ragtime2
收藏Hugging Face2026-05-05 更新2026-05-06 收录
下载链接:
https://huggingface.co/datasets/trec-ragtime/ragtime2
下载链接
链接失效反馈官方服务:
资源简介:
RAGTIME2数据集是为TREC RAGTIME Track 2026设计的文档集合,支持多语言检索与生成任务(RAG)。该数据集包含从Common Crawl News中提取的新闻文档,时间跨度为2021年8月1日至2024年7月31日,每天均匀采样。数据集涵盖四种语言(阿拉伯语、英语、西班牙语、中文),每种语言包含1,000,095个文档,并按语言分为独立的JSONL文件。此外,数据集还提供了使用HLTCOE训练的Sockeye模型生成的机器翻译版本。RAGTIME任务要求系统从所有四种语言中检索相关文档,并根据报告请求生成带有引用的响应。数据集适用于多语言文本检索、文档检索及生成任务,采用CC-BY-SA-4.0许可协议。
The RAGTIME2 dataset is a document collection designed for the TREC RAGTIME Track 2026, supporting multilingual retrieval and generation tasks (RAG). It contains news documents extracted from Common Crawl News, with a time span from August 1, 2021, to July 31, 2024, sampled uniformly each day. The dataset covers four languages (Arabic, English, Spanish, Chinese), with each language containing 1,000,095 documents, divided into separate JSONL files by language. Additionally, the dataset provides machine-translated versions generated using the Sockeye model trained by HLTCOE. The RAGTIME task requires systems to retrieve relevant documents from all four languages and generate responses with citations based on report requests. The dataset is suitable for multilingual text retrieval, document retrieval, and generation tasks, and is licensed under CC-BY-SA-4.0.
创建时间:
2026-05-04
原始信息汇总
RAGTIME2 数据集概述
数据集名称: RAGTIME2
数据集来源: TREC RAGTIME Track 2026 任务
许可协议: CC-BY-SA-4.0
任务类型与用途
