RACA-PROJECT-MANIFEST
收藏Hugging Face2026-04-24 更新2026-04-25 收录
下载链接:
https://huggingface.co/datasets/aditijc/RACA-PROJECT-MANIFEST
下载链接
链接失效反馈官方服务:
资源简介:
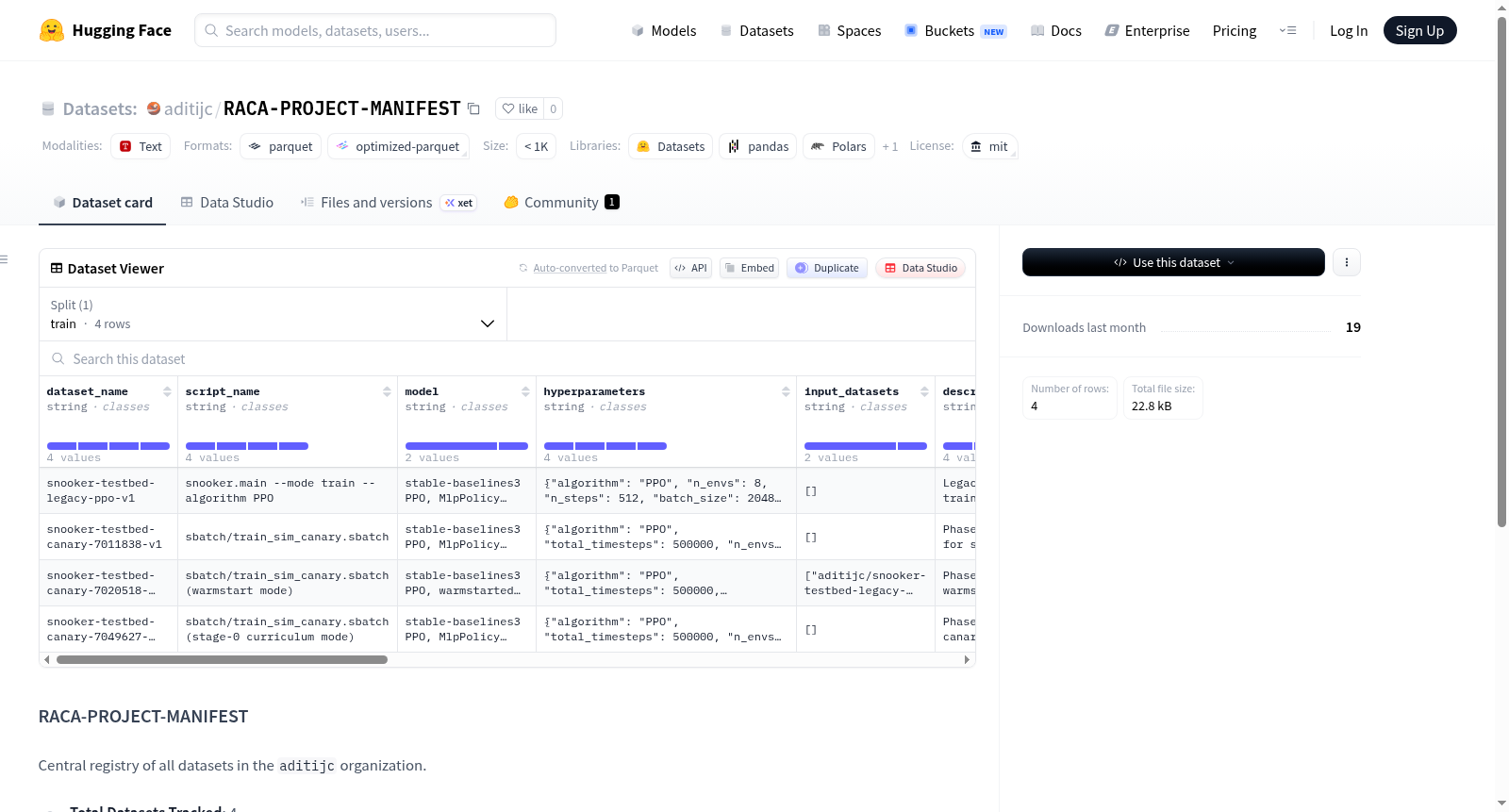
RACA-PROJECT-MANIFEST 是一个用于集中管理 'aditijc' 组织内所有数据集的注册表。该数据集采用 MIT 许可证,目前跟踪了 3 个数据集,最后更新时间为 2026 年 4 月 24 日。用户可以通过 HuggingFace 的 datasets 库加载该数据集,以获取所跟踪数据集的列表。然而,该 README 未提供关于被跟踪数据集的具体内容、结构或字段的详细信息。
创建时间:
2026-04-24
原始信息汇总
根据您提供的数据集详情页面信息,以下是关于 RACA-PROJECT-MANIFEST 数据集的概述:
数据集总览
- 数据集名称:RACA-PROJECT-MANIFEST
- 许可证:MIT
- 所属组织:aditijc
- 用途:作为 aditijc 组织下所有数据集的中央注册表
数据集规模
- 追踪的数据集总数:3 个
- 最后更新时间:2026-04-24T14:54:47.970529+00:00
使用方式
该数据集可通过 Hugging Face 的 datasets 库加载,示例代码如下:
python from datasets import load_dataset
manifest = load_dataset("aditijc/RACA-PROJECT-MANIFEST", split="train") print(f"Tracking {len(manifest)} datasets")
搜集汇总
数据集介绍
构建方式
RACA-PROJECT-MANIFEST数据集是作为aditijc组织下所有数据集的中央注册表而构建的。该清单通过程序化方式自动追踪并聚合组织内已发布数据集的元信息,当前涵盖3个数据集,且记录的最后更新时间为2026年4月24日。构建过程中注重维护数据集的唯一性与版本一致性,确保注册表能够准确反映组织数据资产的实时状态。
特点
