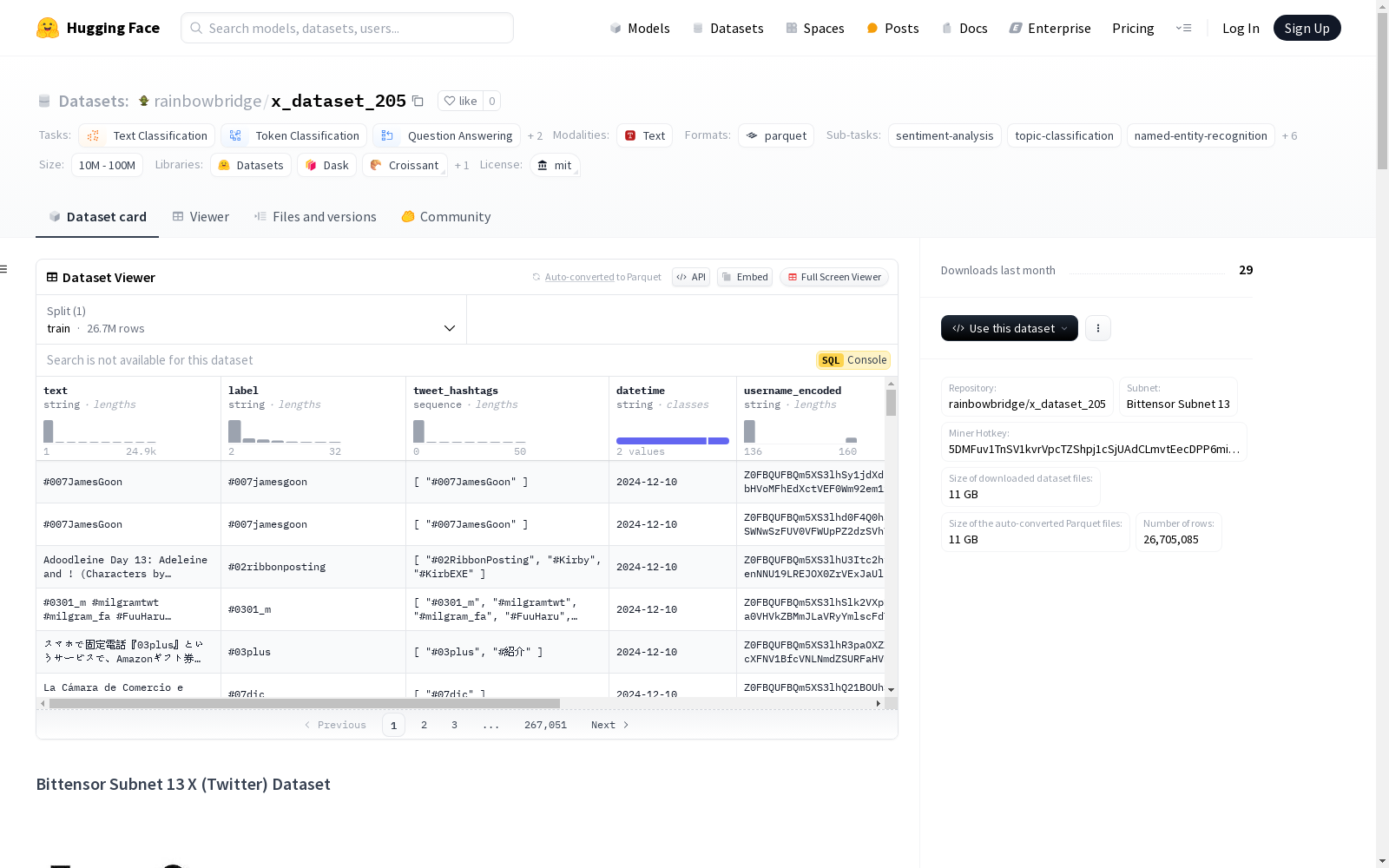
x_dataset_205
收藏Bittensor Subnet 13 X (Twitter) Dataset
数据集描述
- 仓库: rainbowbridge/x_dataset_205
- 子网: Bittensor Subnet 13
- 矿工热键: 5DMFuv1TnSV1kvrVpcTZShpj1cSjUAdCLmvtEecDPP6mi9dp
数据集概述
该数据集是Bittensor Subnet 13去中心化网络的一部分,包含从X(原Twitter)预处理的数据。数据由网络矿工持续更新,提供实时推文流,适用于各种分析和机器学习任务。
支持的任务
该数据集的多功能性允许研究人员和数据科学家探索社交媒体动态的各个方面,并开发创新应用。用户可以利用这些数据进行以下任务:
- 情感分析
- 趋势检测
- 内容分析
- 用户行为建模
语言
主要语言:数据集大多为英语,但由于去中心化的创建方式,可能包含多语言内容。
数据集结构
数据实例
每个实例代表一条推文,包含以下字段:
数据字段
text(字符串): 推文的主要内容。label(字符串): 推文的情感或主题类别。tweet_hashtags(列表): 推文中使用的标签列表。如果没有标签,则为空。datetime(字符串): 推文的发布日期。username_encoded(字符串): 用户名的编码版本,以保护用户隐私。url_encoded(字符串): 推文中包含的URL的编码版本。如果没有URL,则为空。
数据分割
该数据集持续更新,没有固定的分割。用户应根据其需求和数据的时间戳创建自己的分割。
数据集创建
源数据
数据收集自X(Twitter)上的公开推文,遵守平台的条款服务和API使用指南。
个人和敏感信息
所有用户名和URL均已编码以保护用户隐私。数据集不包含故意包含的个人或敏感信息。
使用数据的注意事项
社会影响和偏见
用户应注意X(Twitter)数据中固有的潜在偏见,包括人口统计和内容偏见。该数据集反映了X上表达的内容和意见,不应被视为一般人口的代表性样本。
限制
- 由于数据收集和预处理的去中心化性质,数据质量可能有所不同。
- 数据集可能包含噪音、垃圾邮件或与社交媒体平台相关的无关内容。
- 由于实时收集方法,可能存在时间偏差。
- 数据集仅限于公开推文,不包括私人账户或直接消息。
- 并非所有推文都包含标签或URL。
附加信息
许可信息
