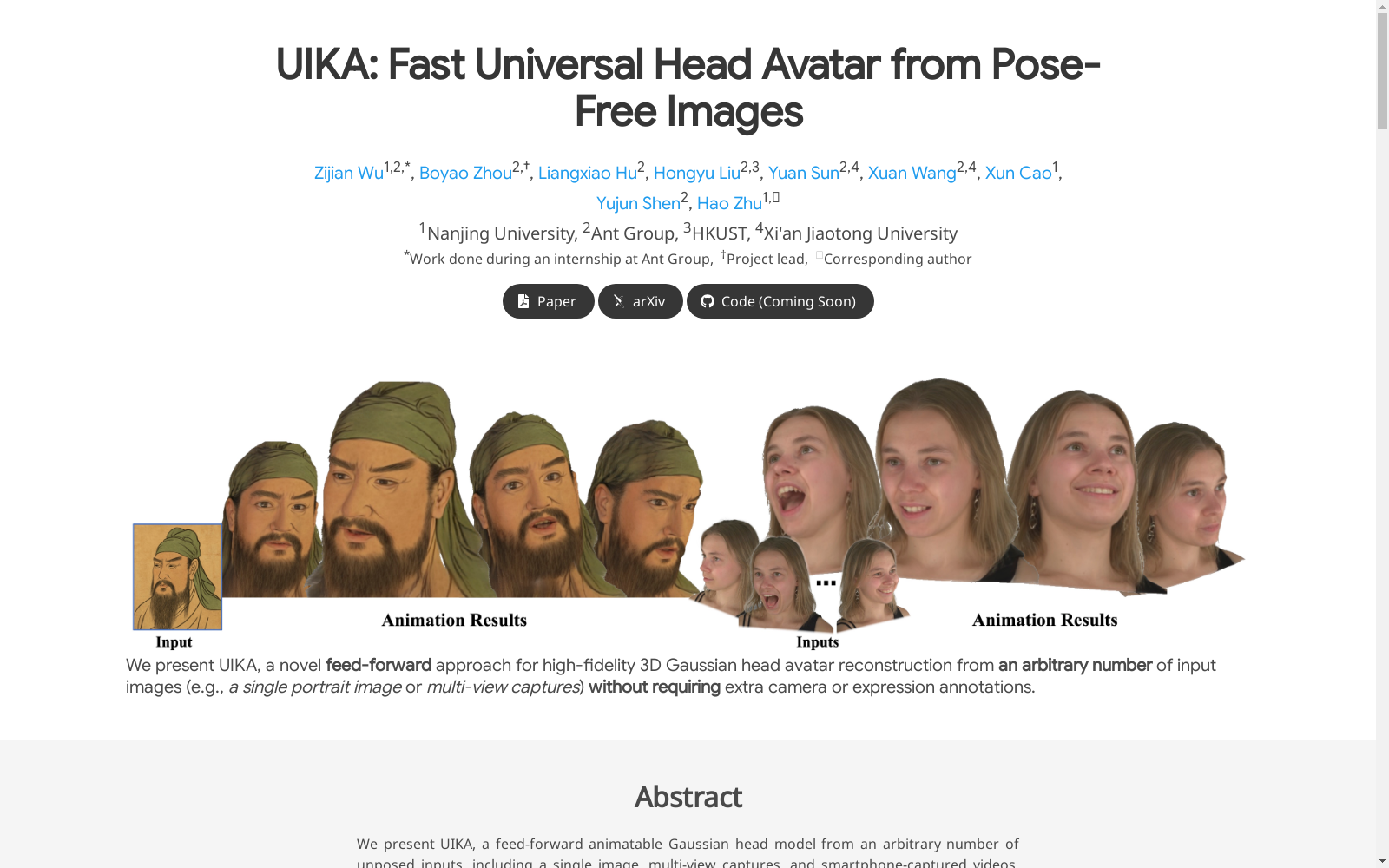
UIKA synthetic multi-view head dataset
收藏arXiv2026-01-12 更新2026-01-14 收录
下载链接:
https://zijian-wu.github.io/uika-page/
下载链接
链接失效反馈官方服务:
资源简介:
该数据集由蚂蚁集团等机构联合构建,是一个面向3D高斯头部重建任务的大规模合成多视角头部数据集。其核心特征包含丰富的身份多样性(数百种不同人种/年龄的头部模型)和表情变化(覆盖常见微表情及极端表情),数据来源为程序化生成的3D头部模型渲染图像。通过自动化管线生成多视角同步的RGB图像及对应UV坐标映射,解决了现有真实数据集中身份单一、视角覆盖不足的问题。该数据集主要用于训练高保真头部avatar重建模型,可支持单图/多图输入条件下的3D头部建模、表情重定向等虚拟人应用场景。
This dataset was jointly developed by Ant Group and other institutions, and is a large-scale synthetic multi-view head dataset tailored for 3D Gaussian head reconstruction tasks. Its core features include rich identity diversity (hundreds of head models covering diverse ethnicities and age groups) and diverse facial expression variations, spanning both common micro-expressions and extreme expressions. The data is sourced from rendered images of procedurally generated 3D head models. Using an automated pipeline, it generates synchronized multi-view RGB images and corresponding UV coordinate mappings, which addresses the key limitations of existing real-world datasets, namely limited identity diversity and insufficient view coverage. This dataset is primarily used for training high-fidelity head avatar reconstruction models, and supports various virtual human application scenarios such as 3D head modeling and expression retargeting under single-image or multi-image input conditions.
