ekacare/indian_protocols_based_clinical_QnA
收藏Hugging Face2026-05-05 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/ekacare/indian_protocols_based_clinical_QnA
下载链接
链接失效反馈官方服务:
资源简介:
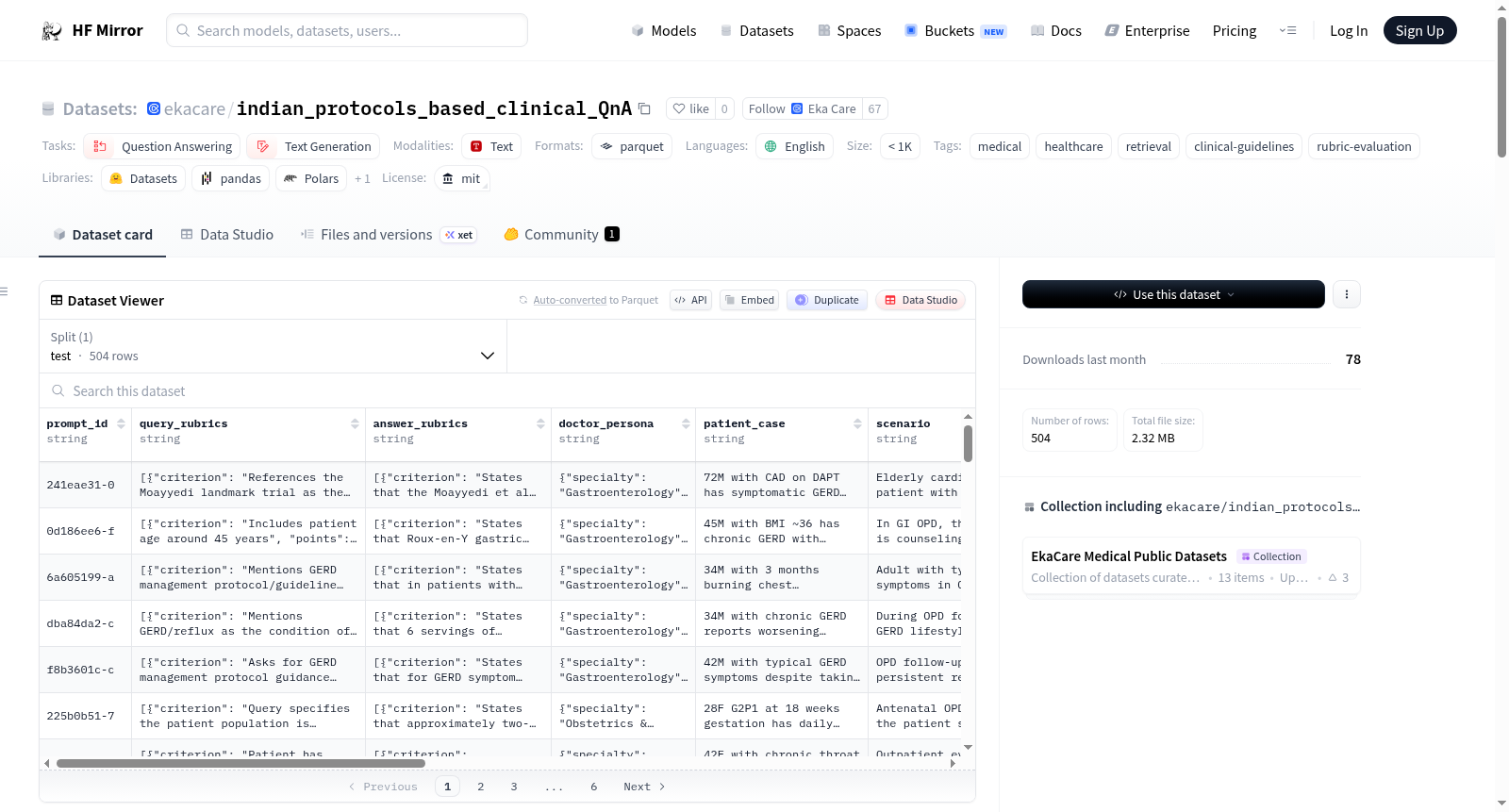
该数据集是一个基于印度和国际临床指南文档构建的评估数据集,用于测试临床助手在基于协议的问答中的表现。数据集包含504个对话提示,每个提示包括评估检索系统是否正确解释医生查询的查询评分标准,以及评估临床答案准确性、完整性和安全性的答案评分标准。数据集旨在突出特定失败模式,如指南基础、查询解释、完整性与简洁性、安全回归和隐式记忆盲点。数据集结构包括多个列,如prompt_id、query_rubrics、answer_rubrics等,详细描述了每个提示的属性。数据集支持通过KARMA评估框架或直接加载使用。
A rubric-graded evaluation dataset built from clinical guideline documents (Indian and international). Each sample is a realistic doctor-side query against a known protocol, paired with rubrics that grade (a) whether the system retrieved/identified the correct guideline content and (b) whether the final answer is clinically complete and safe. The dataset is designed to stress-test clinical assistants on protocol-grounded question answering and surface specific failure modes such as guideline grounding, query interpretation under realistic noise, completeness vs. brevity, safety regressions, and implicit-memory blind spots. It contains 504 conversation prompts derived from clinical scenarios across Indian and international medical guidelines, with each prompt including query and answer rubrics for evaluation. The dataset