HuggingFaceM4/LocalizedNarratives
收藏Hugging Face2022-12-15 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/HuggingFaceM4/LocalizedNarratives
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-4.0
---
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://google.github.io/localized-narratives/(https://google.github.io/localized-narratives/)
- **Repository:**: [https://github.com/google/localized-narratives](https://github.com/google/localized-narratives)
- **Paper:** [Connecting Vision and Language with Localized Narratives](https://arxiv.org/pdf/1912.03098.pdf)
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
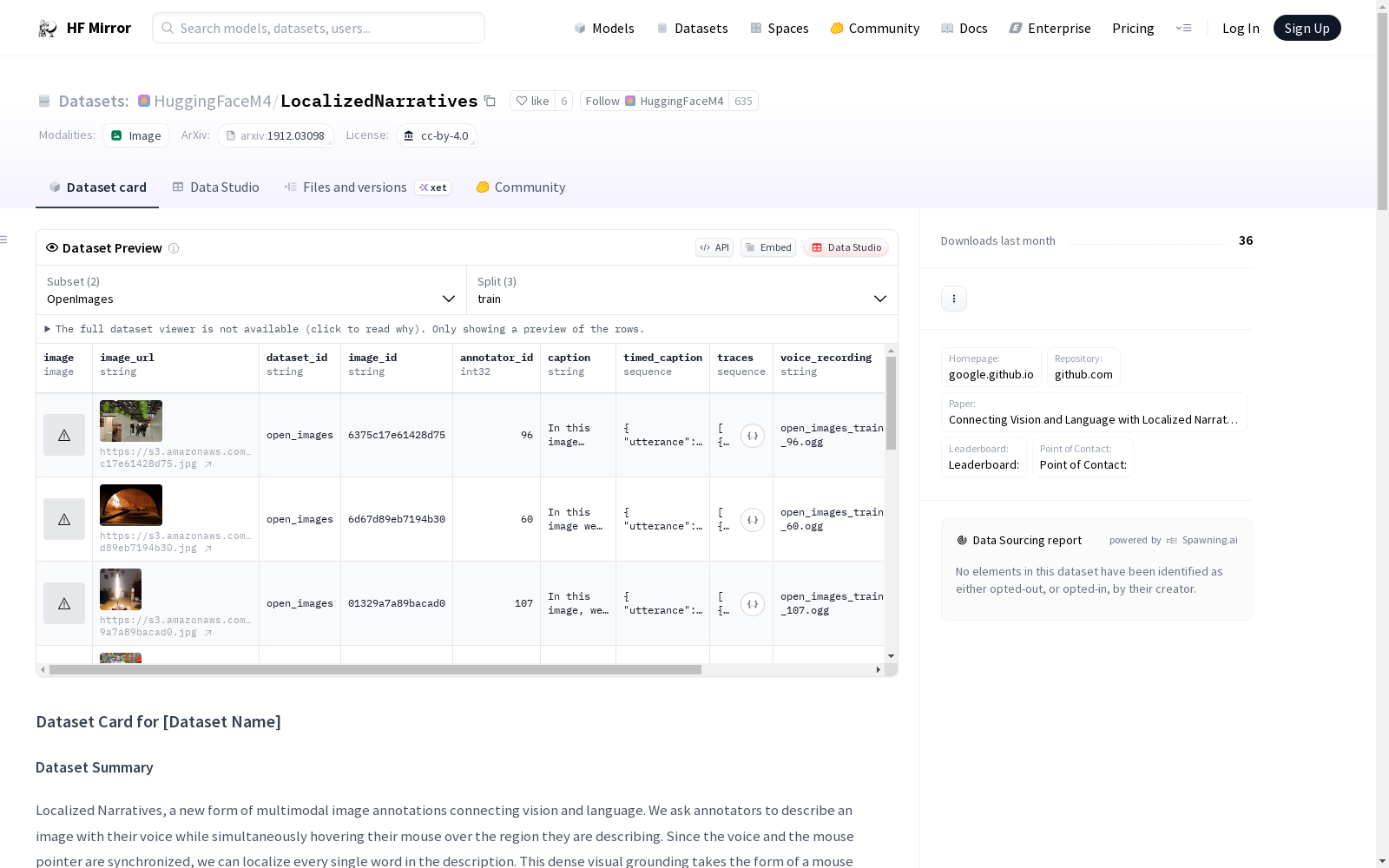
Localized Narratives, a new form of multimodal image annotations connecting vision and language.
