SID_Set
收藏Hugging Face2025-03-12 更新2025-03-13 收录
下载链接:
https://huggingface.co/datasets/saberzl/SID_Set
下载链接
链接失效反馈官方服务:
资源简介:
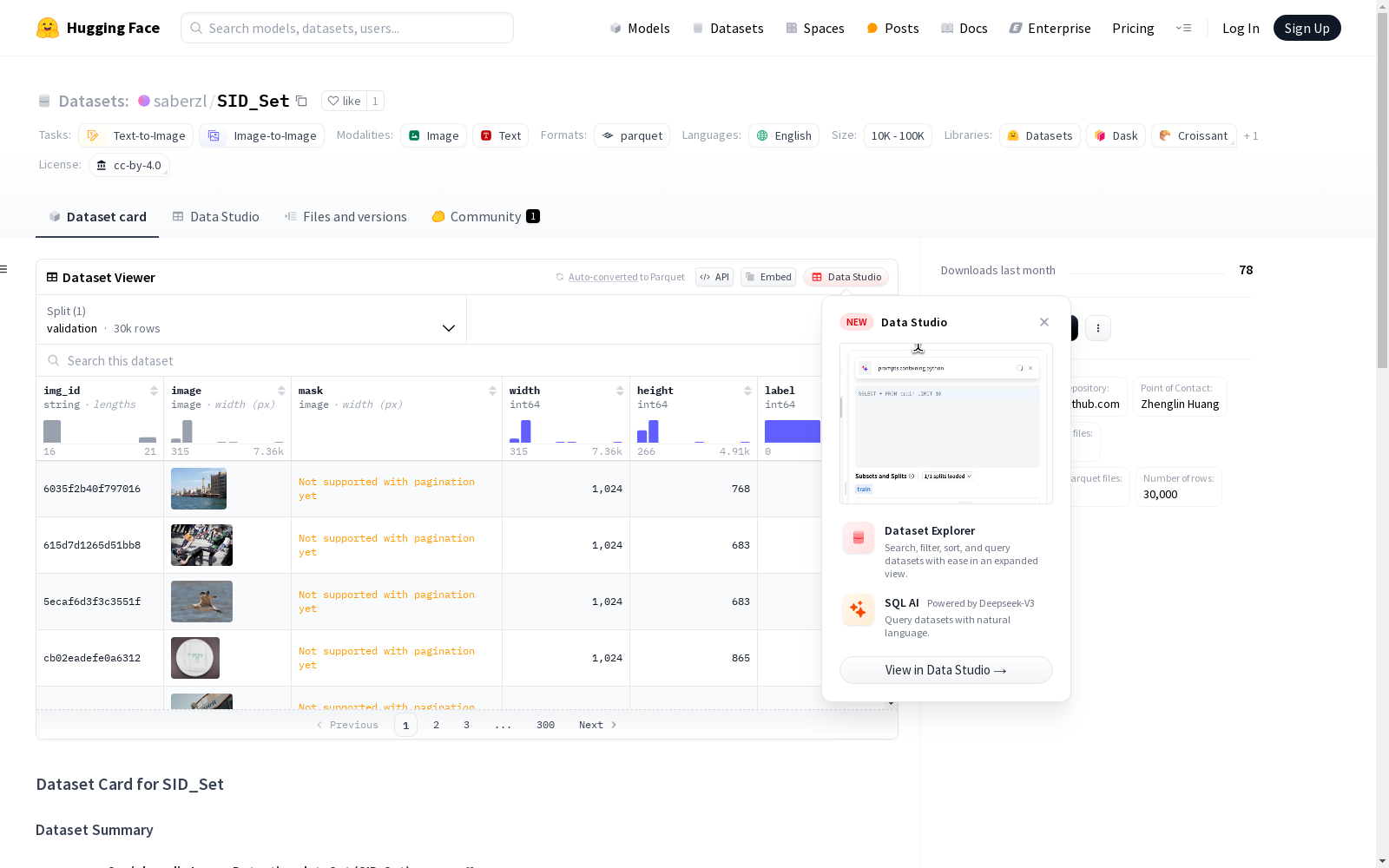
这是一个包含图片及其相关信息的图像数据集。每条数据包括图片ID、图片、掩码、图片宽度、图片高度和标签。数据集被分割为验证集,验证集包含30000个样本。
This is an image dataset containing images and their associated information. Each data entry includes an image ID, the image, a mask, image width, image height, and a label. The dataset is split into a validation set, which consists of 30,000 samples.
