MOVE
收藏arXiv2025-07-30 更新2025-07-31 收录
下载链接:
https://henghuiding.com/MOVE/
下载链接
链接失效反馈官方服务:
资源简介:
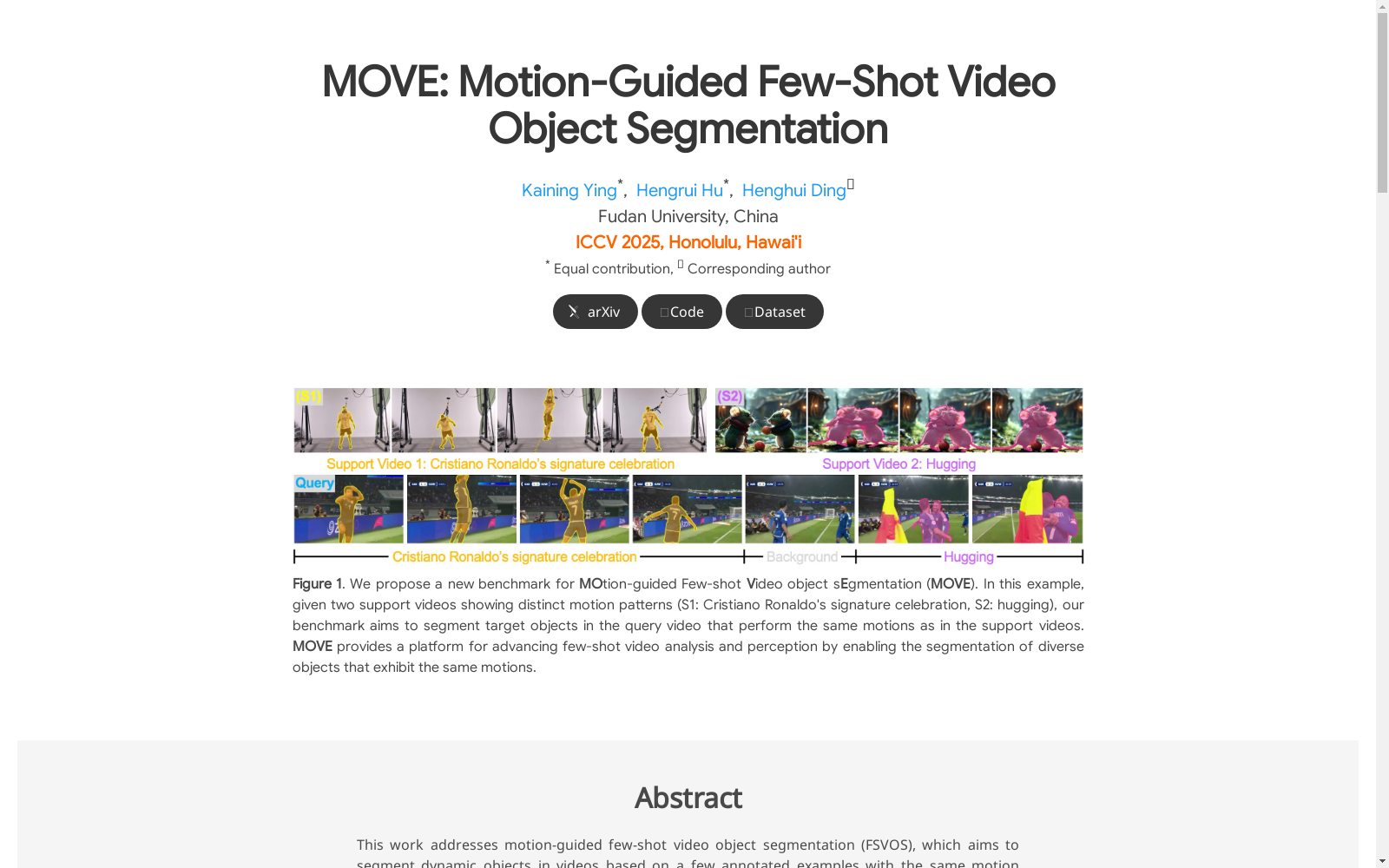
MOVE数据集是一个大规模的运动引导式少样本视频对象分割数据集,由复旦大学创建。该数据集包含224个动作类别,4300个视频,共计261,920帧,以及314,619个高质量分割掩模,注释了5,135个对象,跨越88个对象类别。数据集旨在捕捉多样化的运动模式,促进以运动为中心的少样本视频对象分割方法的发展与评估。
The MOVE Dataset is a large-scale motion-guided few-shot video object segmentation dataset created by Fudan University. It includes 224 action categories, 4,300 videos totaling 261,920 frames, and 314,619 high-quality segmentation masks. A total of 5,135 objects spanning 88 object categories have been annotated in this dataset. This dataset aims to capture diverse motion patterns, and facilitate the development and evaluation of motion-centric few-shot video object segmentation methods.