该数据集在MIT许可下发布。使用此数据集还需遵守X的使用条款。
引用信息
如果您在研究中使用此数据集,请按如下方式引用:
@misc{rainbowbridge2024datauniversex_dataset_205, title={The Data Universe Datasets: The finest collection of social media data the web has to offer}, author={rainbowbridge}, year={2024}, url={https://huggingface.co/datasets/rainbowbridge/x_dataset_205}, }
贡献
如需报告问题或为数据集做出贡献,请联系矿工或使用Bittensor Subnet 13的治理机制。
数据集统计
- 总实例数: 27854670
- 日期范围: 2024-12-10T00:00:00Z 至 2024-12-14T00:00:00Z
- 最后更新: 2024-12-14T12:57:56Z
数据分布
- 带标签的推文: 37.92%
- 不带标签的推文: 62.08%
前10个标签
| 排名 | 主题 | 总数 | 百分比 |
|---|---|---|---|
| 1 | NULL | 16141683 | 60.44% |
| 2 | #tiktok | 96915 | 0.36% |
| 3 | #riyadh | 94080 | 0.35% |
| 4 | #ad | 64648 | 0.24% |
| 5 | #theheartkillersep4 | 62423 | 0.23% |
| 6 | #كاس_العالم_2034 | 51620 | 0.19% |
| 7 | #冬もピッコマでポイ活 | 44678 | 0.17% |
| 8 | #モンスト | 37304 | 0.14% |
| 9 | #แจกจริง | 36829 | 0.14% |
| 10 | #apma2024 | 33509 | 0.13% |
更新历史
| 日期 | 新增实例 | 总实例数 |
|---|---|---|
| 2024-12-11T00:07:59Z | 1149585 | 1149585 |
| 2024-12-11T00:08:28Z | 1304134 | 2453719 |
| 2024-12-14T12:57:56Z | 25400951 | 27854670 |