mozilla-foundation/common_voice_11_0
收藏Hugging Face2023-06-26 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/mozilla-foundation/common_voice_11_0
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
license:
- cc0-1.0
multilinguality:
- multilingual
size_categories:
ab:
- 10K<n<100K
ar:
- 100K<n<1M
as:
- 1K<n<10K
ast:
- n<1K
az:
- n<1K
ba:
- 100K<n<1M
bas:
- 1K<n<10K
be:
- 100K<n<1M
bg:
- 1K<n<10K
bn:
- 100K<n<1M
br:
- 10K<n<100K
ca:
- 1M<n<10M
ckb:
- 100K<n<1M
cnh:
- 1K<n<10K
cs:
- 10K<n<100K
cv:
- 10K<n<100K
cy:
- 100K<n<1M
da:
- 1K<n<10K
de:
- 100K<n<1M
dv:
- 10K<n<100K
el:
- 10K<n<100K
en:
- 1M<n<10M
eo:
- 1M<n<10M
es:
- 1M<n<10M
et:
- 10K<n<100K
eu:
- 100K<n<1M
fa:
- 100K<n<1M
fi:
- 10K<n<100K
fr:
- 100K<n<1M
fy-NL:
- 10K<n<100K
ga-IE:
- 1K<n<10K
gl:
- 10K<n<100K
gn:
- 1K<n<10K
ha:
- 1K<n<10K
hi:
- 10K<n<100K
hsb:
- 1K<n<10K
hu:
- 10K<n<100K
hy-AM:
- 1K<n<10K
ia:
- 10K<n<100K
id:
- 10K<n<100K
ig:
- 1K<n<10K
it:
- 100K<n<1M
ja:
- 10K<n<100K
ka:
- 10K<n<100K
kab:
- 100K<n<1M
kk:
- 1K<n<10K
kmr:
- 10K<n<100K
ky:
- 10K<n<100K
lg:
- 100K<n<1M
lt:
- 10K<n<100K
lv:
- 1K<n<10K
mdf:
- n<1K
mhr:
- 100K<n<1M
mk:
- n<1K
ml:
- 1K<n<10K
mn:
- 10K<n<100K
mr:
- 10K<n<100K
mrj:
- 10K<n<100K
mt:
- 10K<n<100K
myv:
- 1K<n<10K
nan-tw:
- 10K<n<100K
ne-NP:
- n<1K
nl:
- 10K<n<100K
nn-NO:
- n<1K
or:
- 1K<n<10K
pa-IN:
- 1K<n<10K
pl:
- 100K<n<1M
pt:
- 100K<n<1M
rm-sursilv:
- 1K<n<10K
rm-vallader:
- 1K<n<10K
ro:
- 10K<n<100K
ru:
- 100K<n<1M
rw:
- 1M<n<10M
sah:
- 1K<n<10K
sat:
- n<1K
sc:
- 1K<n<10K
sk:
- 10K<n<100K
skr:
- 1K<n<10K
sl:
- 10K<n<100K
sr:
- 1K<n<10K
sv-SE:
- 10K<n<100K
sw:
- 100K<n<1M
ta:
- 100K<n<1M
th:
- 100K<n<1M
ti:
- n<1K
tig:
- n<1K
tok:
- 1K<n<10K
tr:
- 10K<n<100K
tt:
- 10K<n<100K
tw:
- n<1K
ug:
- 10K<n<100K
uk:
- 10K<n<100K
ur:
- 100K<n<1M
uz:
- 100K<n<1M
vi:
- 10K<n<100K
vot:
- n<1K
yue:
- 10K<n<100K
zh-CN:
- 100K<n<1M
zh-HK:
- 100K<n<1M
zh-TW:
- 100K<n<1M
source_datasets:
- extended|common_voice
task_categories:
- automatic-speech-recognition
task_ids: []
paperswithcode_id: common-voice
pretty_name: Common Voice Corpus 11.0
language_bcp47:
- ab
- ar
- as
- ast
- az
- ba
- bas
- be
- bg
- bn
- br
- ca
- ckb
- cnh
- cs
- cv
- cy
- da
- de
- dv
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy-NL
- ga-IE
- gl
- gn
- ha
- hi
- hsb
- hu
- hy-AM
- ia
- id
- ig
- it
- ja
- ka
- kab
- kk
- kmr
- ky
- lg
- lt
- lv
- mdf
- mhr
- mk
- ml
- mn
- mr
- mrj
- mt
- myv
- nan-tw
- ne-NP
- nl
- nn-NO
- or
- pa-IN
- pl
- pt
- rm-sursilv
- rm-vallader
- ro
- ru
- rw
- sah
- sat
- sc
- sk
- skr
- sl
- sr
- sv-SE
- sw
- ta
- th
- ti
- tig
- tok
- tr
- tt
- tw
- ug
- uk
- ur
- uz
- vi
- vot
- yue
- zh-CN
- zh-HK
- zh-TW
extra_gated_prompt: By clicking on “Access repository” below, you also agree to not
attempt to determine the identity of speakers in the Common Voice dataset.