提供机构:
复旦大学, 中国
创建时间:
2025-07-30
原始信息汇总
MOVE: Motion-Guided Few-Shot Video Object Segmentation 数据集概述
基本信息
- 论文标题: MOVE: Motion-Guided Few-Shot Video Object Segmentation
- 作者: Kaining Ying*, Hengrui Hu*, Henghui Ding✉️ (Fudan University, China)
- 会议: ICCV 2025, Honolulu, Hawaii
- 代码与数据集: arXiv 🔥Code 🔥Dataset
数据集简介
- 目标: 解决基于运动引导的少样本视频对象分割(FSVOS)问题,通过少量标注示例分割具有相同运动模式的动态对象。
- 特点: 专注于运动模式而非静态对象类别,填补现有数据集在运动理解方面的空白。
数据集统计
- 标签类型: Motion
- 标注类型: Mask
- 支持类型: Video
- 类别数: 224(涵盖日常动作、体育、娱乐活动和特殊动作)
- 视频数: 4,300
- 对象数: 5,135
- 帧数: 261,920
- 掩码数: 314,619
对比其他数据集
| Dataset | Venue | Label Type | Annotation | Support Type | Categories | Videos | Objects | Frames | Masks |
|---|---|---|---|---|---|---|---|---|---|
| FSVOD-500 | ECCV22 | Object | Box | Image | 500 | 42,72 | 96,609 | 104,495 | 104,507 |
| YouTube-VIS | ICCV19 | Object | Mask | Image | 40 | 2,238 | 3,774 | 61,845 | 97,110 |
| MiniVSPW | IJCV25 | Object | Mask | Image | 20 | 2,471 | - | 541,007 | - |
| MOVE | ICCV25 | Motion | Mask | Video | 224 | 4,300 | 5,135 | 261,920 | 314,619 |
可视化示例
- 多样化运动类别: Cross, Heimlich, Hugging, Spinning Plate, Stacking Dice, Waacking, Yoga Pigeon, Siu。
- 相同运动的不同对象:
- Hugging: Person, Fox
- Metamorphosis: Person, Horse
- Shake: Person, Animal
- Siu: Person, Robot
基准方法: DMA
- 方法名称: Decoupled Motion-Appearance Network (DMA)
- 主要组件:
- 共享编码器
- 提案生成器
- 共享DMA模块
- 原型注意力模块
- 掩码解码器
实验结果
- 评估设置:
- Overlapping Split (OS)
- Non-overlapping Split (NS)
- 结果: DMA方法在两种设置下均优于现有方法。
引用
bibtex @inproceedings{ying2025move, title={{MOVE}: {M}otion-{G}uided {F}ew-{S}hot {V}ideo {O}bject {S}egmentation}, author={Kaining Ying and Hengrui Hu and Henghui Ding}, year={2025}, booktitle={ICCV} }
© FudanCVL | Last updated: 28/07/2025
搜集汇总
数据集介绍
构建方式
