af2_plddt
收藏Hugging Face2025-09-15 更新2025-09-16 收录
下载链接:
https://huggingface.co/datasets/GleghornLab/af2_plddt
下载链接
链接失效反馈官方服务:
资源简介:
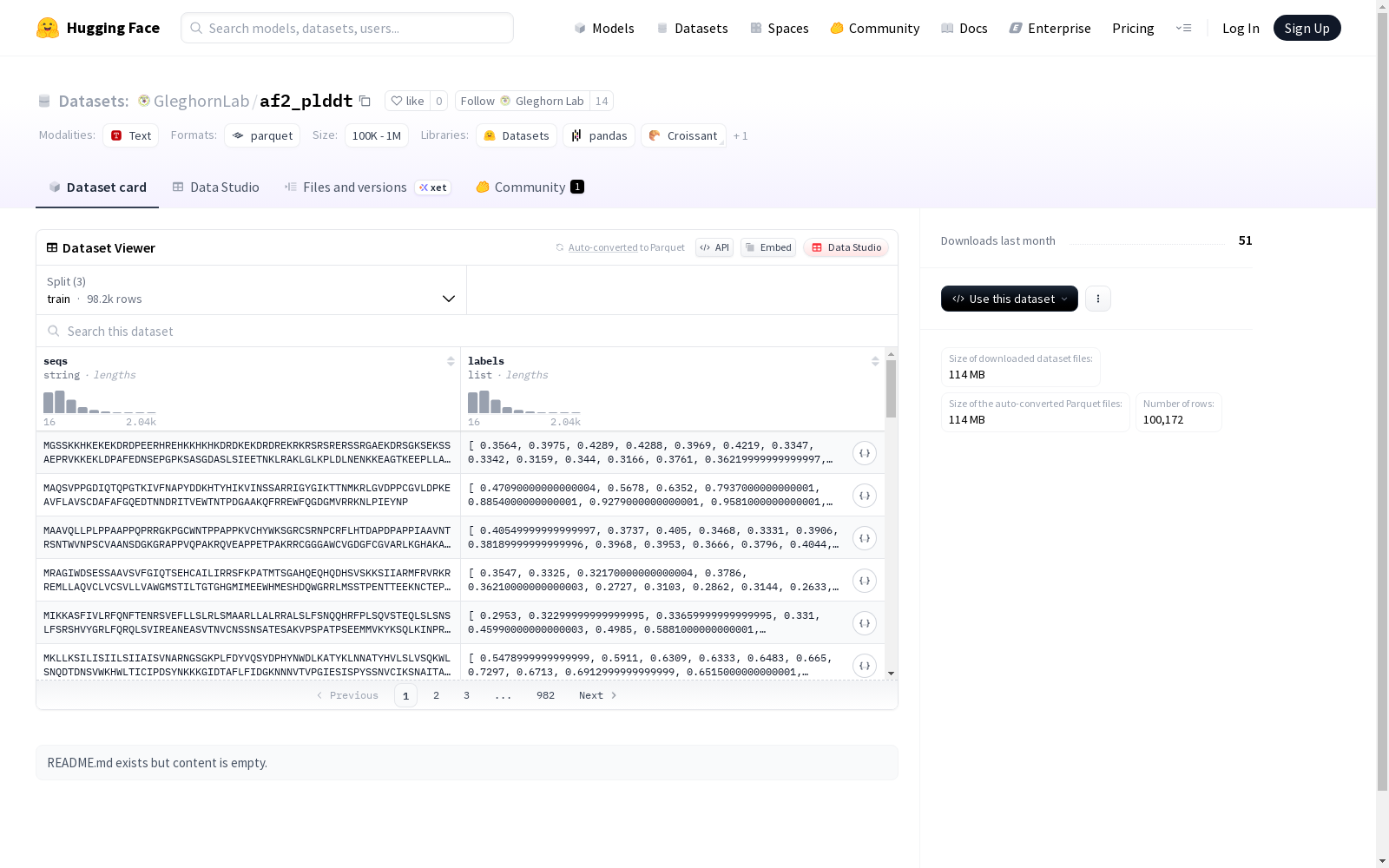
该数据集包含序列数据(seqs)和对应的标签(labels),适用于序列标注或分类任务。数据集分为训练集、验证集和测试集,共计100,272个示例。训练集包含98,172个示例,大小为368.13MB;验证集和测试集各包含1,000个示例,大小分别为3.78MB和3.73MB。整个数据集的大小为373.64MB,下载大小为110.43MB。
提供机构:
Gleghorn Lab
创建时间:
2025-09-15
原始信息汇总
数据集概述
基本信息
- 数据集名称: af2_plddt
- 存储位置: https://huggingface.co/datasets/GleghornLab/af2_plddt
数据集结构
- 特征:
seqs: 字符串类型labels: 浮点数序列类型(float64)
数据划分
- 训练集(train):
- 样本数量: 98,172
- 数据大小: 368,126,847 字节
- 验证集(valid):
- 样本数量: 1,000
- 数据大小: 3,777,866 字节
- 测试集(test):
- 样本数量: 1,000
- 数据大小: 3,734,333 字节
存储信息
- 下载大小: 114,430,736 字节
- 数据集总大小: 375,639,046 字节
配置文件
- 默认配置(default):
- 训练集文件路径: data/train-*
- 验证集文件路径: data/valid-*
- 测试集文件路径: data/test-*
搜集汇总
数据集介绍
构建方式
在计算结构生物学领域,af2_plddt数据集通过整合AlphaFold2模型预测的蛋白质结构置信度数据构建而成。该过程涉及从大量蛋白质序列中提取预测的局部距离差异测试(pLDDT)分数,并将其与对应序列配对,形成结构化标注。数据经过严格的质量控制与标准化处理,划分为训练、验证和测试子集,确保数据的可靠性与一致性。
特点
