SaProtHub/Dataset-Binary_Localization-DeepLoc
收藏Hugging Face2025-02-04 更新2024-06-12 收录
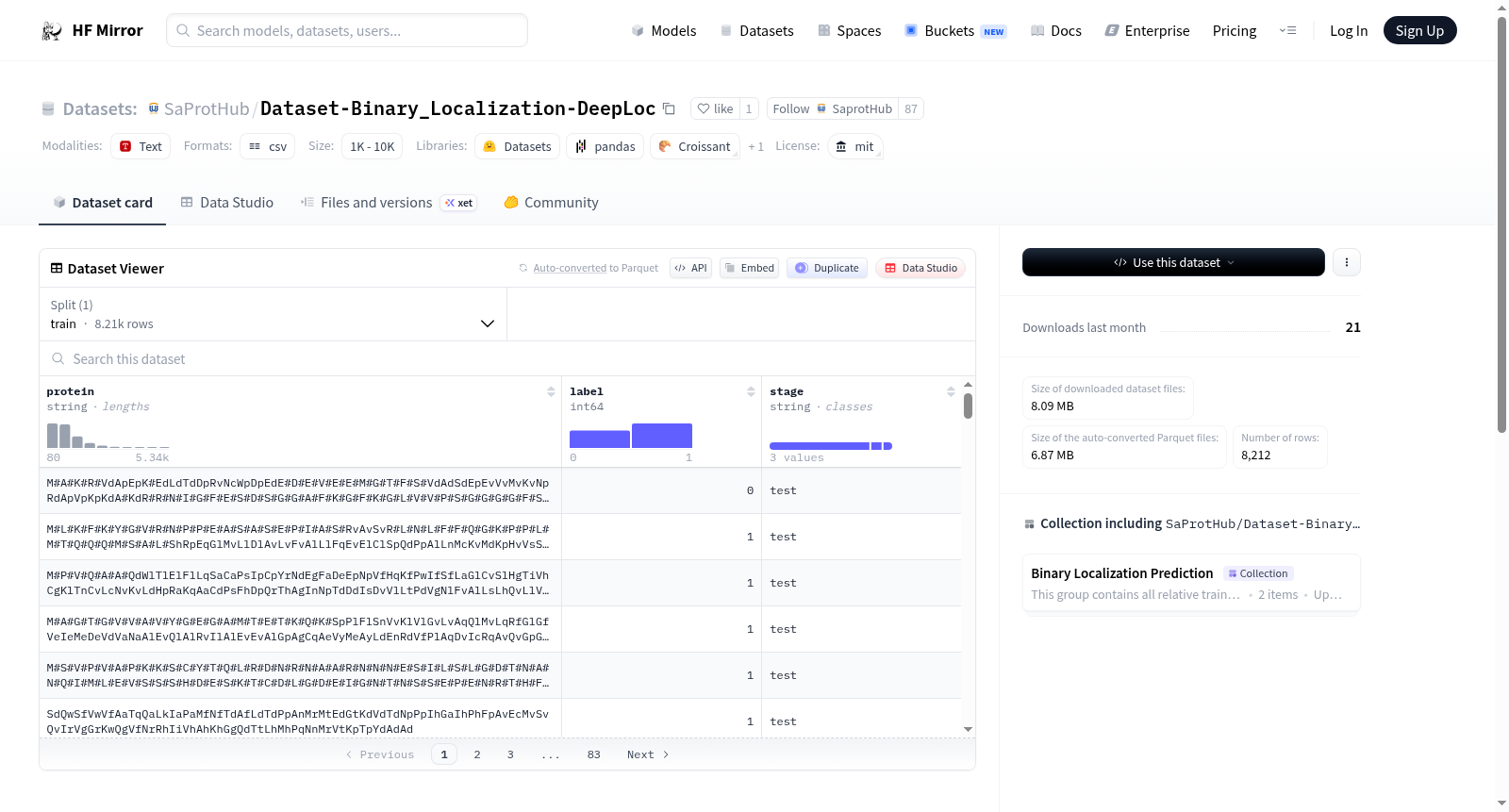
下载链接:
https://hf-mirror.com/datasets/SaProtHub/Dataset-Binary_Localization-DeepLoc
下载链接
链接失效反馈官方服务:
资源简介:
二元定位预测是一个二元分类任务,每个输入的蛋白质x被映射到一个标签y ∈ {0, 1},分别对应“膜结合”或“可溶性”。数据集来源于DeepLoc研究,使用了所有具有AF2结构的蛋白质,并基于70%的结构相似性进行分割。数据集分为训练集、验证集和测试集,具体数量分别为6707、698和807。数据格式为LMDB,包含蛋白质的UniProt ID、结构感知序列和分类标签。
Binary Localization prediction is a binary classification task where each input protein x is mapped to a label y ∈ {0, 1}, corresponding to either membrane-bound or soluble. The dataset is from DeepLoc research, employing all proteins with AF2 structures, and split based on 70% structure similarity. The dataset is divided into training, validation, and test sets with the numbers 6707, 698, and 807, respectively. The data is organized in LMDB format, containing the UniProt ID of the protein, the structure-aware sequence, and the classification label.
