和联合任务。数据集提供了开源工具,用于数据处理、可视化和进一步标注,适用于音乐符号识别和音乐图谱重建的研究。
MUSCIMA++ is a handwritten musical notation dataset created by the Institute of Formal and Applied Linguistics, Faculty of Mathematics and Physics, Charles University. It contains 140 pages of handwritten music, with a total of 91,255 manually annotated musical symbols and 82,261 explicit relationships between symbol pairs. This dataset supports the training and evaluation of models for symbol classification, symbol localization, and music score assembly, applicable to both individual and joint tasks. The dataset provides open-source tools for data processing, visualization and further annotation, which are suitable for research on musical symbol recognition and music score reconstruction.
提供机构:
查尔斯大学数学与物理学院形式与应用语言学研究所
创建时间:
2017-03-15
搜集汇总
数据集介绍
构建方式
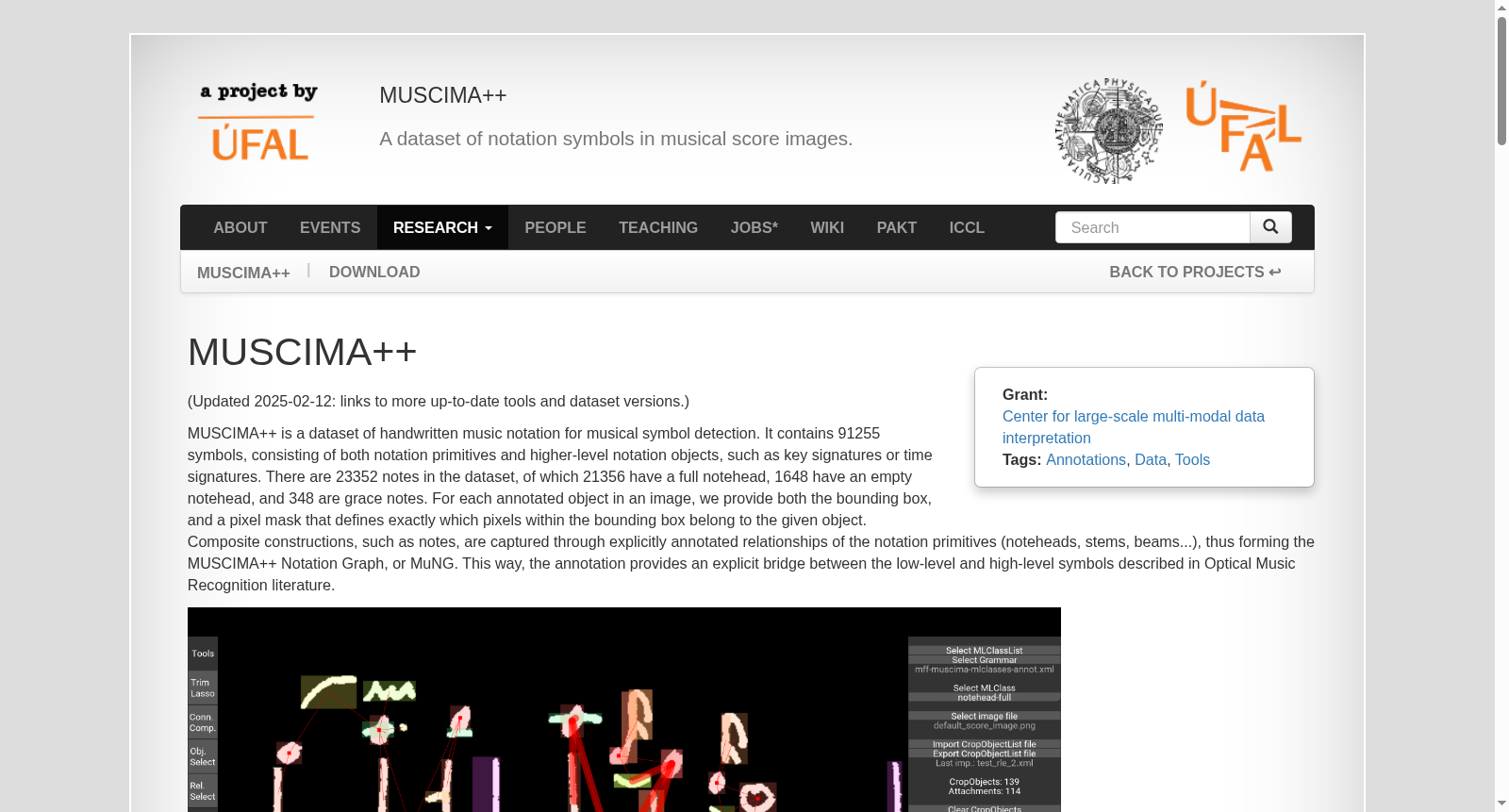
在光学音乐识别领域长期缺乏标准化评估数据的背景下,MUSCIMA++数据集通过系统化的标注流程构建而成。该数据集以CVC-MUSCIMA手写乐谱图像为基础,从中精选140页涵盖不同书写风格与音乐复杂度的样本。采用分层标注策略,由七位具备音乐背景的标注者使用定制化工具MUSCIMarker进行人工标注,历经多轮质量控制与交叉验证。标注过程不仅记录音符、谱号等符号的边界框与像素掩码,更通过有向无环图结构显式标注符号间的逻辑关系,最终形成包含91255个符号标注与82261组符号关系的结构化数据集。
特点
MUSCIMA++数据集的核心特征在于其多层次、结构化的标注体系。区别于传统仅关注符号分类的数据集,该数据集通过图结构建模符号间语义关系,为音乐符号识别与乐谱重建任务提供连贯的评估基准。数据覆盖单声部至钢琴谱等多种音乐复杂度层级,并包含50位书写者各异的笔迹风格,有效反映了手写乐谱的拓扑变异特性。标注符号集包含107个类别,既涵盖音符、符干等基础图元,也集成调号、连音线等复合符号,同时提供像素级掩码标注以精确刻画符号形状。这种设计使得数据集能同时支持符号分类、定位及乐谱图重建等任务的独立或联合评估。
使用方法
