SynCD
收藏github2025-02-06 更新2025-02-10 收录
下载链接:
https://github.com/nupurkmr9/syncd
下载链接
链接失效反馈官方服务:
资源简介:
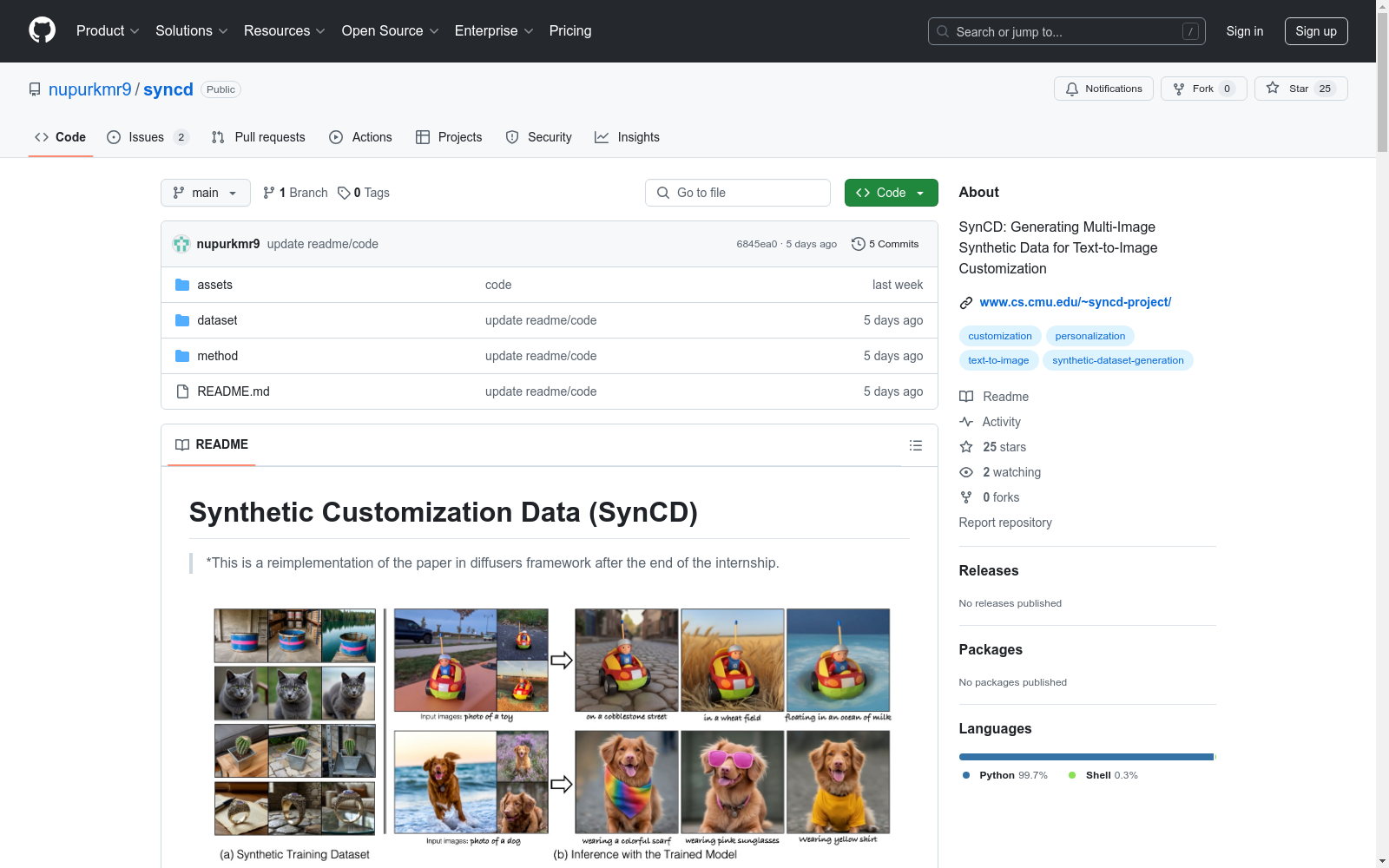
该数据集是针对可变形类别和刚性对象类别生成的多图像合成数据,使用描述性提示和遮罩共享注意力(MSA)在图像的前景对象区域之间促进视觉一致性。对于刚性对象类别,还额外使用深度和跨视图扭曲以及现有的Objaverse资产来确保三维多视角一致性。使用DINOv2和美学分数过滤出低质量图像,以创建最终的训练数据集。
This dataset is multi-image synthetic data generated for deformable and rigid object categories. Descriptive prompts and Masked Shared Attention (MSA) are utilized to foster visual consistency across foreground object regions within images. For rigid object categories, depth information, cross-view warping and existing Objaverse assets are additionally adopted to guarantee 3D multi-view consistency. Low-quality images are filtered out using DINOv2 and aesthetic scores to construct the final training dataset.