---
# Dataset Card for Common Voice Corpus 11.0
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [How to use](#how-to-use)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://commonvoice.mozilla.org/en/datasets
- **Repository:** https://github.com/common-voice/common-voice
- **Paper:** https://arxiv.org/abs/1912.06670
- **Leaderboard:** https://paperswithcode.com/dataset/common-voice
- **Point of Contact:** [Anton Lozhkov](mailto:anton@huggingface.co)
### Dataset Summary
The Common Voice dataset consists of a unique MP3 and corresponding text file.
Many of the 24210 recorded hours in the dataset also include demographic metadata like age, sex, and accent
that can help improve the accuracy of speech recognition engines.
The dataset currently consists of 16413 validated hours in 100 languages, but more voices and languages are always added.
Take a look at the [Languages](https://commonvoice.mozilla.org/en/languages) page to request a language or start contributing.
### Supported Tasks and Leaderboards
The results for models trained on the Common Voice datasets are available via the
[🤗 Autoevaluate Leaderboard](https://huggingface.co/spaces/autoevaluate/leaderboards?dataset=mozilla-foundation%2Fcommon_voice_11_0&only_verified=0&task=automatic-speech-recognition&config=ar&split=test&metric=wer)
### Languages
```
Abkhaz, Arabic, Armenian, Assamese, Asturian, Azerbaijani, Basaa, Bashkir, Basque, Belarusian, Bengali, Breton, Bulgarian, Cantonese, Catalan, Central Kurdish, Chinese (China), Chinese (Hong Kong), Chinese (Taiwan), Chuvash, Czech, Danish, Dhivehi, Dutch, English, Erzya, Esperanto, Estonian, Finnish, French, Frisian, Galician, Georgian, German, Greek, Guarani, Hakha Chin, Hausa, Hill Mari, Hindi, Hungarian, Igbo, Indonesian, Interlingua, Irish, Italian, Japanese, Kabyle, Kazakh, Kinyarwanda, Kurmanji Kurdish, Kyrgyz, Latvian, Lithuanian, Luganda, Macedonian, Malayalam, Maltese, Marathi, Meadow Mari, Moksha, Mongolian, Nepali, Norwegian Nynorsk, Odia, Persian, Polish, Portuguese, Punjabi, Romanian, Romansh Sursilvan, Romansh Vallader, Russian, Sakha, Santali (Ol Chiki), Saraiki, Sardinian, Serbian, Slovak, Slovenian, Sorbian, Upper, Spanish, Swahili, Swedish, Taiwanese (Minnan), Tamil, Tatar, Thai, Tigre, Tigrinya, Toki Pona, Turkish, Twi, Ukrainian, Urdu, Uyghur, Uzbek, Vietnamese, Votic, Welsh
```
## How to use
The `datasets` library allows you to load and pre-process your dataset in pure Python, at scale. The dataset can be downloaded and prepared in one call to your local drive by using the `load_dataset` function.
