RIVER: A Real-Time Interaction Benchmark for Video LLMs
收藏github2026-03-05 更新2026-03-06 收录
下载链接:
https://github.com/OpenGVLab/RIVER
下载链接
链接失效反馈官方服务:
资源简介:
该项目介绍了RIVER Bench,旨在通过流式视频感知评估视频大型语言模型的实时交互能力,具有记忆、实时感知和主动响应等新任务。根据参考事件、问题和答案的频率和时间,我们进一步将在线交互任务分为四个不同的子类。对于Retro-Memory,线索来自过去;对于live-Perception,线索来自现在——两者都要求立即响应。对于Pro-Response任务,视频大型语言模型需要等待相应的线索出现,然后尽快响应。
This project presents RIVER Bench, a benchmark developed to assess the real-time interactive capabilities of video large language models (video LLMs) through streaming video perception. This benchmark features novel tasks including memory, real-time perception, and proactive response. Based on the frequency and timing of reference events, questions, and answers, we further classify online interactive tasks into four distinct subclasses. For the Retro-Memory subclass, cues originate from past content; for the Live-Perception subclass, cues derive from the current moment—both demand immediate responses. For the Pro-Response task, video LLMs are required to await the corresponding cues before responding as promptly as possible.
创建时间:
2026-02-26
原始信息汇总
RIVER 数据集概述
数据集基本信息
- 数据集名称:RIVER: A Real-Time Interaction Benchmark for Video LLMs
- 核心目标:评估视频大语言模型(Video LLMs)的实时交互能力,重点关注流式视频感知。
- 任务类型:包含记忆、实时感知和主动响应等新型任务。
任务分类
根据参考事件、问题和答案的频率与时间,在线交互任务被划分为四个子类:
- 回溯记忆:线索来自过去。
- 实时感知:线索来自当下。
- 主动响应:视频大语言模型需要等待对应线索出现,并尽快响应。
数据来源
数据集整合了以下多个公开数据集:
- LongVideoBench:https://github.com/longvideobench/LongVideoBench
- Vript-RR:https://github.com/mutonix/Vript
- LVBench:https://github.com/zai-org/LVBench
- Ego4D:https://github.com/facebookresearch/Ego4d
- QVHighlights:https://github.com/jayleicn/moment_detr
访问与引用
- GitHub仓库:https://github.com/OpenGVLab/RIVER
- Hugging Face数据集:https://huggingface.co/datasets/nanamma/RIVER
- 论文地址:https://arxiv.org/abs/2603.03985