af2_plddt数据集的核心特点在于其专注于蛋白质结构的置信度评估,每个样本包含序列字符串及对应的浮点数pLDDT分数序列。数据集规模庞大,涵盖近10万个训练样本,且提供清晰的划分以支持模型训练与评估。其数值特征直接关联结构预测的可信度,为深度学习模型提供了高精度的监督信号。
使用方法
该数据集适用于蛋白质结构预测与评估模型的训练,用户可加载序列数据作为输入,pLDDT分数作为目标输出进行监督学习。通过HuggingFace平台的标准数据加载接口,可便捷访问训练、验证和测试分割,支持跨框架集成。典型应用包括置信度预测模型的开发与基准测试,推动生物信息学工具的创新。
背景与挑战
背景概述
蛋白质结构预测领域自20世纪中叶以来一直是计算生物学的核心议题,af2_plddt数据集作为AlphaFold2算法的衍生产物,由DeepMind团队于2021年构建,旨在量化预测蛋白质模型的局部置信度。该数据集通过pLDDT(预测局部距离差异测试)分数序列,为每个残基的预测可靠性提供标准化评估,显著推动了蛋白质结构质量评估范式的革新,并为药物设计、酶工程等应用领域提供了关键可信度基准。
当前挑战
该数据集需解决蛋白质结构置信度评估中的空间几何一致性难题,包括高突变区域残基的稳定性判别、动态构象变化的分数校准等核心问题。构建过程中面临多重挑战:需从AlphaFold2的海量预测结果中提取标准化pLDDT序列,处理非标准氨基酸残基的分数映射,并保证与实验结构数据的可比性。同时,数据分布偏差的修正与跨物种蛋白质泛化能力的验证亦是关键难点。
常用场景
经典使用场景
在蛋白质结构预测领域,af2_plddt数据集作为评估模型置信度的黄金标准,其经典应用场景体现在为AlphaFold2等预测模型提供pLDDT分数标注。研究人员通过该数据集能够量化每个残基的预测可靠性,进而区分高置信度区域与需实验验证的柔性区域,为结构生物学研究提供关键质量指标。
实际应用
在实际应用中,af2_plddt数据集被制药公司广泛用于药物靶点筛选和蛋白质设计。通过分析pLDDT分数分布,研究人员可优先选择高置信度区域进行药物结合位点设计,加速理性药物开发进程,同时规避因结构不确定性导致的研发风险,提升生物医药研究的效率与成功率。
衍生相关工作
该数据集催生了多项经典衍生研究,如蛋白质结构评估工具ESMFold的校准模块开发,以及基于pLDDT分数的蛋白质动力学模拟优化框架。这些工作进一步拓展了置信度评分在蛋白质设计、功能注释和复合物构象分析中的应用深度,形成了结构生物信息学领域的新方法论体系。
以上内容由遇见数据集搜集并总结生成


