Question-Anchored-Tutoring-Dialogues-2k
收藏Hugging Face2025-04-24 更新2025-04-25 收录
下载链接:
https://huggingface.co/datasets/Eedi/Question-Anchored-Tutoring-Dialogues-2k
下载链接
链接失效反馈官方服务:
资源简介:
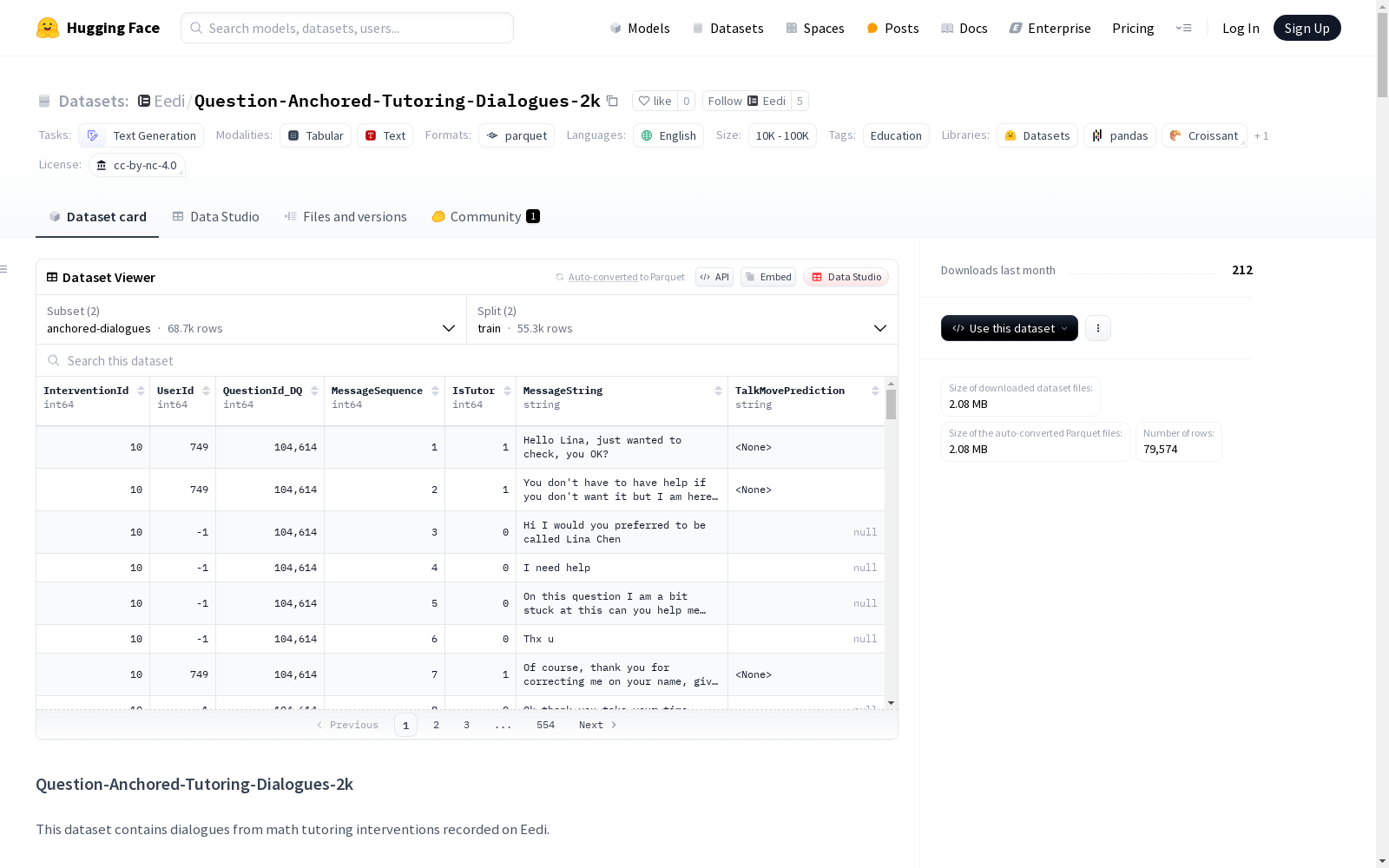
Question Anchored Tutoring Dialogues数据集包含了Eedi平台上的数学辅导对话。这些对话是由学生在做数学练习时请求帮助而产生的。数据集旨在用于非商业研究,以改进学习成果。它包括两个主要部分:anchored-dialogues和dq-question-metadata,分别代表对话数据和与对话相关的问题元数据。数据集经过严格的筛选和处理,以确保隐私和安全,并包含了对谈话移动的标注,有助于研究对话中的教学策略。
创建时间:
2025-04-16
原始信息汇总
数据集概述:Question-Anchored-Tutoring-Dialogues-2k
基本信息
- 名称:Question Anchored Tutoring Dialogues
- 语言:英语
- 许可:CC-BY-NC-4.0
- 任务类型:文本生成
- 领域:教育
- 数据规模:1K<n<10K
- 配置:
anchored-dialogues:包含训练集和测试集dq-question-metadata:仅包含训练集
数据集详情
- 描述:包含来自数学辅导干预的对话,记录于Eedi平台。每个对话代表学生请求帮助时与导师的聊天对话。
- 元数据:
- DQ-Question-Metadata:学生请求辅导时正在处理的问题。
- Dialogue-Subjects:课程的主题、话题和子话题。
- 创建者:Matthew Zent, Digory Smith, Simon Woodhead
- 资助方:Eedi
数据集结构
anchored-dialogues
- 特征:
InterventionId:干预的唯一标识符UserId:用户的唯一标识符QuestionId_DQ:诊断问题的唯一标识符MessageSequence:消息在对话中的序列号IsTutor:消息是否来自导师(1为导师,0为学生)MessageString:消息内容TalkMovePrediction:导师支持学生数学思维的标签
- 数据量:
- 训练集:55,322个样本,4,674,549字节
- 测试集:13,395个样本,1,138,842字节
dq-question-metadata
- 特征:
QuestionId_DQ:诊断问题的唯一标识符InterventionId:干预的唯一标识符MetaDataId:元数据的唯一标识符Text:问题的提取文本Sequence:文本的呈现顺序MetaDataTagId:与Label列的一对一映射Label:提取文本的标签
- 数据量:
- 训练集:10,857个样本,1,129,952字节
使用场景
- 直接用途:用于非商业研究,改进学习成果。适用于模型训练、微调和校准任务。
- 超出范围的用途:识别或重新识别个体、监视、剖析或自动化高风险决策。
数据集创建
- 来源:Eedi数学学习平台
- 收集时间:2021年11月至2025年2月
- 处理步骤:
- 初始过滤
- 内容审核
- 导师同意
- 降采样
- 手动审查
- PII匿名化
- 训练/测试分割
注释
- Talk Moves:用于降采样的GPT分类模型标签
- Potential-PII:通过机器和人工标注的PII匿名化标签
限制与风险
- 偏见:聚焦英国学生,排除美国学习者
- 隐私:尽管进行了匿名化处理,敏感内容可能仍然存在
联系方式
- 作者:Matthew Zent
- 邮箱:Matthew.Zent@eedi.co.uk
搜集汇总
数据集介绍
构建方式