提供机构:
南京大学; 蚂蚁集团; 香港科技大学; 西安交通大学
创建时间:
2026-01-12
搜集汇总
数据集介绍
构建方式
在三维头部建模领域,高质量训练数据的稀缺性长期制约着模型的泛化能力。UIKA合成多视角头部数据集通过创新的数据生成流程,有效解决了这一瓶颈。该数据集构建过程融合了三维头部生成模型SphereHead与二维肖像动画模型LivePortrait,首先利用SphereHead从野外图像中学习广泛相机姿态下的三维一致性头部渲染,为每个身份采样九个固定视角并生成对应视图;随后采用统一的驱动序列,通过LivePortrait对每个视角的渲染视图进行时序同步的动画处理,最终生成身份多样、表情丰富且具有极端表情变化的多视角头部序列。整个流程共涵盖了超过7500个独立身份,每个身份包含9个视角和超过13000帧图像,在避免昂贵工作室采集成本的同时,显著提升了模型在野外场景下的鲁棒性。
使用方法
该数据集主要服务于可动画三维高斯头部模型的训练与验证。在训练阶段,模型从数据集中随机采样1到N_ref帧作为源输入,以重建规范空间的高斯表示;同时额外采样N_d帧作为驱动和目标视图,用于重演监督。数据集支持对模型进行单目与多视角两种输入配置下的全面评估,包括自重演和交叉重演两种场景。在自重演中,可利用峰值信噪比、结构相似性指数、学习感知图像块相似度等指标量化图像重建质量;交叉重演则侧重于评估身份相似性、平均表情距离和平均姿态距离等迁移性能。通过在该数据集上的训练,模型能够学习从任意数量无姿态图像中聚合信息的能力,并显著提升在新视角、新表情下的泛化性能与三维一致性。
背景与挑战
背景概述
随着虚拟现实、远程呈现和电影制作等领域的快速发展,高保真三维头部虚拟形象的生成成为计算机视觉研究的关键方向。传统方法通常依赖复杂的多视角采集系统,并需针对特定个体进行耗时的优化重建,限制了其实际应用范围。在此背景下,南京大学与蚂蚁集团等机构的研究团队于2026年提出了UIKA合成多视角头部数据集,旨在通过大规模合成数据支持前馈式三维高斯头部虚拟形象的快速重建。该数据集的核心研究问题在于如何从任意数量、无姿态标注的输入图像中,高效生成具有高度真实感和实时动画能力的头部虚拟形象,从而推动相关技术向更灵活、实用的方向发展。
当前挑战
在三维头部虚拟形象生成领域,核心挑战在于如何从稀疏或无姿态约束的输入中实现高保真、多视角一致的重建,同时确保模型能够泛化到未见过的身份、表情和视角。具体而言,现有方法常受限于训练数据的身份多样性不足、视角覆盖有限以及表情变化不够丰富,导致重建质量在极端姿态或复杂光照下显著下降。在数据集构建过程中,研究团队面临合成数据与真实场景之间的域差异问题,需通过精心设计的生成流程确保多视角间的三维一致性,并平衡身份多样性与表情丰富性,以提升模型在真实场景中的鲁棒性和泛化能力。