For example, to download the Hindi config, simply specify the corresponding language config name (i.e., "hi" for Hindi):
```python
from datasets import load_dataset
cv_11 = load_dataset("mozilla-foundation/common_voice_11_0", "hi", split="train")
```
Using the datasets library, you can also stream the dataset on-the-fly by adding a `streaming=True` argument to the `load_dataset` function call. Loading a dataset in streaming mode loads individual samples of the dataset at a time, rather than downloading the entire dataset to disk.
```python
from datasets import load_dataset
cv_11 = load_dataset("mozilla-foundation/common_voice_11_0", "hi", split="train", streaming=True)
print(next(iter(cv_11)))
```
*Bonus*: create a [PyTorch dataloader](https://huggingface.co/docs/datasets/use_with_pytorch) directly with your own datasets (local/streamed).
### Local
```python
from datasets import load_dataset
from torch.utils.data.sampler import BatchSampler, RandomSampler
cv_11 = load_dataset("mozilla-foundation/common_voice_11_0", "hi", split="train")
batch_sampler = BatchSampler(RandomSampler(cv_11), batch_size=32, drop_last=False)
dataloader = DataLoader(cv_11, batch_sampler=batch_sampler)
```
### Streaming
```python
from datasets import load_dataset
from torch.utils.data import DataLoader
cv_11 = load_dataset("mozilla-foundation/common_voice_11_0", "hi", split="train")
dataloader = DataLoader(cv_11, batch_size=32)
```
To find out more about loading and preparing audio datasets, head over to [hf.co/blog/audio-datasets](https://huggingface.co/blog/audio-datasets).
### Example scripts
Train your own CTC or Seq2Seq Automatic Speech Recognition models on Common Voice 11 with `transformers` - [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition).
## Dataset Structure
### Data Instances
A typical data point comprises the `path` to the audio file and its `sentence`.
Additional fields include `accent`, `age`, `client_id`, `up_votes`, `down_votes`, `gender`, `locale` and `segment`.
```python
{
'client_id': 'd59478fbc1ee646a28a3c652a119379939123784d99131b865a89f8b21c81f69276c48bd574b81267d9d1a77b83b43e6d475a6cfc79c232ddbca946ae9c7afc5',
'path': 'et/clips/common_voice_et_18318995.mp3',
'audio': {
'path': 'et/clips/common_voice_et_18318995.mp3',
'array': array([-0.00048828, -0.00018311, -0.00137329, ..., 0.00079346, 0.00091553, 0.00085449], dtype=float32),
'sampling_rate': 48000
},
'sentence': 'Tasub kokku saada inimestega, keda tunned juba ammust ajast saati.',
'up_votes': 2,
'down_votes': 0,
'age': 'twenties',
'gender': 'male',
'accent': '',
'locale': 'et',
'segment': ''
}
```
### Data Fields
`client_id` (`string`): An id for which client (voice) made the recording
`path` (`string`): The path to the audio file
`audio` (`dict`): A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, *i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
`sentence` (`string`): The sentence the user was prompted to speak
`up_votes` (`int64`): How many upvotes the audio file has received from reviewers
`down_votes` (`int64`): How many downvotes the audio file has received from reviewers
`age` (`string`): The age of the speaker (e.g. `teens`, `twenties`, `fifties`)
`gender` (`string`): The gender of the speaker
`accent` (`string`): Accent of the speaker
`locale` (`string`): The locale of the speaker
`segment` (`string`): Usually an empty field
### Data Splits
The speech material has been subdivided into portions for dev, train, test, validated, invalidated, reported and other.
The validated data is data that has been validated with reviewers and received upvotes that the data is of high quality.
The invalidated data is data has been invalidated by reviewers
and received downvotes indicating that the data is of low quality.