创建时间:
2025-03-12
搜集汇总
数据集介绍
构建方式
SID_Set数据集的构建,依托于大规模的AI生成与篡改技术,以及真实图片的广泛收集。该数据集包含了30万张AI生成或篡改的图片以及真实图片,每一张图片都附带了详尽的标注信息。图片的来源涵盖了COCO数据集中的真实图片,以及全合成和篡改的图片,这些图片被逐一分配了唯一的标识符和相应的类别标签。
特点
该数据集具有三个显著特点:一是其庞大的数据量,二是图片类型的多样性,覆盖了全合成和篡改图片的多个类别,三是图片的真实性极高,许多图片通过肉眼难以与真实图片区分。此外,数据集提供了针对篡改图片的二进制掩码,用于突出显示被操纵的区域,以及用于分类的标签信息,以区分真实、全合成和篡改的图片。
使用方法
使用SID_Set数据集时,用户可以从其提供的三个数据划分中选取,即训练集、验证集和测试集。验证集包含3万张图片,可通过数据集配置文件中的路径进行访问。用户需要遵守Creative Commons Attribution 4.0国际许可协议,并在使用数据集时引用相关论文,以表明对该数据集的利用和研究成果的归属。
背景与挑战
背景概述
SID_Set,即社交媒体图像检测数据集,是由Zhenglin Huang及其团队于2025年创建的。该数据集的核心旨在提供一种用于检测、定位和解释社交媒体中深度伪造图像的工具。SID_Set具有三大优势:数据量庞大,涵盖了30万张AI生成或篡改的图像以及全面的注释;多样性广泛,包含各种类别的完全合成和篡改图像;真实度较高,大多数图像通过视觉检查难以与真实图像区分。该数据集的创建对社交媒体图像的深度伪造检测领域产生了重要影响,为相关研究提供了丰富的资源和基准。
当前挑战
在研究领域问题上,SID_Set面临的挑战包括如何精确地区分真实图像、合成图像以及篡改图像。构建过程中遇到的挑战主要包括数据的多样性和真实性的平衡,以及如何有效地标注和利用300万张图像进行训练和测试。此外,数据集的构建者还需面对如何防止数据泄露、确保测试集的独立性和公正性的问题。
常用场景
经典使用场景
在当前计算机视觉研究领域,SID_Set数据集因其独特的构造与丰富的标注,成为深度伪造图像检测任务中的经典资源。该数据集提供了大量的人工生成或篡改的图像以及真实的图像,并附有详尽的注释,使得研究者能够训练模型以区分真实图像与伪造图像,以及定位篡改区域。
衍生相关工作
基于SID_Set数据集,研究者已开展了一系列相关工作,包括但不限于深度伪造检测算法的研究与改进、图像篡改定位技术的优化以及生成对抗网络在图像伪造中的应用等,这些研究进一步推动了计算机视觉与图像处理领域的发展。
数据集最近研究
最新研究方向
SID_Set数据集的构建,旨在应对社交媒体中日益严重的图像伪造和篡改问题。近期研究集中于深度学习模型在图像真伪识别、篡改定位与解释方面的应用。该数据集提供了大量的AI生成或篡改的图像以及真实图像,使得研究者能够在图像鉴伪领域进行深入探索。通过该数据集,研究人员可以训练模型以识别并定位图像中的篡改区域,对于提升社交媒体平台的内容审核机制具有重大意义,同时也为图像真伪识别技术的发展提供了新的研究方向和测试基准。
以上内容由遇见数据集搜集并总结生成