We ask annotators to describe an image with their voice while simultaneously hovering their mouse over the region they are describing.
Since the voice and the mouse pointer are synchronized, we can localize every single word in the description.
This dense visual grounding takes the form of a mouse trace segment per word and is unique to our data.
We annotated 849k images with Localized Narratives: the whole COCO, Flickr30k, and ADE20K datasets, and 671k images of Open Images, all of which we make publicly available.
As of now, there is only the `OpenImages` subset, but feel free to contribute the other subset of Localized Narratives!
`OpenImages_captions` is similar to the `OpenImages` subset. The differences are that captions are groupped per image (images can have multiple captions). For this subset, `timed_caption`, `traces` and `voice_recording` are not available.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
Each instance has the following structure:
```
{
dataset_id: 'mscoco_val2017',
image_id: '137576',
annotator_id: 93,
caption: 'In this image there are group of cows standing and eating th...',
timed_caption: [{'utterance': 'In this', 'start_time': 0.0, 'end_time': 0.4}, ...],
traces: [[{'x': 0.2086, 'y': -0.0533, 't': 0.022}, ...], ...],
voice_recording: 'coco_val/coco_val_137576_93.ogg'
}
```
### Data Fields
Each line represents one Localized Narrative annotation on one image by one annotator and has the following fields:
- `dataset_id`: String identifying the dataset and split where the image belongs, e.g. mscoco_val2017.
- `image_id` String identifier of the image, as specified on each dataset.
- `annotator_id` Integer number uniquely identifying each annotator.
- `caption` Image caption as a string of characters.
- `timed_caption` List of timed utterances, i.e. {utterance, start_time, end_time} where utterance is a word (or group of words) and (start_time, end_time) is the time during which it was spoken, with respect to the start of the recording.
- `traces` List of trace segments, one between each time the mouse pointer enters the image and goes away from it. Each trace segment is represented as a list of timed points, i.e. {x, y, t}, where x and y are the normalized image coordinates (with origin at the top-left corner of the image) and t is the time in seconds since the start of the recording. Please note that the coordinates can go a bit beyond the image, i.e. <0 or >1, as we recorded the mouse traces including a small band around the image.
- `voice_recording` Relative URL path with respect to https://storage.googleapis.com/localized-narratives/voice-recordings where to find the voice recording (in OGG format) for that particular image.
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@VictorSanh](https://github.com/VictorSanh) for adding this dataset.
license: cc-by-4.0
# [数据集名称] 数据集卡片
## 目录
- [目录](#table-of-contents)
- [数据集描述](#dataset-description)
- [数据集概览](#dataset-summary)
- [支持任务与排行榜](#supported-tasks-and-leaderboards)
- [支持语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [构建初衷](#curation-rationale)
- [源数据](#source-data)
- [标注信息](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用须知](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差分析](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [许可信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献致谢](#contributions)
## 数据集描述
- **主页:** [https://google.github.io/localized-narratives/](https://google.github.io/localized-narratives/)
- **代码仓库:** [https://github.com/google/localized-narratives](https://github.com/google/localized-narratives)
- **相关论文:** [Connecting Vision and Language with Localized Narratives](https://arxiv.org/pdf/1912.03098.pdf)
- **排行榜:**
- **联系方式:**
### 数据集概览
本地化叙事标注(Localized Narratives)是一种连接视觉与语言的新型多模态图像标注形式。我们要求标注者在通过语音描述图像的同时,将鼠标悬停在其正在描述的图像区域上。由于语音与鼠标指针的运动完全同步,我们可以对描述文本中的每一个单词进行定位。这种密集视觉接地以每个单词对应一段鼠标轨迹的形式呈现,是本数据集独有的特性。我们使用本地化叙事标注对84.9万张图像进行了标注:涵盖完整的COCO、Flickr30k与ADE20K数据集,以及67.1万张Open Images数据集图像,所有数据均已公开。
截至目前,仅公开了`OpenImages`子集,欢迎各位贡献其余本地化叙事标注子集!
