有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
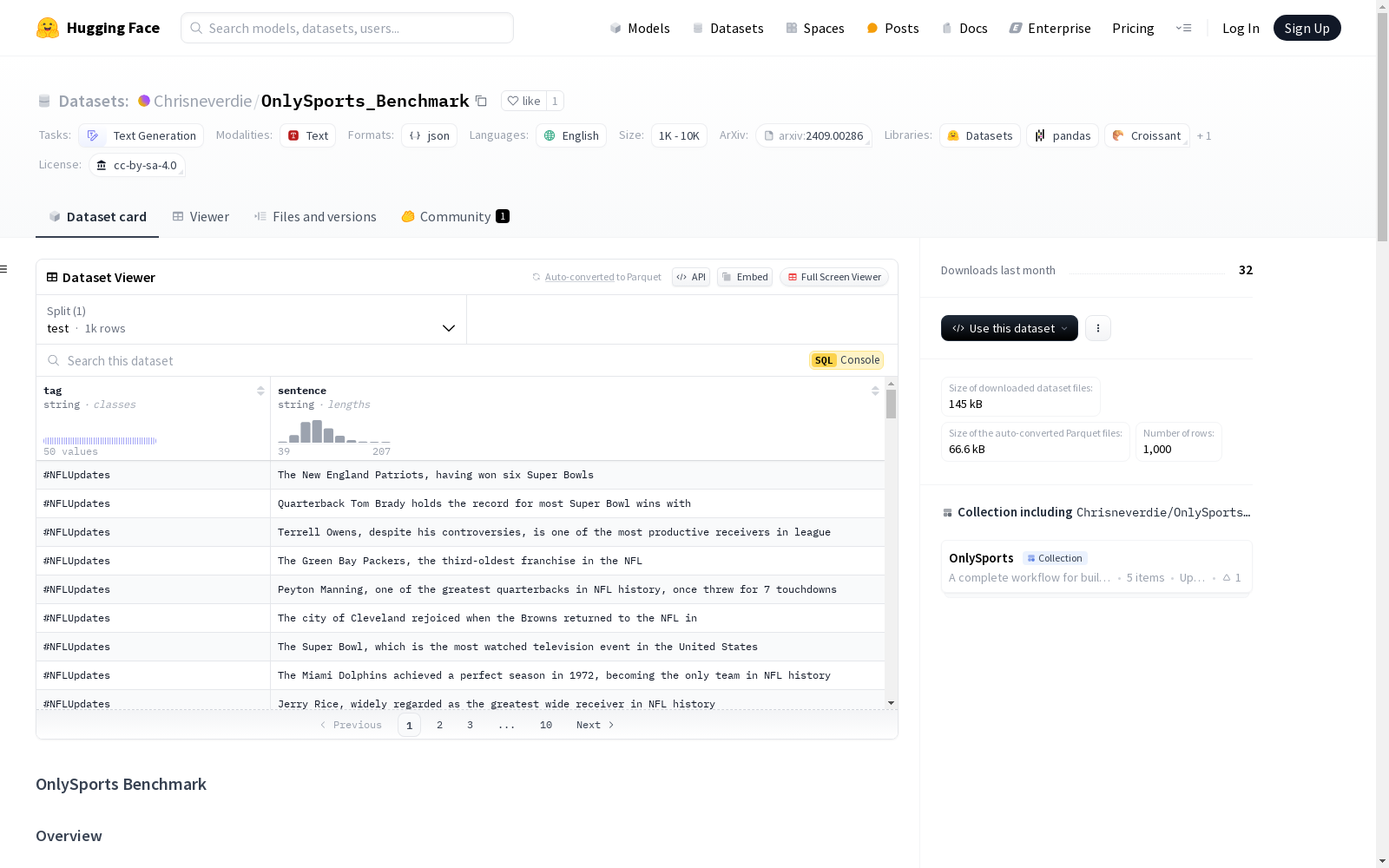
OnlySports Benchmark 是一种新颖的评估方法,旨在评估语言模型在体育知识生成方面的能力。它是 OnlySports 项目的一部分,旨在推进体育领域特定语言建模。
提示生成
评估标准
评估过程
详细结果请参阅我们的 论文 中的附录。
如果您在研究中使用 OnlySports Benchmark,请引用我们的 论文。
更多信息或关于 OnlySports Benchmark 的咨询,请访问我们的 GitHub 仓库。
poi
本项目收集国内POI兴趣点,当前版本数据来自于openstreetmap。
github 收录
MultiTalk
MultiTalk数据集是由韩国科学技术院创建,包含超过420小时的2D视频,涵盖20种不同语言,旨在解决多语言环境下3D说话头生成的问题。该数据集通过自动化管道从YouTube收集,每段视频都配有语言标签和伪转录,部分视频还包含伪3D网格顶点。数据集的创建过程包括视频收集、主动说话者验证和正面人脸验证,确保数据质量。MultiTalk数据集的应用领域主要集中在提升多语言3D说话头生成的准确性和表现力,通过引入语言特定风格嵌入,使模型能够捕捉每种语言独特的嘴部运动。
arXiv 收录
中国区域交通网络数据集
该数据集包含中国各区域的交通网络信息,包括道路、铁路、航空和水路等多种交通方式的网络结构和连接关系。数据集详细记录了各交通节点的位置、交通线路的类型、长度、容量以及相关的交通流量信息。
data.stats.gov.cn 收录
DALY
DALY数据集包含了全球疾病负担研究(Global Burden of Disease Study)中的伤残调整生命年(Disability-Adjusted Life Years, DALYs)数据。该数据集提供了不同国家和地区在不同年份的DALYs指标,用于衡量因疾病、伤害和早逝导致的健康损失。
ghdx.healthdata.org 收录
glaive-function-calling-openai
该数据集包含用于训练和评估语言模型在函数调用能力上的对话示例。数据集包括一个完整的函数调用示例集合和一个精选的子集,专注于最常用的函数。数据集的结构包括一个完整的数据集和几个测试子集。每个记录都是一个JSON对象,包含对话消息、可用函数定义和实际的函数调用。数据集还包括最常用的函数分布信息,并提供了加载和评估数据集的示例代码。
huggingface 收录