The reported data is data that has been reported, for different reasons.
The other data is data that has not yet been reviewed.
The dev, test, train are all data that has been reviewed, deemed of high quality and split into dev, test and train.
## Data Preprocessing Recommended by Hugging Face
The following are data preprocessing steps advised by the Hugging Face team. They are accompanied by an example code snippet that shows how to put them to practice.
Many examples in this dataset have trailing quotations marks, e.g _“the cat sat on the mat.“_. These trailing quotation marks do not change the actual meaning of the sentence, and it is near impossible to infer whether a sentence is a quotation or not a quotation from audio data alone. In these cases, it is advised to strip the quotation marks, leaving: _the cat sat on the mat_.
In addition, the majority of training sentences end in punctuation ( . or ? or ! ), whereas just a small proportion do not. In the dev set, **almost all** sentences end in punctuation. Thus, it is recommended to append a full-stop ( . ) to the end of the small number of training examples that do not end in punctuation.
```python
from datasets import load_dataset
ds = load_dataset("mozilla-foundation/common_voice_11_0", "en", use_auth_token=True)
def prepare_dataset(batch):
"""Function to preprocess the dataset with the .map method"""
transcription = batch["sentence"]
if transcription.startswith('"') and transcription.endswith('"'):
# we can remove trailing quotation marks as they do not affect the transcription
transcription = transcription[1:-1]
if transcription[-1] not in [".", "?", "!"]:
# append a full-stop to sentences that do not end in punctuation
transcription = transcription + "."