- 引用格式: BibTeX @misc{shi2026riverrealtimeinteractionbenchmark, title={RIVER: A Real-Time Interaction Benchmark for Video LLMs}, author={Yansong Shi and Qingsong Zhao and Tianxiang Jiang and Xiangyu Zeng and Yi Wang and Limin Wang}, year={2026}, eprint={2603.03985}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2603.03985}, }
搜集汇总
数据集介绍
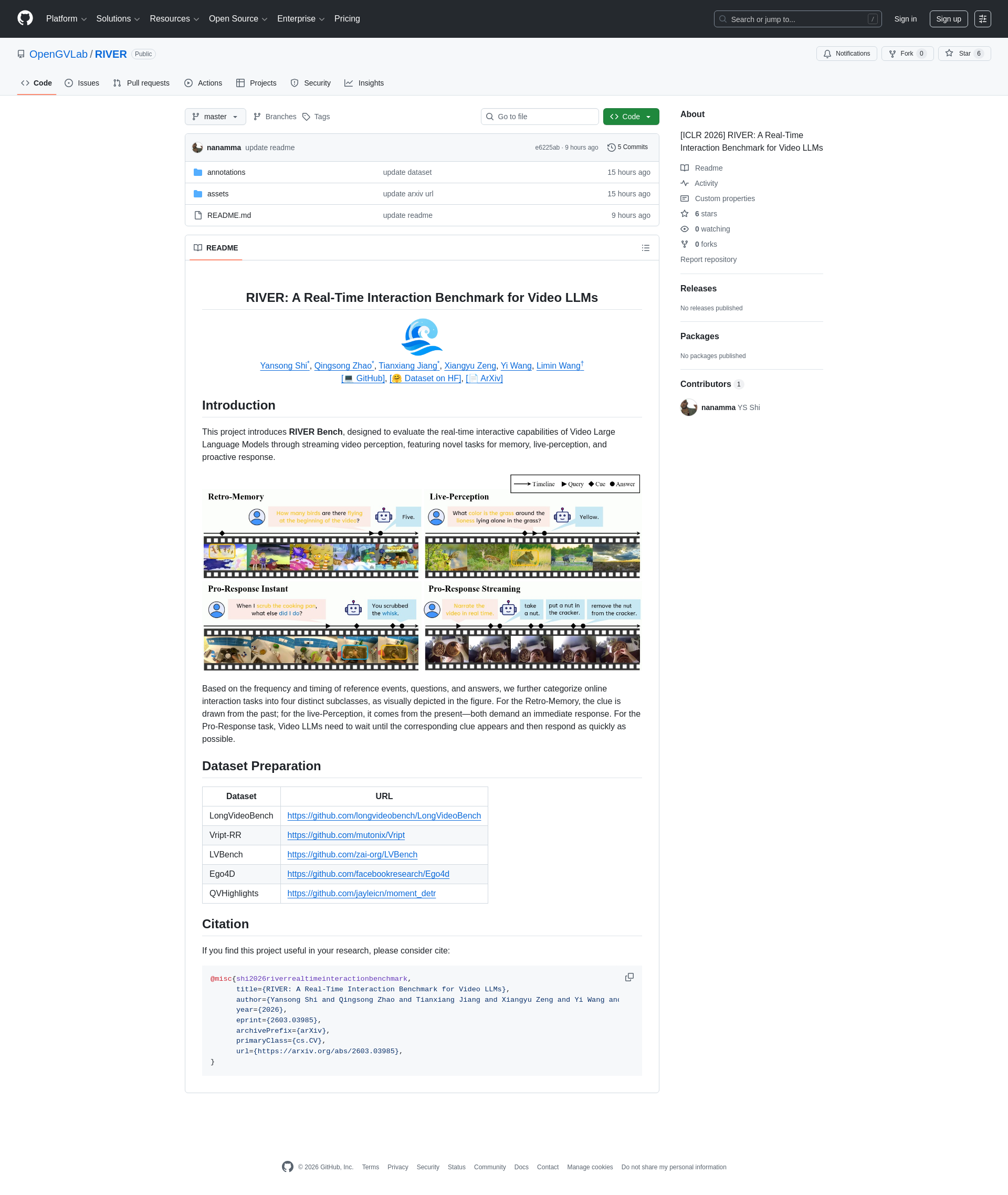
构建方式
在视频大语言模型评估领域,RIVER基准的构建体现了对实时交互能力的系统性考量。该数据集整合了来自LongVideoBench、Vript-RR、LVBench、Ego4D及QVHighlights等多个权威视频理解数据源的素材,通过精心设计的任务框架,将在线交互划分为追溯记忆、实时感知与主动响应等子类。其构建过程着重于模拟真实世界的流式视频输入场景,确保问题与线索在时间维度上的动态关联,从而为模型评估提供了时序精准且内容丰富的测试环境。
特点
RIVER基准的核心特点在于其专注于视频大语言模型的实时交互性能评估。该数据集引入了流式视频感知任务,强调模型在连续视频流中对过去事件的记忆回溯、对当前画面的即时感知以及对未来线索的主动响应能力。通过依据参考事件、问题与回答的频率和时序进行细粒度分类,RIVER构建了一个多维度、动态演进的评估体系,能够全面检验模型在时间敏感情境下的理解、推理与决策效率。
使用方法
使用RIVER基准进行评估时,研究者需将视频大语言模型置于模拟实时交互的流式视频输入环境中。模型需要处理按时间顺序呈现的视频片段,并针对数据集中设计的问题——包括基于历史画面的记忆查询、针对当前帧的感知判断以及等待特定线索出现后的主动应答——生成及时且准确的响应。评估过程通过测量模型在不同任务子类上的表现,量化其实时交互能力,为模型优化与比较提供了标准化、可复现的实验框架。
背景与挑战
背景概述
随着视频大语言模型在多媒体理解领域的快速发展,评估模型在实时交互场景下的能力成为一项关键需求。RIVER基准数据集由OpenGVLab等研究机构于2026年提出,旨在系统评估视频大语言模型在流式视频感知中的实时交互性能。该数据集聚焦于记忆回溯、实时感知与主动响应等新型任务,通过模拟动态视频流中的时序事件,推动模型在连续视觉信息处理与即时决策方面的研究。其创新性的任务设计为视频理解与交互智能的融合提供了重要基准,对推动具身智能与实时人机交互技术的发展具有显著影响力。
当前挑战
RIVER数据集致力于解决视频大语言模型在实时交互中的核心挑战,即模型如何对动态流式视频进行连续感知、记忆保持与即时响应。具体而言,挑战体现在模型需在有限时间窗口内准确捕捉时序线索,平衡处理速度与推理精度,并应对长视频序列中的信息衰减问题。在构建过程中,数据集整合了多个现有视频基准,需协调不同数据源的标注标准与时空对齐,确保任务设计的多样性与评估指标的鲁棒性,同时模拟真实场景中事件发生的随机性与交互的连续性,这对数据采集与标注流程提出了较高要求。
常用场景
经典使用场景
在视频大语言模型研究领域,实时交互能力的评估一直是核心挑战。RIVER基准通过模拟流式视频感知场景,为模型提供了经典测试环境,其中模型需处理动态输入并即时生成响应。该数据集特别适用于评估模型在记忆回溯、实时感知与主动响应等任务上的表现,这些任务要求模型能够连续理解视频内容,并在特定时刻做出准确判断,从而推动视频理解技术向更自然的人机交互方向发展。
实际应用
在实际应用层面,RIVER基准所针对的实时交互能力在智能监控、自动驾驶辅助系统以及沉浸式人机对话界面中具有重要价值。例如,在安防监控中,系统需要持续分析视频流,及时识别异常事件并发出警报;在车载环境中,模型需实时理解道路状况,为驾驶员提供即时反馈。该数据集通过模拟这些场景,帮助开发者优化模型响应速度与准确性,推动技术从实验室走向现实世界的部署,提升智能系统的实用性与可靠性。
衍生相关工作
围绕RIVER基准,学术界已衍生出多项经典研究工作,这些工作主要集中在提升视频大语言模型的实时性能与交互效率上。例如,基于该数据集的评估结果,研究者开发了新型记忆增强架构,以改善模型对长视频序列的理解能力;同时,也有工作专注于优化推理机制,减少延迟并提高响应精度。这些衍生研究不仅扩展了RIVER的应用边界,还推动了整个视频理解领域在算法设计、评估标准及系统集成方面的创新,形成了持续演进的技术生态。
以上内容由遇见数据集搜集并总结生成