`OpenImages_captions`子集与`OpenImages`子集类似,区别在于字幕按图像分组(单张图像可对应多条字幕)。该子集不提供`timed_caption`、`traces`与`voice_recording`字段。
### 支持任务与排行榜
[需补充更多信息]
### 支持语言
[需补充更多信息]
## 数据集结构
### 数据实例
每个数据实例具有以下结构:
{
dataset_id: 'mscoco_val2017',
image_id: '137576',
annotator_id: 93,
caption: 'In this image there are group of cows standing and eating th...',
timed_caption: [{'utterance': 'In this', 'start_time': 0.0, 'end_time': 0.4}, ...],
traces: [[{'x': 0.2086, 'y': -0.0533, 't': 0.022}, ...], ...],
voice_recording: 'coco_val/coco_val_137576_93.ogg'
}
### 数据字段
每一行对应一位标注者对单张图像的一条本地化叙事标注,包含以下字段:
- `dataset_id`: 用于标识图像所属数据集与划分的字符串,例如`mscoco_val2017`。
- `image_id`: 图像的唯一标识符,遵循对应数据集的命名规范。
- `annotator_id`: 用于唯一标识每位标注者的整数编号。
- `caption`: 图像描述文本,以字符串形式存储。
- `timed_caption`: 带时间戳的话语列表,格式为`{utterance, start_time, end_time}`,其中`utterance`为单个单词或词组,`(start_time, end_time)`为该话语的录制时间段(以录音开始时刻为时间原点)。
- `traces`: 鼠标轨迹段列表,每一段对应鼠标进入图像至离开图像的过程。每条轨迹段由一系列带时间戳的坐标点组成,格式为`{x, y, t}`,其中`x`与`y`为归一化的图像坐标(原点位于图像左上角),`t`为自录音开始时刻起的秒数。请注意,坐标值可能略超出图像范围(即`<0`或`>1`),因为我们录制了图像周边一小区域内的鼠标轨迹。
- `voice_recording`: 相对于`https://storage.googleapis.com/localized-narratives/voice-recordings`的相对路径,用于获取对应图像的语音录音(格式为OGG)。
### 数据划分
[需补充更多信息]
## 数据集构建
### 构建初衷
[需补充更多信息]
### 源数据
#### 初始数据收集与标准化
[需补充更多信息]
#### 源语言生成者是谁?
[需补充更多信息]
### 标注信息
#### 标注流程
[需补充更多信息]
#### 标注者身份
[需补充更多信息]
### 个人与敏感信息
[需补充更多信息]
## 数据集使用须知
### 数据集的社会影响
[需补充更多信息]
### 偏差分析
[需补充更多信息]
### 其他已知局限性
[需补充更多信息]
## 附加信息
### 数据集维护者
[需补充更多信息]
### 许可信息
[需补充更多信息]
### 引用信息
[需补充更多信息]
### 贡献致谢
感谢[@VictorSanh](https://github.com/VictorSanh)为本数据集的接入提供贡献。
提供机构:
HuggingFaceM4
原始信息汇总
数据集概述
数据集名称
Localized Narratives
数据集总结
Localized Narratives 是一种连接视觉和语言的新型多模态图像注释。注释者通过语音描述图像,同时鼠标悬停在描述的区域上。语音和鼠标指针同步,使得每个单词的描述都可以被定位。这种密集的视觉接地形式以每个单词的鼠标轨迹段表示,是本数据集独有的。已对849k张图像进行了注释,包括整个COCO、Flickr30k和ADE20K数据集,以及671k张Open Images图像,所有这些都已公开发布。
数据集结构
数据实例
每个实例包含以下结构:
{ dataset_id: mscoco_val2017, image_id: 137576, annotator_id: 93, caption: In this image there are group of cows standing and eating th..., timed_caption: [{utterance: In this, start_time: 0.0, end_time: 0.4}, ...], traces: [[{x: 0.2086, y: -0.0533, t: 0.022}, ...], ...], voice_recording: coco_val/coco_val_137576_93.ogg }
数据字段
dataset_id: 字符串,标识图像所属的数据集和分割。image_id: 字符串,图像的标识符。annotator_id: 整数,唯一标识每个注释者。caption: 字符串,图像的描述。timed_caption: 列表,包含时间同步的语音描述。traces: 列表,包含鼠标轨迹。voice_recording: 字符串,语音记录的相对URL路径。
数据集创建
个人和敏感信息
[更多信息待补充]
使用数据的考虑
其他已知限制
[更多信息待补充]
附加信息
贡献者
感谢 @VictorSanh 添加此数据集。
搜集汇总
数据集介绍
构建方式
本数据集的构建基于对图像进行密集视觉定位的标注方法,要求标注者在描述图像时,通过鼠标轨迹同步其语音描述。具体而言,标注者需在描述图像时,用鼠标在图像上移动,并同步进行语音记录,使得每个单词的描述都能对应到图像上的特定区域,形成与语音描述同步的鼠标轨迹段。
特点
HuggingFaceM4/LocalizedNarratives数据集的独特之处在于其将视觉与语言结合的密集视觉定位标注形式。该数据集包含了849k张图像的标注,涵盖了整个COCO、Flickr30k和ADE20K数据集,以及671k张Open Images的图像。每张图像都通过语音描述与鼠标轨迹相结合的方式进行标注,实现了描述的精确区域定位。此外,该数据集的部分子集还提供了按图像分组的描述,以及时间同步的字幕和语音录音。
使用方法
使用该数据集时,用户可以根据数据集中的字段,如图像ID、标注者ID、图像描述、时间同步的字幕、鼠标轨迹和语音录音等,进行相应的图像描述与视觉定位任务。用户需要准备相应的处理工具,如语音识别和图像处理软件,以便能够充分利用数据集中的多模态信息。同时,用户还需关注数据使用的合法性和伦理问题,确保遵守相关法律法规和版权要求。
背景与挑战
背景概述
在计算机视觉与自然语言处理领域,实现图像内容与语言的深度结合始终是研究的热点。HuggingFaceM4/LocalizedNarratives数据集,创建于2019年,由Google团队主导,旨在通过一种新型的多模态图像注释方式,即定位化叙述(Localized Narratives),将视觉与语言紧密连接。该数据集的核心研究问题是开发一种能够精确定位图像中描述对象的文字注释方法。通过让标注者在描述图像时,同时用鼠标指针指向他们所描述的区域,实现了对每个单词描述的视觉定位。这一数据集涵盖了COCO、Flickr30k和ADE20K等完整数据集以及Open Images中的671k图像,为相关领域的研究提供了丰富的资源,并产生了深远的影响。
当前挑战
该数据集在构建过程中遇到的挑战主要包括:一是如何同步标注者的语音与鼠标轨迹,确保每个单词的描述都能与图像中的具体区域准确对应;二是如何处理大规模图像数据集的标注工作,保证标注质量的一致性;三是在数据集的应用中,如何有效利用这些定位化叙述进行图像理解、视觉问答等任务的模型训练与优化。此外,数据集在使用过程中还需关注如何避免潜在的偏见和隐私问题,确保其公平性和安全性。
常用场景
经典使用场景
在探索视觉与语言相结合的领域中,HuggingFaceM4/LocalizedNarratives数据集提供了一个独特的视角。该数据集通过要求标注者在描述图像时,同时用鼠标指针指向他们所描述的区域,实现了对每个单词的密集视觉定位。这种同步的语音和鼠标轨迹数据,使得它成为研究图像字幕、视觉问答和图像理解等任务的经典使用场景。
解决学术问题
该数据集解决了学术研究中如何精确对齐图像内容与自然语言描述的难题。通过提供与每个单词相对应的鼠标轨迹,研究人员能够更好地理解描述性语言的视觉参照,进而提高图像描述、视觉问答系统的准确性和可靠性,对于提升多模态信息处理的研究具有重要意义。
衍生相关工作
该数据集衍生出的相关工作包括多模态信息融合、图像描述生成、视觉问答等领域的深入研究。研究人员基于该数据集开发出了更先进的模型,以实现对图像内容更加丰富和细腻的描述,推动了计算机视觉和自然语言处理领域的交叉融合。
以上内容由遇见数据集搜集并总结生成


