MergeBench
收藏arXiv2025-05-16 更新2025-05-20 收录
下载链接:
https://github.com/uiuctml/MergeBench
下载链接
链接失效反馈官方服务:
资源简介:
MergeBench是一个全面的评估套件,旨在评估模型合并的性能。它基于最先进的开源语言模型,包括2B到9B规模的Llama和Gemma系列,涵盖了五个关键领域:指令遵循、数学、多语言理解、编码和安全。MergeBench标准化了微调和评估协议,并评估了八个代表性合并方法在多任务性能、遗忘和运行时效率方面的表现。
MergeBench is a comprehensive evaluation suite designed to assess the performance of model merging. It is based on state-of-the-art open-source language models, including Llama and Gemma model families with parameter sizes ranging from 2B to 9B, and covers five key domains: instruction following, mathematics, multilingual understanding, coding, and safety. MergeBench standardizes fine-tuning and evaluation protocols, and evaluates eight representative model merging methods across multi-task performance, forgetting, and runtime efficiency.
提供机构:
伊利诺伊大学厄巴纳-香槟分校
创建时间:
2025-05-16
搜集汇总
数据集介绍
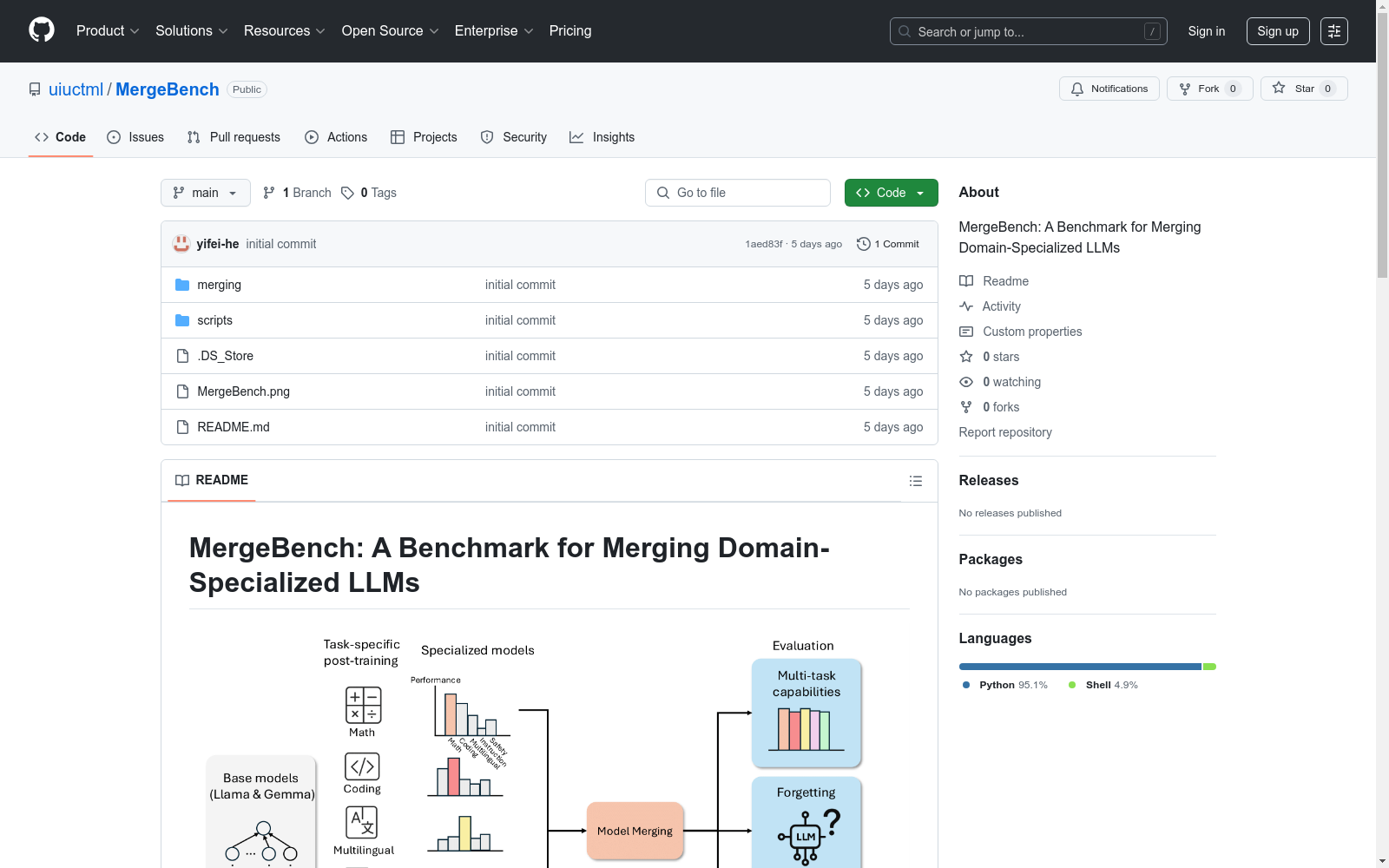
构建方式
MergeBench的构建基于前沿的开源语言模型,包括Llama和Gemma系列,规模从2B到9B不等。研究团队首先对这些基础模型进行了任务特定的后训练,覆盖了五个关键领域:指令遵循、数学、多语言理解、编程和安全。通过标准化的微调和评估协议,确保了数据集的公平性和可重复性。此外,团队还评估了八种代表性的模型合并方法,涵盖了多任务性能、遗忘和运行时效率等多个维度。
特点
MergeBench数据集的特点在于其广泛的任务覆盖和模型多样性。它不仅包含了多个领域的任务,还采用了不同规模和类型的语言模型,从而提供了一个全面评估模型合并方法的平台。数据集特别关注了模型合并后的知识保留能力和计算效率,为研究者提供了丰富的实验数据。此外,MergeBench还开源了所有代码和模型,便于后续研究的复现和扩展。
使用方法
使用MergeBench数据集时,研究者可以通过标准化的评估流程来比较不同模型合并方法的性能。数据集提供了详细的微调和合并协议,用户可以根据需要选择不同的任务和模型进行实验。此外,MergeBench还包含了丰富的评估指标和工具,帮助用户全面分析合并模型的性能、遗忘情况和计算效率。数据集的开源性也使得用户可以自由地扩展和定制实验设置。