is structured with various columns detailing each prompts attributes, such as prompt_id, query_rubrics, answer_rubrics, and more. It supports usage with the KARMA Evaluation Framework and direct loading via the HuggingFace datasets library.
提供机构:
ekacare
搜集汇总
数据集介绍
构建方式
在临床医学领域,精准遵循诊疗指南是保障患者安全与疗效的基石。该数据集源自印度及国际权威临床指南文件,通过模拟医生在真实诊疗场景中提出的简短、缩写或夹杂印地语与英语的查询,构建了504个基于协议的结构化问答样本。每个样本均包含由领域专家设计的双阶段评估准则:查询准则用于衡量检索系统能否正确解读医生的临床意图并定位至恰当的指南来源;答案准则则从完整性、准确性及安全性三个维度评判最终回复,尤其通过负分机制惩罚可能引发危险的违禁或非协议推荐。这种体系化构建方式确保了数据集对临床助手在协议驱动问答中的薄弱环节进行系统性压力测试。
特点
该数据集的核心特色在于其多层次、多维度的评估框架。首先,它强调指南溯源能力,要求模型答案严格基于指定指南(如ADA、AHA或IAP),而非泛泛的医学常识。其次,查询噪声设计极具现实性——医生查询常以速记、缩写或混合语形式呈现,这对模型的语义理解构成挑战。第三,答案准则的平衡性设计尤为精妙:正分奖励关键临床细节(如剂量、禁忌症与随访标准)的完整呈现,负分则严厉惩罚有害或偏离协议的建议。此外,多数样本明确指向特定指南来源,模型若仅依赖参数记忆易致失败,而结合网络搜索或检索增强生成的方法则表现更优,揭示了纯参数化模型的盲区。
使用方法
该数据集主要通过两种途径使用。其一,推荐集成至KARMA评估框架,通过命令行一键启动临床对话模型的评测,例如指定评估模型、数据集及评分参数,即可获取基于查询与答案准则的细粒度评分。其二,支持直接通过HuggingFace的datasets库加载,将数据切分为测试集,便于研究人员独立运行定制化的评估流程。每个样本包含prompt_id、doctor_query、query_rubrics、answer_rubrics等字段,用户可根据question_type、difficulty_level等标签进行筛选分析。需注意,为充分挖掘数据集价值,评估时建议启用模型的网络搜索或外部知识检索能力,而不仅依赖其内在记忆,以真实反映临床助手在协议遵循中的表现。
背景与挑战
背景概述
在临床决策支持系统快速发展的背景下,确保人工智能模型能够严格遵循既定诊疗指南进行问答,对于保障患者安全与医疗质量至关重要。Indian Protocols-Based Clinical Q&A数据集由Eka.Care于2025年创建,专注于评估临床助手在协议导向问答任务中的表现。该数据集包含504个源自印度及国际临床指南(如AGA、ADA、AHA、IAP等)的对话提示,核心研究问题在于系统能否准确检索并引用正确的指南内容,而非依赖通用医学知识给出回答。作为首个系统性地围绕临床指南构建的评估数据集,它为检验模型在真实临床场景中的协议符合性、安全性和完整性提供了标准化基准,对推动可信赖的医疗AI发展具有显著影响力。
