ai-layoff-discourse-amplification
收藏数据集概述
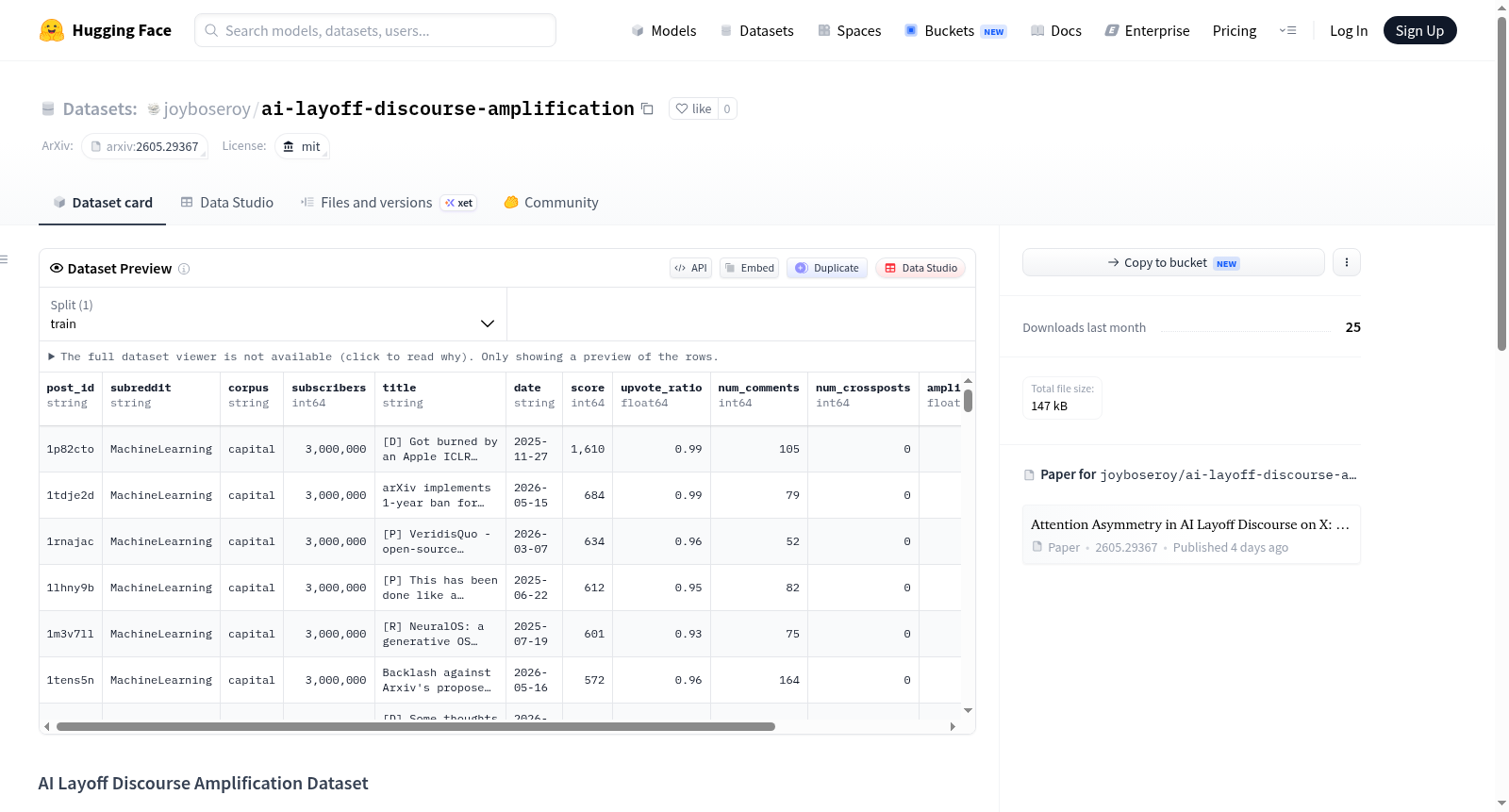
AI Layoff Discourse Amplification Dataset 是一个用于研究社交媒体上关于人工智能裁员话语的关注不对称性的数据集,对应论文 "Attention Asymmetry in AI Layoff Discourse on X: A Computational Analysis of Capital vs Labour Amplification"。
数据内容
-
tweet_ids.csv
包含从 X(原 Twitter)平台收集的 763 条推文的 ID,收集时间为 2026 年 5 月 20 日至 27 日。
列字段:tweet_id(推文ID)、corpus_label(语料标签:capital/labour)、account_handle(账户名)、date(日期)。
注意:按 X 开发者政策,仅提供推文 ID,需要使用 X API v2 进行水合(rehydrate)以获取完整推文对象。推荐水合工具:https://github.com/DocNow/hydrator -
reddit_posts.csv
包含来自 10 个子版块的 647 条 Reddit 帖子(选取过去一年内的热门帖子)。
提供完整帖子的数据,包括标题、得分、评论数、放大分数等。
列字段:post_id(帖子ID)、subreddit(子版块)、corpus(语料)、title(标题)、date(日期)、score(得分)、num_comments(评论数)、amplification(放大分数)、norm_amp(归一化放大分数)、platform(平台)。
语料标签说明
- capital:来自将人工智能视为机遇/转型的账户的帖子。
- labour:来自将人工智能视为替代/威胁的账户的帖子。
相关资源
-
论文:https://arxiv.org/abs/2605.29367
-
代码:https://gitlab.com/joyboseroy/attention-asymmetry
-
引用格式:
@misc{bose2026attention, title={Attention Asymmetry in AI Layoff Discourse on X}, author={Bose, Joy}, year={2026}, eprint={2605.29367}, archivePrefix={arXiv} }
许可证
MIT