该数据集构建过程体现了严谨的教育数据科学方法论,通过多阶段过滤和处理流程确保数据质量。研究团队从Eedi数学学习平台采集2021年11月至2025年2月的原始对话数据,采用分层抽样策略筛选包含至少20条消息的师生对话。数据经过内容审核、导师授权确认、TF-IDF加权的对话多样性采样等专业处理,并运用PIIvot工具进行隐私匿名化处理,最终形成包含1,971个教学干预案例的精炼数据集。数据划分采用0.8/0.2的标准训练测试集分割策略,确保模型评估的可靠性。
特点
数据集核心价值在于其多维度的教育对话标注体系,不仅包含原始对话文本,还整合了诊断问题元数据(DQ-Question-Metadata)和学科主题层级体系(Dialogue-Subjects)。特别值得注意的是,该数据集创新性地引入TalkMovePrediction标注,通过GPT模型对教师支持学生数学思维的对话策略进行分类。数据覆盖1,073名英国学生与25名教师的互动,包含68,717条消息,并附有详细的用户人口统计信息和平台使用行为数据,为教育对话分析提供了丰富的上下文特征。
使用方法
该数据集主要面向教育技术领域的非商业研究,特别适合用于智能辅导系统的对话建模和教学策略分析。研究人员可通过HuggingFace平台直接加载数据集,利用其预置的训练测试划分开展实验。典型应用场景包括:基于对话序列的响应生成模型训练、教学话术模式挖掘、以及个性化学习干预效果评估。使用时应严格遵守CC-BY-NC-4.0许可协议,特别注意数据中的潜在隐私风险,禁止任何个体重识别尝试。对于涉及敏感内容的研究,建议联系数据集作者获取伦理使用指导。
背景与挑战
背景概述
Question-Anchored-Tutoring-Dialogues-2k数据集由Eedi平台于2021至2025年间创建,主要研究者包括Matthew Zent、Digory Smith和Simon Woodhead。该数据集聚焦于数学教育领域,收录了导师与学生之间的对话记录,旨在通过自然语言处理技术改善在线教育中的个性化辅导效果。其核心研究问题在于如何利用对话数据提升学习成效,特别是在数学问题解决过程中的交互模式分析。作为教育技术领域的重要资源,该数据集为智能辅导系统的开发提供了真实场景下的对话范例,推动了教育对话建模的研究进展。
当前挑战
该数据集面临多重挑战:在领域问题层面,需解决教育对话中复杂的语义理解问题,包括数学术语的准确解析、多轮对话的连贯性保持以及教育意图的识别;在构建过程中,研究者需处理数据隐私保护的难题,包括个人身份信息的匿名化处理,同时确保对话内容的完整性和教育价值。此外,数据采集还面临对话质量控制的挑战,如筛选具有教育意义的对话片段,并平衡不同难度级别和话题的样本分布。
常用场景
经典使用场景
在数学教育领域,Question-Anchored-Tutoring-Dialogues-2k数据集为研究者提供了丰富的导师-学生对话资源。这些对话围绕特定数学问题展开,记录了学生求助与导师指导的全过程。数据集最经典的应用场景在于教育对话系统的开发与优化,特别是针对数学辅导场景的智能对话模型训练。研究者可利用这些真实交互数据,分析有效教学策略的对话模式,构建更贴近实际教学场景的对话系统。
解决学术问题
该数据集有效解决了教育技术领域多个关键研究问题。首先,它提供了研究一对一数学辅导对话结构的标准化数据,填补了该领域高质量对话语料库的空白。其次,通过标注的'TalkMovePrediction'字段,支持教学策略自动识别的研究。最重要的是,数据集为解决'如何通过对话提升学习效果'这一核心教育问题提供了实证研究基础,推动了基于证据的教学方法发展。
衍生相关工作
围绕该数据集已产生多项重要研究成果。Moreau-Pernet等人(2024)基于这些对话数据开发了教学策略分类模型,为自动识别有效教学方法奠定了基础。Eedi团队进一步利用数据集优化了其智能辅导系统,相关成果发表在多个教育技术会议上。数据集还催生了PIIvot等隐私保护工具的开发,推动了教育数据匿名化处理技术的研究进展。
以上内容由遇见数据集搜集并总结生成


