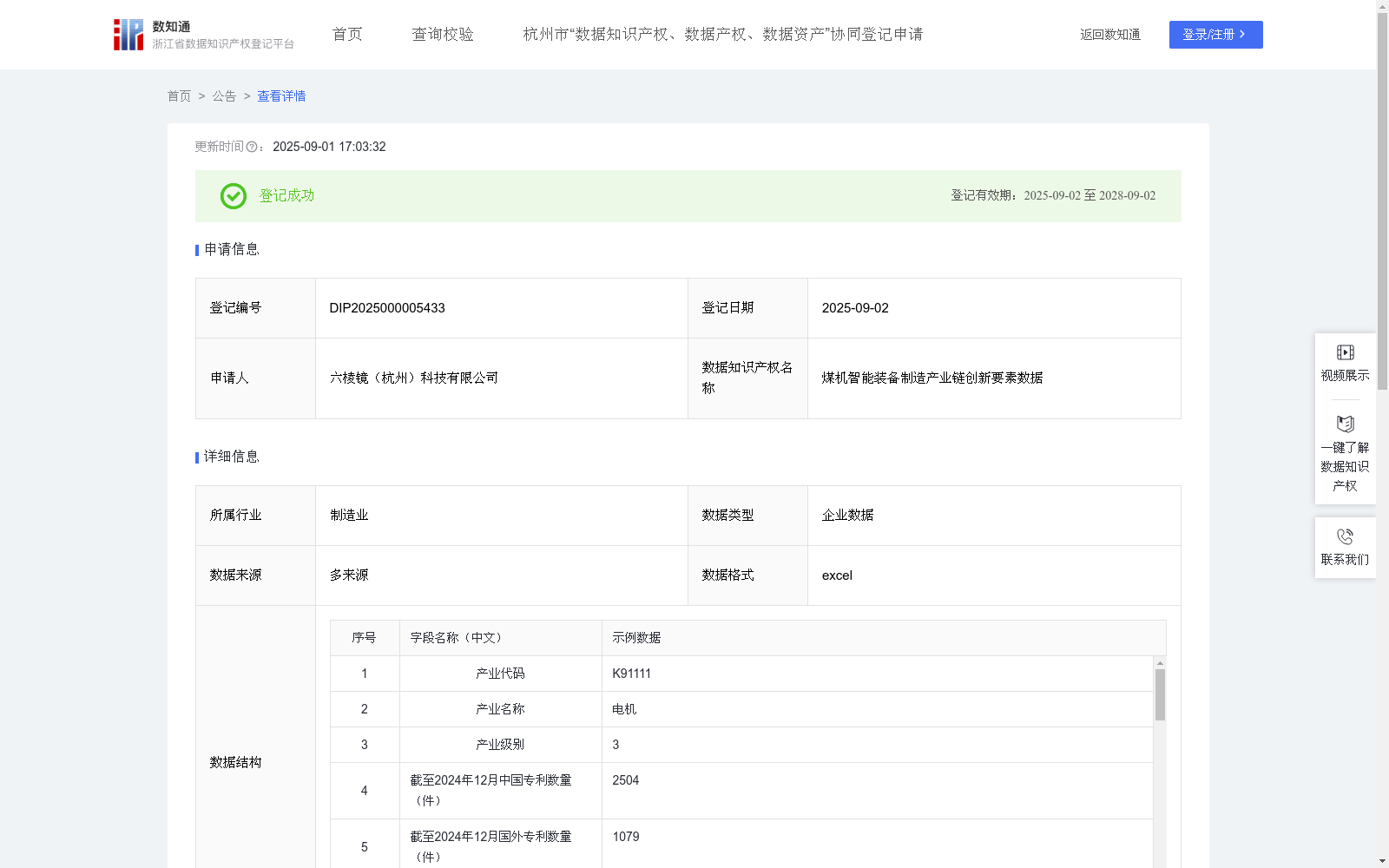
煤机智能装备制造产业链创新要素数据
收藏浙江省数据知识产权登记平台2025-09-01 更新2025-09-06 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/173580
下载链接
链接失效反馈官方服务:
资源简介:
通过采集、标引及分析获得产业链标签统计数据及专利、企业、人才等创新要素数据并按月更新,构建起覆盖全产业链的动态数据网络,可为政府部门产业规划、招商引智、企业培育等决策制定提供有价值的参考,为企业研发创新立项、竞争对手分析提供数据支撑。
政府部门:通过“统计数据”掌握全球、中国产业链各层级专利技术、创新企业、发明人才的发展现状和创新热点方向,分析出创新活跃、企业集聚度高和目前尚存在空白或不足的产业链环节,从而在制定产业规划时针对性地加大对该环节的扶持力度;通过“企业数据”和“人才数据”,根据专利公开量和发明公开量精准定位具有创新实力的企业和高端人才,针对性地进行招商引智和企业培育。
企业:通过“统计数据”了解整个产业的专利申请情况,发现行业中技术创新活跃细分领域,关注该领域的新技术,从而结合自身产品特点有针对性地进行升级;通过“企业数据”对比自身与同行业其他企业的专利数量等指标,了解自身在行业中的地位,分析自己的优势和不足;通过“专利数据”分析不同企业的专利技术,掌握竞争对手的研发方向和创新成果,在研发创新立项时避免重复研发,找准差异化竞争方向;利用“人才数据”发现潜在的优秀人才。产业链数据为按月更新。样例数据分析时间:2025年4月,数据统计范围:截至2024年12月。
1.数据清洗
格式解析与字段提取:使用正则表达式(REGEX)和文件解析函数,对采集到的 CSV、JSON、XML 等不同格式的中外文专利、企业、人才等源数据进行解析,按照预定义字段(如 专利数据的“申请日期”、企业数据的“成立时间”人才数据的“当前所在单位” 等)进行数据提取。
对不规范数据处理:包括缺失值补充和重复值去重处理。
2.数据加工处理
产业链各层级细分领域提取并编码:采用基于 BERT 的文本分类预测算法模型,输入多维文本数据(如企业名称、专利名称),通过预训练模型进行特征提取,输出对应的产业链各层级细分领域标签,按照产业级别进行产业代码编码。
产业链相关数据标引提取:通过产业链标引模型对文本智能标引和利用关键词匹配算法结合专利分类号对专利数据检索标引,标引得到产业链各层级细分领域相关的专利、企业、人才数据,为以上创新要素数据赋予产业代码和产业链细分领域标签。