提供机构:
SaProtHub
原始信息汇总
数据集概述
数据集描述
- 任务类型: 二元分类任务
- 目标: 预测蛋白质是“膜结合型”(0)还是“可溶型”(1)
- 标签定义:
- 0: 膜结合型
- 1: 可溶型
数据集分割
- 结构类型: AF2
- 数据来源: DeepLoc: prediction of protein subcellular localization using deep learning
- 分割依据: 基于70%结构相似性
- 分割详情:
- 训练集:6707
- 验证集:698
- 测试集:807
数据格式
- 存储格式: LMDB
- 数据结构:
- 长度: 样本数量
- 样本详情:
- 名称: 蛋白质的UniProt ID
- 序列: 结构感知序列
- pLDDT值: 所有位置的pLDDT值
- 标签: 序列的分类标签
搜集汇总
数据集介绍
构建方式
在蛋白质生物信息学领域,精准的亚细胞定位预测对于理解蛋白质功能至关重要。该数据集源自DeepLoc研究,专注于二元定位分类任务,旨在区分膜结合蛋白与可溶性蛋白。其构建过程首先从DeepLoc原始数据中筛选出所有具备AlphaFold2预测结构的蛋白质序列,随后依据70%的结构相似性阈值,借助ProteinShake框架进行划分,确保了训练集、验证集与测试集在结构特征上的独立性,最终形成了包含6707个训练样本、698个验证样本及807个测试样本的标准化集合。
使用方法
在蛋白质功能预测的实际应用中,该数据集为开发与评估深度学习模型提供了标准基准。使用者可直接加载提供的CSV文件,利用其中的SA序列作为模型输入,对应的二元标签作为监督信号。建议遵循预设的训练、验证与测试划分进行模型训练与超参数调优,最终在独立的测试集上评估分类性能,如准确率、精确率与召回率等指标,以推动膜蛋白识别与亚细胞定位预测领域的方法学研究。
背景与挑战
背景概述
在计算生物学领域,蛋白质亚细胞定位预测是理解蛋白质功能与调控机制的关键环节。DeepLoc数据集由Almagro Armenteros等人于2017年创建,依托哥本哈根大学等研究机构,旨在通过深度学习技术精准预测蛋白质的亚细胞位置。该数据集聚焦于二元定位分类问题,即将蛋白质划分为膜结合型或可溶型,为后续功能注释及药物靶点发现提供了重要数据基础,显著推动了生物信息学中结构感知预测模型的发展。
当前挑战
DeepLoc数据集致力于解决蛋白质亚细胞定位中的二元分类挑战,即准确区分膜结合与可溶蛋白,这对模型处理复杂序列与结构特征的能力提出了较高要求。在构建过程中,数据集需整合AlphaFold2预测的结构数据,并依据70%的结构相似性进行划分,以确保训练与测试集间的独立性,同时需剔除缺乏可靠结构的蛋白质,这增加了数据清洗与标准化的复杂性。
常用场景
经典使用场景
在计算生物学领域,蛋白质亚细胞定位预测是理解蛋白质功能与调控机制的关键环节。SaProtHub/Dataset-Binary_Localization-DeepLoc数据集专注于二元定位分类任务,将蛋白质序列映射至“膜结合”或“可溶性”标签。该数据集基于AlphaFold2预测的结构数据构建,通过70%结构相似性划分训练、验证与测试集,为深度学习模型提供了标准化的评估基准,广泛应用于蛋白质功能注释与结构生物信息学研究。
解决学术问题
该数据集有效解决了蛋白质亚细胞定位预测中的二元分类挑战,为膜蛋白与可溶性蛋白的区分提供了高质量的结构化数据。通过整合AlphaFold2预测的蛋白质三维结构,它克服了传统序列方法在结构特征提取上的局限,推动了基于深度学习的定位模型发展。其意义在于提升了预测精度与泛化能力,为细胞生物学、药物靶点发现等研究提供了可靠的计算工具,加速了蛋白质功能机制的解析进程。
实际应用
在实际应用中,该数据集支撑了生物医学研究与工业开发的多个场景。在药物研发中,它帮助识别膜结合蛋白作为潜在药物靶点,优化候选化合物的筛选效率。在合成生物学领域,可用于设计具有特定定位特性的工程蛋白,提升代谢通路效率。此外,在疾病机理研究中,该数据集辅助分析蛋白质错误定位与神经退行性疾病、癌症等病理过程的关联,为精准医疗提供数据基础。
数据集最近研究
最新研究方向
在蛋白质组学领域,基于深度学习的亚细胞定位预测已成为结构生物信息学的前沿热点。SaProtHub/Dataset-Binary_Localization-DeepLoc数据集整合了AlphaFold2预测的蛋白质结构,将定位任务简化为膜结合与可溶性的二元分类,为模型效率与泛化能力研究提供了基准。当前研究聚焦于利用图神经网络与注意力机制,从三维构象中提取拓扑特征,以提升跨物种定位预测的准确性。这一方向与精准医疗及药物靶点发现紧密关联,推动了蛋白质功能注释的自动化进程,对理解疾病机制与开发新型疗法具有深远意义。
以上内容由遇见数据集搜集并总结生成