- 任务类别: 文本检索(text-retrieval)
- 具体任务: 文档检索(document-retrieval)
- 核心用途: 多语言检索增强生成(RAG),要求系统从四种语言中检索相关文档,并基于报告请求生成带引用的回答。
多语言信息
- 支持语言: 阿拉伯语(ar)、英语(en)、西班牙语(es)、中文(zh)
- 语言类型: 多语言(multilingual)
- 标注方式: 无人工标注(no-annotation)
- 数据来源: 基于 Common Crawl News 数据扩展自 C4 数据集
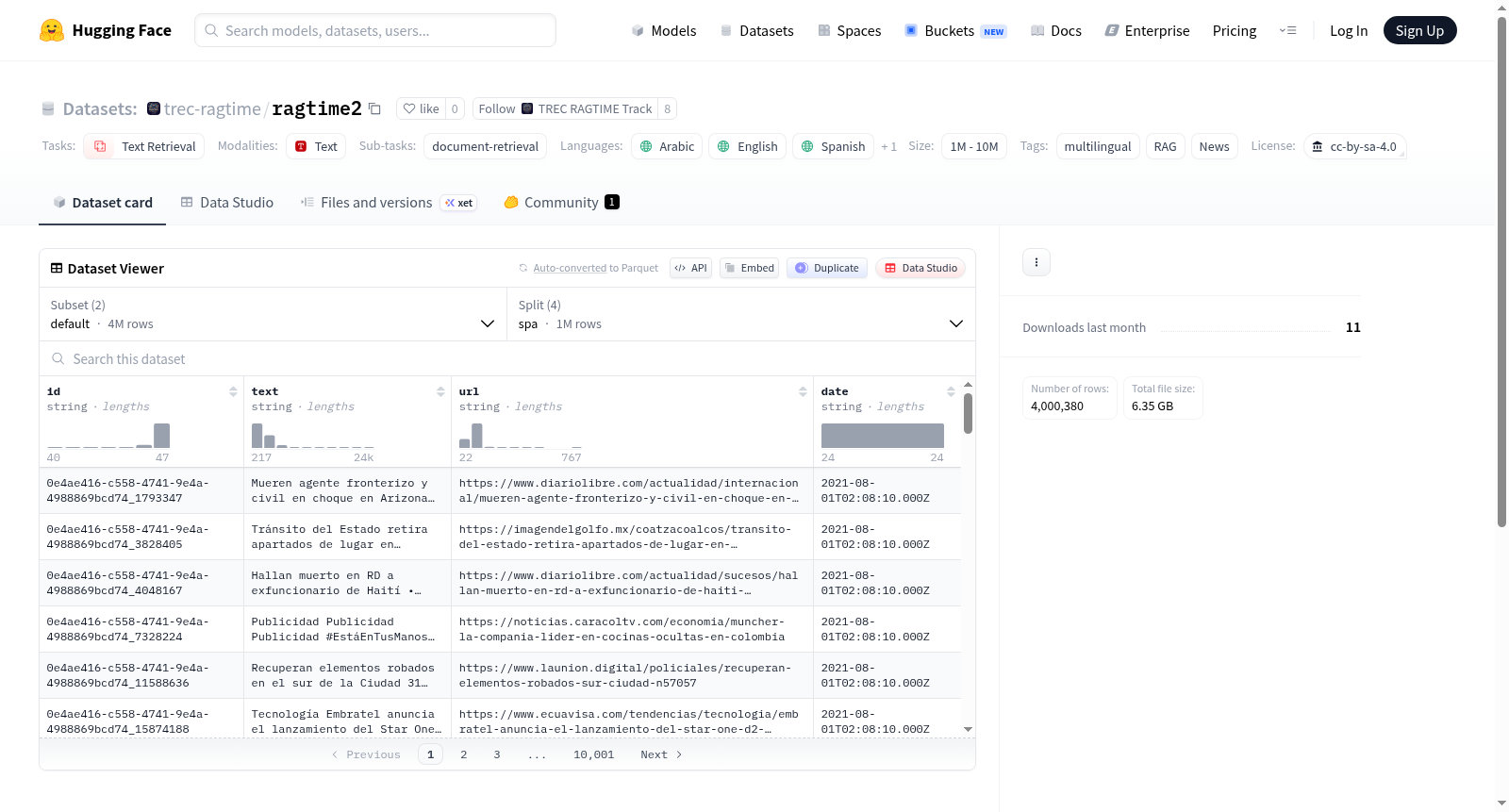
数据规模与结构
- 文档总量: 4,000,380 篇(每种语言 1,000,095 篇)
- 时间范围: 2021年8月1日至2024年7月31日,每日均匀采样
- 数据分割:
- 默认配置(default):
- 西班牙语文档:
spa-docs.jsonl - 俄语文档:
rus-docs.jsonl - 中文文档:
zho-docs.jsonl - 英语文档:
eng-docs.jsonl
- 西班牙语文档:
- 机器翻译配置(mt_docs):
- 西班牙语→英语翻译:
spa-trans.jsonl - 俄语→英语翻译:
rus-trans.jsonl - 中文→英语翻译:
zho-trans.jsonl - (注:翻译模型为 HLTCOE 训练的 Sockeye 模型)
- 西班牙语→英语翻译:
- 默认配置(default):
关键说明
- 数据集中的文档按语言分散在四个文件中,但实际使用时需作为整体检索。
- 所有文档均来自 Common Crawl 新闻语料,确保每日均匀分布。
搜集汇总
数据集介绍
构建方式
RAGTIME2数据集专为TREC RAGTIME评测任务中的多语言检索增强生成(RAG)场景而构建,其语料源自Common Crawl News语料库,时间跨度自2021年8月1日至2024年7月31日,每日均匀采样以确保时序代表性。数据集涵盖阿拉伯语、英语、西班牙语和中文四种语言,每种语言均收录1,000,095篇文档,分别以独立的JSONL文件存储。为支持跨语言研究,还提供了经由HLTCOE训练的Sockeye模型进行机器翻译的译文版本,形成辅助文档集。整个构建过程无需人工标注,充分依托已有的大规模新闻语料与自动翻译技术。
使用方法
使用RAGTIME2时,用户可依据评测任务直接加载各语言的原始文档文件(eng、spa、rus、zho)作为检索库,或结合机器翻译版本(如spa.mt.eng)进行跨语言实验。推荐通过HuggingFace Datasets库按语言配置加载,例如指定config_name为'default'读取原始文档,或使用'mt_docs'获取翻译文档。检索系统需接收多语言查询,并在全语料范围内返回相关文档片段,而后由生成模型依据检索结果合成最终回答。文档以JSONL格式存储,每行含文本内容及相关元数据,便于进行分块、索引与批量处理。
背景与挑战
背景概述