batch["sentence"] = transcription
return batch
ds = ds.map(prepare_dataset, desc="preprocess dataset")
```
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in the Common Voice dataset.
## Considerations for Using the Data
### Social Impact of Dataset
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in the Common Voice dataset.
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Public Domain, [CC-0](https://creativecommons.org/share-your-work/public-domain/cc0/)
### Citation Information
```
@inproceedings{commonvoice:2020,
author = {Ardila, R. and Branson, M. and Davis, K. and Henretty, M. and Kohler, M. and Meyer, J. and Morais, R. and Saunders, L. and Tyers, F. M. and Weber, G.},
title = {Common Voice: A Massively-Multilingual Speech Corpus},
booktitle = {Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020)},
pages = {4211--4215},
year = 2020
}
```
提供机构:
mozilla-foundation
原始信息汇总
数据集概述
数据集名称
- 名称: Common Voice Corpus 11.0
数据集内容
- 类型: 语音数据集
- 内容: 包含MP3音频文件及其对应的文本文件,部分数据包含年龄、性别、口音等人口统计元数据。
数据集规模
- 总时长: 24,210小时
- 验证时长: 16,413小时
- 语言数量: 100种
数据集结构
- 数据实例: 每个实例包含音频文件路径、句子内容及其他元数据(如年龄、性别、口音等)。
- 数据字段: 包括客户端ID、音频路径、音频数据、句子、投票数、年龄、性别、口音、地区等。
数据集语言
- 语言列表: 包括Abkhaz, Arabic, Armenian等多种语言。
数据集使用
- 加载方式: 使用
datasets库的load_dataset函数加载,支持本地加载和流式加载。
数据集来源
- 来源: 扩展自Common Voice数据集。
数据集任务
- 任务类型: 自动语音识别(Automatic Speech Recognition, ASR)
数据集许可证
- 许可证: CC0-1.0
数据集多语言性
- 多语言支持: 是
数据集创建
- 注释创建者: 众包
- 语言创建者: 众包
数据集注意事项
- 使用限制: 用户不得尝试确定Common Voice数据集中说话者的身份。
数据集预处理建议
- 预处理步骤: 建议移除句子开头和结尾的引号,并在句子末尾不包含标点时添加句号。
数据集引用信息
- 引用格式:
@inproceedings{commonvoice:2020, author = {Ardila, R. and Branson, M. and Davis, K. and Henretty, M. and Kohler, M. and Meyer, J. and Morais, R. and Saunders, L. and Tyers, F. M. and Weber, G.}, title = {Common Voice: A Massively-Multilingual Speech Corpus}, booktitle = {Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020)}, pages = {4211--4215}, year = 2020 }
