nshah-fbcs/childes-engUK-conversational-pairs
收藏Hugging Face2026-05-01 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/nshah-fbcs/childes-engUK-conversational-pairs
下载链接
链接失效反馈官方服务:
资源简介:
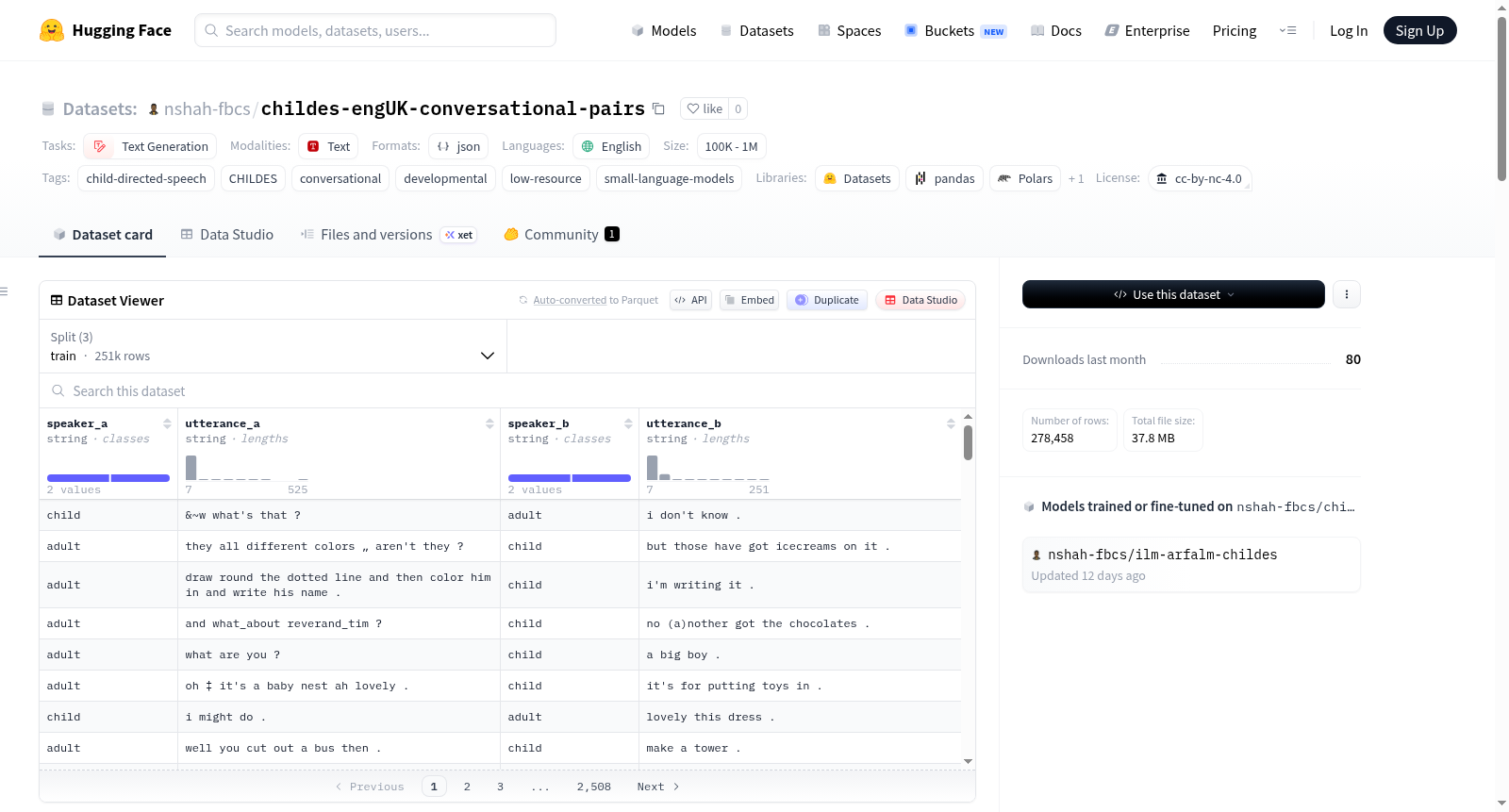
该数据集名为CHILDES Eng-UK Conversational Pairs,是从CHILDES(儿童语言数据交换系统)的英语-英国部分提取的自然亲子对话对。数据集包含278,458个对话对,分为训练集(250,757对,来自2,784个转录本)、验证集(13,197对,来自训练转录本的样本)和测试集(14,504对,来自5个完全保留的儿童的93个转录本)。每个记录是一个相邻的成人-儿童或儿童-成人的话语对,包含说话者身份和清理后的小写话语。数据集旨在用于训练小型语言模型、评估语言模型对未见儿童的泛化能力、发展性NLP研究等。数据集存在一些局限性,如人口统计狭窄性、转录风格差异等。
The dataset is named CHILDES Eng-UK Conversational Pairs, which consists of curated naturalistic parent-child conversational pairs extracted from the English-UK collection of CHILDES (MacWhinney, 2000). It includes a total of 278,458 conversation pairs across train (250,757 pairs from 2,784 transcripts), validation (13,197 pairs, in-distribution, sampled from training transcripts), and test (14,504 pairs from 5 completely held-out children, 93 transcripts) sets. Each record is a single adjacent adult-child or child-adult utterance pair, containing speaker roles and cleaned, lowercased utterances. The dataset is intended for training small language models on naturalistic child-directed speech, evaluating language model generalization to unseen children, developmental NLP research, etc. Limitations include demographic narrowness, transcription convention variations, etc.