背景与挑战
背景概述
MergeBench是由伊利诺伊大学厄巴纳-香槟分校的研究团队于2025年推出的一个专注于评估领域专用大语言模型(LLMs)合并效果的基准测试套件。该数据集基于最先进的开源语言模型(如Llama和Gemma系列),覆盖了五个关键领域:指令遵循、数学、多语言理解、编程和安全性。MergeBench的创建旨在解决现有评估在模型规模和任务多样性上的局限性,为模型合并技术的研究和应用提供了标准化、可复现的评估平台。
当前挑战
MergeBench面临的挑战主要包括三个方面:1) 领域问题方面,模型合并需要解决多任务性能与知识保留之间的平衡问题,尤其是在处理大规模、高复杂度的领域专用模型时;2) 构建过程中,数据集需要克服模型质量参差不齐、技能覆盖不全以及模型间兼容性等技术难题;3) 计算效率方面,大规模模型的合并过程会产生显著的计算成本,且超参数调优的效率问题亟待优化。
常用场景
经典使用场景
MergeBench作为一个专注于评估领域专用大型语言模型(LLM)合并效果的基准测试,其经典使用场景包括多任务模型的构建与优化。研究者通过该数据集可以系统地评估不同模型合并算法在数学、编程、多语言理解、指令遵循和安全性等五个关键领域的表现。例如,在构建一个能够同时处理数学推理和代码生成任务的统一模型时,MergeBench提供了标准化的评估框架,帮助研究者比较不同合并方法(如参数算术平均或稀疏化技术)的效果。
衍生相关工作
围绕MergeBench衍生的经典工作包括三大方向:一是模型压缩领域对TIES-Merging算法的改进,通过引入动态稀疏阈值提升多任务性能;二是多模态研究中受任务向量算术启发发展的跨模态模型融合方法;三是在安全对齐领域提出的基于共识掩码的知识保留技术。这些工作均引用MergeBench作为基础评估平台,其中Localize-and-Stitch及其数据无关变体已成为模型合并领域的基准方法,相关论文获NeurIPS等顶会最佳论文奖提名。
数据集最近研究
最新研究方向
在大型语言模型(LLM)领域,模型合并技术作为一种高效的多任务学习替代方案,近年来受到广泛关注。MergeBench数据集的提出填补了现有评估在模型规模和任务多样性方面的不足,为领域专用LLM的合并提供了全面的评估框架。当前研究聚焦于探索模型合并算法在多任务性能、知识保留和计算效率之间的平衡,特别是在Llama和Gemma等开源模型家族上的应用。前沿方向包括优化合并系数调整和稀疏化技术以减少知识遗忘,以及降低大规模模型合并的计算成本。此外,模型合并与标准LLM训练流程的整合,及其在低资源或数据不平衡场景下的优势,也成为研究热点。MergeBench的开源为未来研究奠定了重要基础,推动了模型合并技术在实践中的广泛应用。
相关研究论文
- 1MergeBench: A Benchmark for Merging Domain-Specialized LLMs伊利诺伊大学厄巴纳-香槟分校 · 2025年
以上内容由遇见数据集搜集并总结生成