RAGTIME2数据集诞生于检索增强生成(RAG)技术迅速发展的背景下,旨在为多语言RAG任务提供标准化评估基准。该数据集由TREC RAGTIME Track于2026年发布,其核心研究问题在于评测系统能否跨越阿拉伯语、英语、西班牙语和中文四种语言,检索并整合相关信息,以生成带有引证的准确回答。数据源于Common Crawl新闻语料,采样时间跨度达三年(2021年8月至2024年7月),确保了内容的时效性与多样性。通过提供每种语言约100万篇文档,RAGTIME2不仅推动了多语言信息检索与生成融合的研究,还为评估系统在真实新闻环境下的跨语言理解与推理能力奠定了坚实基础。
当前挑战
该数据集面临的核心挑战在于解决多语言RAG任务中的跨语言语义鸿沟问题,即如何让模型在语言、文化背景迥异的文档库中精准定位并关联同一事件或实体的多语种描述,同时避免因翻译偏差或文化特异性导致的信息丢失。构建过程中,挑战主要体现在数据平衡与质量把控上:需确保每日采样文档数量均等以消除时间偏差,并利用Sockeye模型进行机器翻译时需克服低资源语言对(如中文-英语)的翻译误差,以及不同语言新闻体裁的文体差异可能引发的表示偏移。此外,如何在无人工标注的条件下构建可靠的检索相关性评估准则,亦是数据集设计中的关键难题。
常用场景
经典使用场景
RAGTIME2数据集专为多语言检索增强生成(RAG)任务而设计,其经典使用场景在于模拟真实世界中信息的多语种混杂特性。该数据集汇集了阿拉伯语、英语、西班牙语和中文四种语言的新闻文档,覆盖自2021年8月至2024年7月均匀采样的海量语料,每语言包含约100万篇文档。研究者可利用此数据集构建能够跨语言检索并融合多源信息生成答案的系统,尤其适用于需要从不同语言渠道整合事实性报道的任务,为验证多语言检索与生成模型的协同能力提供了标准化基准。
解决学术问题
该数据集的问世着力解决多语言RAG领域长期存在的两大核心学术痛点:其一,现有RAG基准多聚焦于单语场景,难以评估模型处理真实世界多语言混杂信息的鲁棒性;其二,缺乏大规模、时间跨度一致的跨语言检索标准评估平台。RAGTIME2通过提供四语平行语料并附以机器翻译版本,为学者系统探究跨语言文档检索、多源信息冲突消解、以及引用生成等复杂问题提供了可复现的实验框架。其深远意义在于推动了从单语RAG向多语言、多文化知识融合范式的关键转型,为构建真正意义上的全球性知识问答系统奠定了数据基础。
实际应用
在实际部署中,RAGTIME2可广泛应用于多语言新闻聚合与事实核查系统,支持从不同语种来源自动检索与报道主题相关的证据片段,并生成带引用的综合性响应。例如,国际舆情监测平台可利用该数据集训练模型,使其能够同时检索阿拉伯语、中文、西班牙语和英文的新闻文章,快速生成跨区域事件报告。此外,在跨国企业知识管理、多语言客服问答、以及全球政策分析等场景中,基于该数据集开发的多语言RAG系统能够显著提升信息整合效率,降低人工跨语言检索成本。
数据集最近研究
最新研究方向
RAGTIME2数据集聚焦于多语言检索增强生成(RAG)的前沿探索,通过整合阿拉伯语、英语、西班牙语与中文四语种新闻语料,构建了跨语言文档检索与答案生成的评估基准。该数据集从Common Crawl News中抽取2021至2024年间均匀分布式覆盖每日约百万篇文档,结合机器翻译技术提供了双语迁移能力,旨在推动系统在无标注条件下实现多源异构信息的语义对齐与可信溯源。其设计呼应了当前RAG技术在知识密集型任务中对跨语言理解与引用准确性的严苛需求,为应对全球化信息检索中语言障碍与事实一致性挑战提供了关键测试平台,有望加速多语言智能问答与证据性语言生成的产业化落地。
以上内容由遇见数据集搜集并总结生成