使用MUSCIMA++数据集时,研究者可根据任务需求灵活提取不同层级的标注信息。对于符号分类任务,可直接利用符号边界框与类别标签;符号定位任务则可基于整页图像与标注位置进行训练与评估。在乐谱重建任务中,数据集提供的图结构关系可用于训练符号关系推断模型,其有向边连接可转化为邻接矩阵作为监督信号。数据集同时提供用户独立与用户依赖两种测试集划分方案,便于评估模型对新书写者的泛化能力。配套的muscima工具包支持数据解析与可视化,研究者可进一步基于标注关系推导音符时值与音高信息,实现从图形符号到音乐语义的完整分析流程。
背景与挑战
背景概述
MUSCIMA++数据集由查尔斯大学形式与应用语言学研究所的Jan Hajič jr.与Pavel Pecina等人于2017年创建,旨在解决手写光学音乐识别领域长期缺乏高质量标注数据的问题。该数据集聚焦于音乐符号识别与乐谱重建,包含140页手写乐谱图像,涵盖91255个手动标注的音乐符号及82261个符号间关系,为符号分类、定位及乐谱图构建等任务提供了系统评估基准。其构建基于CVC-MUSCIMA数据集,通过精细的标注策略与开源工具支持,显著推动了OMR领域从符号级到语义级研究的进展,为机器学习方法的应用奠定了数据基础。
当前挑战
MUSCIMA++数据集致力于解决手写光学音乐识别中符号识别与乐谱重建的核心挑战,包括音乐符号的图形复杂性、手写变异性及多声部乐谱的结构解析。在构建过程中,面临标注成本高昂、符号边界模糊、关系定义歧义等难题,需通过多层标注策略平衡信息完整性与标注效率。此外,数据集的扩展需克服早期乐谱手写风格差异、标注一致性维护以及自动标注工具开发等障碍,以提升其在历史文档分析与多任务联合评估中的适用性。
常用场景
经典使用场景
在光学音乐识别领域,MUSCIMA++数据集为手写乐谱符号的识别与重建提供了基准测试平台。该数据集通过精细标注的91255个音乐符号及82261个符号间关系,构建了从图像到符号图结构的完整标注链条。研究者可基于此数据集训练和评估符号分类、定位及乐谱图组装等任务,尤其适用于探索手写乐谱中因笔迹变异和符号重叠带来的识别挑战。其多层级标注体系支持从低层图形元素到高层语义结构的渐进式研究,为OMR系统各阶段性能的独立或联合评估奠定基础。
解决学术问题
MUSCIMA++有效解决了光学音乐识别领域长期缺乏标准化评估数据集的学术困境。该数据集通过定义符号词汇表与关系图结构,为符号识别、乐谱重建等核心任务提供可量化的评估基准。其标注体系覆盖了从图形符号到音乐语义的完整映射,使得研究者能够系统评估不同算法在符号分类准确率、定位精度及结构重建完整性等维度的性能。该数据集的开放共享打破了以往研究因数据缺失难以横向比较的壁垒,为建立领域内统一评估标准提供了关键基础设施。
衍生相关工作
围绕MUSCIMA++数据集已衍生出多项经典研究工作。在符号识别方向,研究者基于其标注数据开发了融合卷积神经网络与图神经网络的混合模型,显著提升了复杂笔迹下的符号分类精度。在端到端识别领域,有团队借鉴其图结构标注提出了乐谱图生成网络,实现了从图像到结构化乐谱的直接映射。此外,该数据集还催生了针对历史乐谱的跨时代风格适应研究,通过域适应技术将模型迁移至早期音乐手稿的识别任务,拓展了OMR技术的应用边界。
以上内容由遇见数据集搜集并总结生成