提供机构:
nshah-fbcs
搜集汇总
数据集介绍
构建方式
该数据集源自CHILDES语料库中的英式英语子集,经过精细的对话对提取与清洗流程构建而成。原始.cha文件被解析后,将儿童(CHI)与母亲(MOT)、父亲(FAT)或研究者(INV)之间的相邻话语配对,并利用正则表达式移除CHAT标注中的时间戳、括号注释、false-start标记及形态学标签。经词级清洗后,任一话语少于四个单词的配对被丢弃。最终形成训练集250,757对(来自2,784份转录)、验证集13,197对(从训练转录中分布内抽样)、测试集14,504对(来自5名完全留出的儿童,共93份转录),总计278,458个对话对。
特点
本数据集的核心特色在于其严格的留出测试机制:5名儿童按年龄分层随机选取,完整地从训练过程中隔离,确保模型评估时面对的是完全未见的话语环境。每个JSONL记录包含两位说话者身份(儿童/成人)及两个连续、小写化且去除标点的话语,结构简洁而信息完整。数据覆盖从1岁至5岁以上的儿童发展阶段,年龄跨度合理,且所有对话均为自然情境下的亲子交流,具备高度的生态效度。此外,贝法斯特子语料库因转录风格差异导致词级困惑度显著偏高,为模型跨语料泛化能力的检验提供了独特视角。
使用方法
数据集以train.jsonl、validation.jsonl、test.jsonl三个文件提供,采用JSONL格式,可直接通过读取一行一个JSON对象的方式加载。研究人员可将其用于训练面向儿童导向话语的小规模语言模型,评估模型对未见过儿童的泛化性能,或开展发展计算语言学与样本高效预训练研究。使用时需注意其局限性:所有数据均为英式英语,族群与阶层的代表性有限;预处理过程中的小写化和去标点操作损失了原始文本的格式信息,需要保留大小写或标点的任务应回归原始CHILDES的.cha文件。该数据集仅限研究及教育用途,使用者需遵守TalkBank伦理规范。
背景与挑战
背景概述
儿童语言习得研究长期依赖人工采集的亲子对话语料,但现有数据集多聚焦于特定年龄阶段或小样本量,限制了语言模型在发育自然语言处理中的泛化能力。CHILDES Eng-UK Conversational Pairs数据集由N. A. Shah及其合作者于2026年创建,源自MacWhinney建立的CHILDES语料库中的英国英语子集,旨在为训练面向儿童导向语音的小规模语言模型提供大规模、自然态的亲子会话对。该数据集包含27.8万余对相邻话语,跨越多个年龄层,并严格划分了5名完全未参与训练的儿童作为测试集,以评估模型对未见说话人的适应能力。其发布推动了低资源场景下儿童语言建模、样本高效预训练及可部署小型语言模型的研究进展。
当前挑战
该数据集所解决的领域问题核心在于:现有语言模型通常在大规模通用文本上训练,难以捕捉儿童语言输入的独特统计特性和交互结构,且缺乏对真实亲子对话中话轮转换、语义连贯性及年龄依赖性的建模能力。构建过程中面临的挑战包括:1)从1976年至2010年间多个录音语料库中提取统一格式的会话对,需去除CHAT转录注释、时间戳等复杂符号;2)不同子语料库(如贝尔法斯特子集)因转录风格和录音环境差异导致词级困惑度偏差高达50%,需通过年龄分层与完整保留儿童史来缓解;3)低资源环境下的数据稀疏性——部分儿童仅有8个会话记录,需确保测试集在年龄分布和会话次数上的代表性;4)去标识化与伦理约束下的数据清洗,未应用自动毒性过滤,要求研究者自行补充安全措施。
常用场景
经典使用场景
在儿童语言习得与认知发展研究领域,该数据集最经典的使用场景聚焦于训练面向儿童的自然语言模型,尤其是低资源环境下的小规模语言模型。通过精心提取英式英语亲子对话中的相邻话轮对,数据集为模型提供了自然、真实的儿童指向语音输入,使研究者能够模拟儿童在真实互动中学习语言的微观过程。这种设计特别适合于探究语言习得的统计学习机制,以及评估模型在接触有限数据时的泛化能力。
实际应用
在实际应用层面,该数据集可服务于开发面向儿童的可交互智能系统,如寓教于乐的对话式学习助手、儿童口语发展评估工具,以及针对语言发育迟缓人群的辅助沟通设备。尤其值得关注的是,因其专注于低算力场景下的模型训练,该数据集有望推动轻量级语言模型在边缘计算设备上的部署,使得资源匮乏地区或家庭也能借助老旧硬件获得智能化的儿童语言支持服务,缩小数字鸿沟。
衍生相关工作
基于该数据集已衍生出一系列具有影响力的经典工作,包括N. A. Shah等人提出的ILM与ArfaLM儿童尺度语言模型,这些模型专门设计用于在低于1GHz主频的遗留硬件上运行,系统性地对比了不同架构在亲子对话数据上的表现。此外,相关研究还深入探讨了模型对于不同方言子语料库(如贝尔法斯特语料)的困惑度差异,揭示了转录风格与录音背景对语言建模的潜在影响,为后续数据增强和领域自适应工作铺平了道路。
以上内容由遇见数据集搜集并总结生成