专利企业人才等多维数据融合标引:基于分类标签提取融合算法,将专利数据中的“原始申请人”,与企业数据中的“企业名称”,以及人才数据中的“当前所在单位”等多源异构数据进行关联标引,进一步为专利、企业、人才等数据赋予产业代码和产业链细分领域标签,最终生成内容完整、形式规范的产业链标签信息,形成产业链专利数据、产业链企业数据和产业链人才数据。
个人数据与公共数据处理:对涉及的个人数据(如发明人)进行匿名化处理,对公共数据中的敏感信息(如企业名称),进行去标识化处理,确保无法通过任何算法还原原始数据。
3.数据统计分析
产业链细分领域数据统计:基于各级别产业代码标签,进行产业链各层级细分领域的中外文专利、企业、人才数据统计,将统计结果按照产业链细分分类进行汇总,生成数据报表“统计数据”,直观展示产业链创新要素分布情况。例如,统计“专利数据”在各级别产业代码下的“申请号”数量,得到“统计数据”中产业各细分领域的专利数量;统计“企业数据”在各级别产业代码下的“企业名称”数量,得到“统计数据”中产业各细分领域的企业数量;统计“人才数据”在各级别产业代码下的“发明人”数量,得到“统计数据”中产业各细分领域的人才数量。
Collected, indexed and analyzed industrial chain label statistical data and innovation factor data including patents, enterprises and talents, which is updated monthly, this dataset builds a dynamic data network covering the entire industrial chain. It provides valuable references for government departments to make decisions such as industrial planning, investment and talent attraction, and enterprise cultivation, and offers data support for enterprises' R&D innovation project establishment and competitor analysis.