MOVE数据集的构建基于对视频中动态对象的运动模式进行精细标注的理念,通过收集来自公开动作识别数据集和互联网视频的素材,确保了数据的多样性和广泛性。在视频选择过程中,特别注重动作边界的清晰性、场景的多样性以及主体类别的丰富性。对于没有预先生成分割掩码的视频,由经过专业训练的标注人员在交互式标注平台上借助先进的视频对象分割模型进行高质量标注。整个数据集包含224个动作类别,覆盖日常行为、体育、娱乐活动和特殊动作四大领域,共计4,300个视频片段、261,920帧图像和314,619个高质量分割掩码。
使用方法
MOVE数据集的使用方法主要围绕运动导向的少样本视频对象分割任务展开。研究者在实验设计时可以采用交叉验证的方式,将224个动作类别划分为4个折叠,并根据节点级运动分布采用重叠分割和非重叠分割两种策略。评估指标包括衡量分割质量的J&F指标(结合IoU和轮廓准确率)以及针对空前景样本的鲁棒性指标N-Acc和T-Acc。在模型训练过程中,建议采用交叉熵损失和IoU损失的组合进行优化,并可使用余弦退火调度器调整学习率。数据集支持1-way-1-shot到N-way-K-shot等多种实验设置,为运动理解研究提供了灵活的实验平台。
背景与挑战
背景概述
MOVE(Motion-Guided Few-Shot Video Object Segmentation)数据集由复旦大学的研究团队于2025年提出,旨在解决基于运动模式的少样本视频对象分割问题。该数据集包含224个运动类别、4,300个视频片段和314,619个高质量分割掩码,覆盖日常行为、体育、娱乐活动和特殊动作等多个领域。MOVE的提出填补了传统少样本视频对象分割(FSVOS)方法在动态运动理解上的空白,将研究焦点从静态对象类别转向动态运动模式,为视频分析和感知领域提供了新的研究平台。MOVE的创建推动了少样本学习在复杂运动理解中的应用,尤其在自动驾驶、机器人和增强现实等领域具有重要影响力。
当前挑战
MOVE数据集面临的核心挑战包括:1) 运动模式理解的复杂性,要求模型从视频序列中全面分析动态信息,而非依赖静态单帧语义识别;2) 运动相关原型的有效提取,现有方法主要关注语义特征而忽略支持视频中的动态信息;3) 数据构建过程中,精细运动边界的标注和高多样性场景的覆盖增加了数据集的构建难度。这些挑战促使研究者开发新的方法,如解耦运动-外观原型提取机制,以提升模型在少样本运动理解上的性能。
常用场景
经典使用场景
MOVE数据集专注于运动引导的少样本视频对象分割(FSVOS),其经典使用场景包括基于运动模式而非静态对象类别的视频对象分割。例如,给定一个支持视频展示特定的运动模式(如C罗的标志性庆祝动作),模型需要在查询视频中分割出执行相同运动的目标对象,无论其所属的对象类别如何。这一场景在需要理解动态运动模式而非静态对象属性的任务中尤为重要。
解决学术问题
MOVE数据集解决了传统少样本视频对象分割方法中过度依赖静态对象类别的局限性。通过强调运动模式的理解,该数据集推动了从静态语义识别向动态时间建模的转变。其意义在于填补了现有FSVOS数据集在时间动态性方面的空白,为研究运动理解在视频分割中的作用提供了重要平台。这一突破对视频分析领域的影响深远,为复杂场景下的运动感知任务奠定了基础。
实际应用
在实际应用中,MOVE数据集可广泛应用于视频检索、监控分析和增强现实等领域。例如,在体育视频分析中,系统可以基于特定运动员的独特动作(如庆祝动作)快速定位并分割相关片段;在安防监控中,可根据异常行为模式(如跌倒或快速奔跑)识别潜在危险情况。这些应用场景展示了运动理解在现实世界中的实用价值。
数据集最近研究
最新研究方向
近年来,MOVE数据集在计算机视觉领域引起了广泛关注,特别是在基于运动引导的少样本视频对象分割(FSVOS)任务中。该数据集通过强调动态运动模式而非静态对象类别,为视频分析开辟了新的研究方向。前沿研究主要集中在如何有效提取和匹配运动原型,以解决复杂场景下的对象分割问题。热点事件包括利用Transformer架构增强时间建模能力,以及探索多模态融合技术在运动理解中的应用。MOVE的影响不仅体现在推动了少样本学习的发展,还为自动驾驶、机器人技术和增强现实等实际应用提供了重要支持。其意义在于填补了现有数据集中动态信息建模的空白,为未来研究奠定了坚实基础。
相关研究论文
- 1MOVE: Motion-Guided Few-Shot Video Object Segmentation复旦大学, 中国 · 2025年
以上内容由遇见数据集搜集并总结生成