当前挑战
当前数据集着力解决的领域挑战是临床问答系统的协议依从性,即模型常混淆不同权威指南(如ADA与AHA),或基于参数化记忆生成未经验证的通用建议,导致临床决策风险。构建过程中面临两大挑战:其一,临床医生的真实查询常以缩写、速记或印地语与英语混杂(Hinglish)的形式出现,需在有限上下文中准确提取临床意图;其二,设计细粒度评估量规时,需平衡回答的全面性与简洁性,同时通过负向评分机制精准捕捉危险、禁忌或偏离协议的建议,这对标注质量和评估框架的严谨性提出了极高要求。
常用场景
经典使用场景
在临床医疗人工智能领域,模型对权威诊疗指南的忠实遵循是衡量其安全性与可靠性的核心标尺。Indian Protocols-Based Clinical Q&A 数据集正是为此而生,它聚焦于基于协议(protocol-grounded)的临床问答任务,要求模型依据印度及国际医学指南(如 ADA、AHA、IAP 等)中的具体条款来回答医生的真实提问。该数据集包含 504 个经过精细标注的对话样本,每一条都配备了检索查询评分规则与答案评分规则,专门用于检验模型在面对包含缩写、口语化表达或印地语-英语混杂(Hinglish)的现实临床问题时,能否准确理解医生意图、定位正确指南内容,并给出临床完整且安全的回答。这一经典场景为评估和提升临床对话系统的指南接地能力提供了标准化测试平台。
解决学术问题
该数据集直接回应了当前大语言模型在医疗应用中面临的几个关键学术难题:其一是指南接地问题,即模型是否依据正确的权威指南作答,而非依赖通用的医学知识泛化回答;其二是隐式记忆盲区,模型在处理明确引用特定出版商或指南名称的查询时,往往难以区分相似指南间的细微差异,而此数据集通过设计难题样本暴露了单纯依赖参数化记忆的不足;其三是临床安全回退,通过负向评分规则惩罚危险或禁忌建议,量化评估模型的临床安全边际。这些设计使得研究者能够系统性地诊断模型在协议级问答中的失败模式,进而推动检索增强生成、多文档推理和安全性对齐等前沿研究方向的发展。
衍生相关工作
该数据集的诞生催生了一系列重要的学术与实践成果。最直接的是 KARMA 评估框架的创建,它将本数据集的评分规则嵌入自动化评估管道,支持对临床对话系统的检索与生成质量进行联合评价。研究者还基于该数据构建了专门的临床 RAG 基准测试,系统比较了不同检索策略(稀疏检索、稠密检索、混合检索)与生成模型组合在指南接地问答上的表现。在模型改进方面,相关工作提出了分层级指南路由技术,先通过查询识别所属指南体系,再进行精细化的片段检索,显著提升了模型对指定协议的遵循率。此外,安全对齐领域也涌现了利用本数据集的负向评分规则进行偏好优化训练的方法,有效减少了模型产生危险建议的概率。
以上内容由遇见数据集搜集并总结生成