常用场景
经典使用场景
在三维头部建模领域,高质量数据集的匮乏长期制约着模型的泛化能力与重建精度。UIKA合成多视角头部数据集通过精心设计的生成流程,构建了身份多样、视角完备且表情丰富的头部序列,为三维高斯头像的重建与动画化提供了关键训练资源。该数据集最经典的使用场景在于训练前馈式头部重建模型,特别是针对任意数量无姿态输入图像的通用头像生成任务。研究人员利用该数据集的大规模多视角同步序列,能够有效学习跨视角的几何一致性,并提升模型在极端表情和复杂光照条件下的鲁棒性,从而突破传统单目或有限视角数据集带来的建模瓶颈。
解决学术问题
该数据集主要解决了三维头部重建领域中身份多样性不足、视角覆盖有限以及表情动态范围狭窄等核心学术问题。传统多视角数据集受限于昂贵的采集设备与复杂的制作流程,通常仅包含数百个身份,且多为中性表情的静态捕捉,难以支撑模型对真实世界复杂面部动态的学习。UIKA数据集通过合成技术规模化生成超过7500个身份,每个身份包含9个固定视角和超过13000帧的同步序列,覆盖了从日常表情到夸张表演的广泛动态范围。这种大规模、高质量的数据供给,使得模型能够学习到更具泛化能力的头部先验,显著提升了在单目、多视角乃至野外图像输入下的重建质量与动画保真度。
实际应用
在实际应用层面,基于UIKA数据集训练的模型能够快速从单张或多张日常拍摄的肖像中重建出高保真、可实时动画驱动的三维高斯头像。这为虚拟现实中的沉浸式社交、影视制作中的数字替身创建、在线教育与远程协作的个性化形象呈现,乃至游戏与娱乐产业的角色生成提供了高效的技术解决方案。相较于依赖专业多相机阵列和冗长优化过程的传统方案,此类技术极大地降低了高质量数字人制作的门槛与成本,使得普通用户也能通过智能手机等便捷设备创建属于自己的生动数字形象,推动了虚拟化身技术在消费级市场的普及与应用。
数据集最近研究
最新研究方向
在三维数字人建模领域,UIKA合成多视角头部数据集正推动着无需姿态标注的通用头部化身重建技术的前沿探索。该数据集通过大规模合成身份多样、表情丰富的多视角序列,有效弥补了传统采集数据在身份覆盖与视角范围上的局限,为训练高泛化性模型提供了关键支撑。当前研究聚焦于基于UV引导的注意力机制与自适应融合策略,实现了从任意数量无姿态输入图像中快速重建可动画的高斯化身,显著提升了在单目与多视角设置下的重建质量与实时渲染效率。这一进展不仅降低了高质量数字人创建的门槛,也为虚拟现实、远程呈现等应用场景提供了更为灵活高效的解决方案,标志着头部化身技术向实用化与普及化迈出了重要一步。
相关研究论文
- 1UIKA: Fast Universal Head Avatar from Pose-Free Images南京大学; 蚂蚁集团; 香港科技大学; 西安交通大学 · 2026年
以上内容由遇见数据集搜集并总结生成