For government departments: By leveraging the "Statistical Data", they can grasp the current development status and hot innovation directions of patent technologies, innovative enterprises and inventive talents at all levels of the global and Chinese industrial chains, identify industrial chain links with active innovation, high enterprise agglomeration, and current gaps or deficiencies, and thus provide targeted support for these links when formulating industrial plans. By using "Enterprise Data" and "Talent Data", they can accurately locate enterprises with innovative strength and high-end talents based on the number of patent publications and invention publications, and carry out targeted investment and talent attraction as well as enterprise cultivation.
For enterprises: By referring to the "Statistical Data", they can understand the overall patent application status of the industry, identify sub-sectors with active technological innovation in the industry, pay attention to new technologies in these fields, and conduct targeted upgrades combined with their own product characteristics. By comparing indicators such as the number of patents with other enterprises in the same industry using "Enterprise Data", they can understand their own position in the industry and analyze their own advantages and disadvantages. By analyzing the patent technologies of different enterprises through "Patent Data", they can grasp the R&D directions and innovation achievements of competitors, avoid redundant R&D when establishing R&D innovation projects, and identify differentiated competition directions; they can also discover potential excellent talents by using "Talent Data". The industrial chain data is updated monthly. Sample data analysis time: April 2025; data statistical scope: up to December 2024.
1. Data Cleaning
Format Analysis and Field Extraction: Regular Expression (REGEX) and file parsing functions are used to parse the collected Chinese and foreign language source data including patents, enterprises and talents in different formats such as CSV, JSON and XML, and extract data according to pre-defined fields (e.g., "Application Date" for patent data, "Establishment Time" for enterprise data, "Current Affiliated Unit" for talent data, etc.).
Processing of Non-standard Data: Includes missing value imputation and duplicate value deduplication.
2. Data Processing
Extraction and Coding of Industrial Chain Sub-sectors at All Levels: A BERT-based text classification and prediction algorithm model is adopted. Multi-dimensional text data (e.g., enterprise names, patent names) are input, feature extraction is performed through the pre-trained model, corresponding sub-sector labels at all levels of the industrial chain are output, and industrial code coding is carried out according to industrial levels.
Indexing and Extraction of Industrial Chain-related Data: The industrial chain indexing model is used for intelligent text indexing, and the keyword matching algorithm combined with patent classification numbers is used to retrieve and index patent data, so as to obtain patent, enterprise and talent data related to sub-sectors at all levels of the industrial chain, and assign industrial codes and industrial chain sub-sector labels to the above-mentioned innovation factor data.
Multi-dimensional Data Fusion Indexing for Patents, Enterprises and Talents: Based on the classification label extraction and fusion algorithm, multi-source heterogeneous data such as "Original Applicant" in patent data, "Enterprise Name" in enterprise data and "Current Affiliated Unit" in talent data are associated and indexed, further assigning industrial codes and industrial chain sub-sector labels to patent, enterprise and talent data. Finally, complete and standardized industrial chain label information is generated, forming industrial chain patent data, industrial chain enterprise data and industrial chain talent data.
Processing of Personal and Public Data: Personal data involved (e.g., inventors) are anonymized, and sensitive information in public data (e.g., enterprise names) are de-identified to ensure that the original data cannot be restored by any algorithm.
3. Data Statistical Analysis
Data Statistics for Industrial Chain Sub-sectors: Based on industrial code labels at all levels, statistics are conducted on Chinese and foreign language patent, enterprise and talent data of sub-sectors at all levels of the industrial chain. The statistical results are summarized according to industrial chain sub-sector classifications to generate the data report "Statistical Data", which intuitively displays the distribution of industrial chain innovation factors. For example, counting the number of "Application Numbers" of "Patent Data" under industrial codes at all levels to obtain the number of patents in each industrial sub-sector in the "Statistical Data"; counting the number of "Enterprise Names" of "Enterprise Data" under industrial codes at all levels to obtain the number of enterprises in each industrial sub-sector in the "Statistical Data"; counting the number of "Inventors" of "Talent Data" under industrial codes at all levels to obtain the number of talents in each industrial sub-sector in the "Statistical Data".
提供机构:
六棱镜(杭州)科技有限公司
创建时间:
2025-05-15
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集专注于煤机智能装备制造产业链的创新要素数据,提供相关产业的关键信息和分析支持。
以上内容由遇见数据集搜集并总结生成