创建时间:
2025-02-04
原始信息汇总
数据集概述:Synthetic Customization Data (SynCD)
数据集简介
SynCD 是一个合成数据集,用于生成具有不同光照、姿态和背景的同一物体的多张图像。该数据集可以基于显式的 3D 物体资产或通过不同视图之间的遮罩共享注意力(MSA)更隐式地使用。数据集用于训练一个新的基于编码器的模型,用于定制化/个性化。
数据集组成
- 数据集包含多个图像,这些图像是同一物体在不同条件下的合成。
- 数据集生成流程针对可变形类别使用描述性提示和 MSA,对于刚性物体类别,则额外使用深度和跨视图扭曲。
数据集用途
- 用于训练一个预训练的 IP-Adapter 基模型,并进行微调以注入全局特征。
- 在训练过程中,使用 MSA 在图像的目标和参考特征之间进行细粒度特征注入。
数据集获取
- 数据集将通过 GitHub 释放,具体时间预计在 2 月 10 日前。
- 用户可以通过 Git 克隆和一系列环境配置步骤来获取和准备数据集。
数据集引用
@article{kumari2025syncd, title={Generating Multi-Image Synthetic Data for Text-to-Image Customization}, author={Kumari, Nupur and Yin, Xi and Zhu, Jun-Yan and Misra, Ishan and Azadi, Samaneh}, journal={ArXiv}, year={2025} }
搜集汇总
数据集介绍
构建方式
SynCD数据集的构建采取了一种创新的生成多图像合成数据的方法,其核心在于利用描述性提示和图像前景对象区域之间的Masked Shared Attention(MSA)技术,以促进视觉一致性。对于可变形类别,该数据集使用MSA;对于刚性对象类别,则进一步采用深度信息和跨视图扭曲,以确保3D多视图的一致性。通过DINOv2和审美得分对低质量图像进行过滤,最终形成了高质量的训练数据集。
特点
该数据集的主要特点是合成了一系列在光照、姿态和背景方面多样化的同一对象的多幅图像。这些图像的生成,既可以通过显式的3D对象资产,也可以更隐式地通过不同视角之间的Masked Shared Attention实现。此外,该数据集经过精心筛选,确保了图像质量的高标准,适用于文本到图像定制的任务。
使用方法
使用SynCD数据集首先需要通过Git克隆相关代码库,并创建相应的Python环境。接着安装必要的依赖库,然后可以参照数据集生成代码和SDXL模型训练代码进行数据集的生成和模型的训练。详细的操作指南和代码可在数据集的GitHub仓库中找到,用户需按照说明逐步执行以完成整个流程。
背景与挑战
背景概述
SynCD数据集,由Nupur Kumari、Xi Yin、Jun-Yan Zhu、Ishan Misra和Samaneh Azadi等研究人员提出,并于2025年发布。该数据集旨在为文本到图像个性化定制生成多图像合成数据。SynCD的创建,是为了解决在图像处理和生成模型训练中,由于缺乏多样化的训练数据而导致的模型性能局限问题。该数据集采用先进的3D对象资产和masked shared attention技术,生成在照明、姿态和背景方面多样化的对象图像,进而训练出能够进行个性化定制的新编码器模型。SynCD的构建,对图像合成和个性化领域产生了重要影响,为相关研究提供了高质量的数据资源。
当前挑战
在构建SynCD数据集的过程中,研究人员面临了多个挑战。首先,确保3D对象资产和masked shared attention技术的有效结合,以生成高质量的合成图像,是一大挑战。其次,数据集的多样性和质量把控也是关键,需要通过精细的图像筛选流程来剔除低质量图像。此外,SynCD在处理可变形和刚性对象类别时,采用了不同的技术策略,以确保多视角的一致性,这在技术实现上同样具有挑战性。最后,合成数据在实际应用中的泛化能力,以及如何有效利用这些数据提升模型性能,也是当前和未来研究的重点挑战。
常用场景
经典使用场景
在计算机视觉与机器学习领域,SynCD数据集的构建旨在为文本到图像个性化定制任务提供高质量的合成训练数据。该数据集通过捕获同一物体在不同光照、姿态和背景下的多幅图像,为模型训练提供了丰富的视觉变异,其经典使用场景在于辅助训练能够根据文本提示生成新物体组合的编码器基础模型。
解决学术问题
SynCD数据集解决了传统训练数据中缺乏多样化样本以及难以保持视觉一致性的问题,它通过合成多视角、多背景下的物体图像,为学术研究提供了处理可变形类别和刚性物体类别的新途径,极大地促进了视觉定制化任务中的细粒度特征学习。
衍生相关工作
基于SynCD数据集,研究者们已开展了一系列相关工作,包括但不限于对预训练模型的微调、多模态学习任务的研究,以及利用该数据集进行的三维物体理解和生成等,这些研究进一步扩展了数据集的应用范围并推动了相关领域的学术进步。
以上内容由遇见数据集搜集并总结生成