搜集汇总
数据集介绍
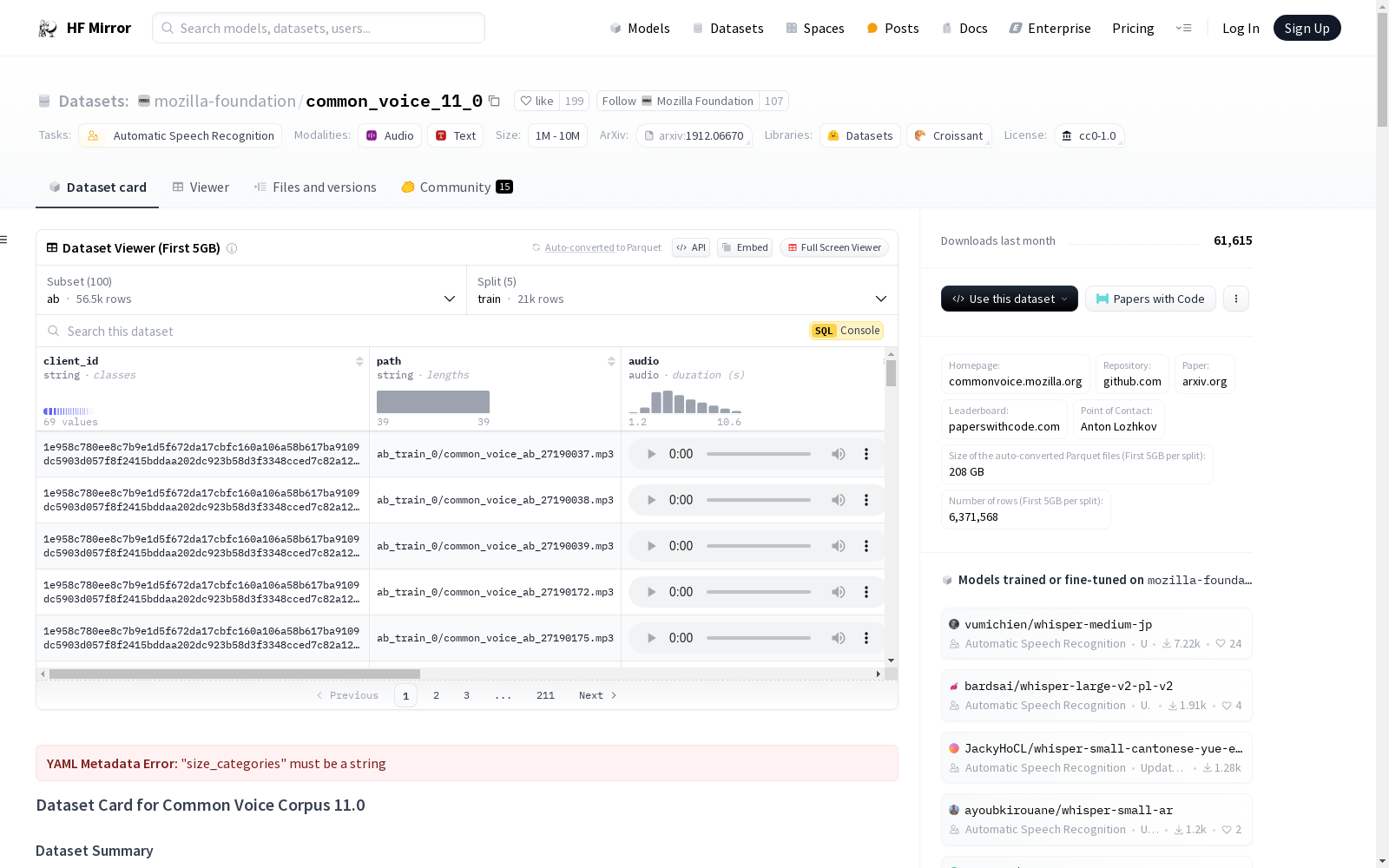
构建方式
Common Voice Corpus 11.0 数据集通过众包方式构建,汇集了来自全球各地的语音捐赠。该数据集的语音数据和相应的文本文件由志愿者提供,涵盖了多种语言和方言。每个语音样本不仅包含音频文件,还附带了如年龄、性别、口音等人口统计学元数据,这些信息有助于提升语音识别引擎的准确性。数据集的构建过程依赖于社区的广泛参与,确保了数据的多样性和广泛性。
特点
Common Voice Corpus 11.0 数据集的显著特点是其多语言性和大规模性。该数据集包含了100多种语言的语音数据,总时长超过16000小时,且数据量在不同语言间分布广泛,从几千条到数百万条不等。此外,数据集还提供了详细的元数据,如说话者的年龄、性别和口音,这些信息对于构建更加精准的语音识别模型至关重要。
使用方法
使用 Common Voice Corpus 11.0 数据集时,可以通过 Hugging Face 的 `datasets` 库轻松加载和预处理数据。例如,使用 `load_dataset` 函数可以指定语言配置名称来下载特定语言的数据集。此外,数据集支持流式加载,允许用户在不需要下载整个数据集的情况下逐条处理数据。对于深度学习模型训练,数据集可以直接与 PyTorch 数据加载器集成,方便进行大规模的模型训练和评估。
背景与挑战
背景概述
Common Voice Corpus 11.0是由Mozilla基金会主导开发的大规模多语言语音数据集,旨在推动语音识别技术的发展。该数据集创建于2020年,主要研究人员包括R. Ardila等人,其核心研究问题是如何通过众包方式收集高质量的语音数据,以支持多语言环境下的自动语音识别(ASR)任务。Common Voice数据集的推出对语音识别领域产生了深远影响,尤其是为资源匮乏的语言提供了宝贵的数据资源,促进了语音技术的普及与应用。
当前挑战
Common Voice数据集在构建过程中面临多重挑战。首先,如何通过众包方式确保语音数据的质量是一个关键问题,尤其是在处理不同语言和方言时,数据的一致性和准确性难以保证。其次,数据集的多样性也是一个挑战,包括不同年龄、性别、口音的语音样本,这些因素可能影响模型的泛化能力。此外,隐私保护也是一个重要问题,尽管数据集采用了匿名化处理,但仍需防止语音样本被用于识别说话者的身份。
常用场景
经典使用场景
Common Voice Corpus 11.0 数据集的经典使用场景主要集中在自动语音识别(ASR)领域。该数据集提供了丰富的语音样本及其对应的文本,适用于训练和评估语音识别模型。通过使用该数据集,研究者和开发者能够构建多语言的语音识别系统,尤其是在资源匮乏的语言上,提升模型的泛化能力和准确性。
解决学术问题
Common Voice Corpus 11.0 数据集解决了多语言语音识别中的关键学术问题,尤其是在低资源语言的语音识别任务中。该数据集通过提供多样化的语音样本和相应的文本标注,帮助研究者克服了数据稀缺性问题,推动了多语言语音识别技术的发展。其广泛的语言覆盖范围和高质量的语音数据为跨语言语音识别研究提供了宝贵的资源。
衍生相关工作
基于 Common Voice Corpus 11.0 数据集,许多经典工作得以展开,尤其是在多语言语音识别和语音数据增强领域。研究者们利用该数据集开发了多种语音识别模型,如基于深度学习的端到端语音识别系统,并在多个语言上取得了显著的性能提升。此外,该数据集还激发了关于语音数据隐私和伦理问题的讨论,推动了相关研究的深入发展。
以上内容由遇见数据集搜集并总结生成