该数据集的核心特点在于其作为统一索引枢纽的功能,将分散的数据集集中管控。通过轻量级的清单结构,用户可快速获取组织内数据集的全景视图。同时,设计上强调可扩展性,允许未来动态新增数据集条目,并附带精确的时间戳用于追踪更新历史,从而保障了数据治理的透明度和可追溯性。
使用方法
使用方法极为简洁,用户通过HuggingFace的datasets库,调用load_dataset函数并指定数据集标识符'aditijc/RACA-PROJECT-MANIFEST',即可加载训练集分割。加载后的对象可直接用于遍历或查询,例如通过len()函数获取当前追踪的数据集总数。该接口与主流的数据加载工作流无缝集成,便于纳入自动化数据处理管线。
背景与挑战
背景概述
在机器学习与自然语言处理领域蓬勃发展的当下,数据集作为模型训练与评估的基石,其系统化管理愈发关键。RACA-PROJECT-MANIFEST数据集创建于2026年,由aditijc机构的研究人员维护,作为其组织内所有数据集的中央注册表,目前追踪3个数据集,最新更新于2026年4月。该数据集的核心研究问题在于解决多数据集分散存储带来的检索与版本控制难题,通过提供统一索引,简化了数据资产的发现与调用流程。尽管规模尚小,但其标准化注册机制为组织级数据治理奠定了基础,对推动数据集生态的规范化和可复现性研究具备潜在影响力。
当前挑战
该数据集所解决的领域问题挑战在于,随着研究项目激增,不同来源的数据集常缺乏统一标识与元数据记录,导致重复创建、版本混淆及协作效率低下。RACA-PROJECT-MANIFEST通过集中化管理,降低了上述管理负担。然而,其构建过程中同样面临诸多挑战:首先,需确保注册表内数据集信息的完整性与准确性,避免遗漏或错误描述;其次,随着追踪数据集数量的增长,如何设计可扩展的架构以容纳成千上万个条目而不影响查询性能;此外,还需应对不同数据集格式、许可协议及更新频率的异质性,维持注册表的实时同步与兼容性。
常用场景
经典使用场景
在数据科学与人工智能的浩瀚星空中,数据集目录的规范化管理如同天文学中的星图,指引着研究者高效定位与利用数据资源。RACA-PROJECT-MANIFEST作为aditijc组织下属全部数据集的中央注册表,其经典使用场景在于为研究人员提供一站式数据资产索引,通过加载该清单即可快速获知组织内所有可用数据集的名称、版本及元信息,实现数据资产的统一发现与版本控制,极大提升了跨项目协作与数据复用的效率。
解决学术问题
随着机器学习领域数据规模的指数级增长,学术社区长期面临数据集分散、元信息缺失及版本混乱等痛点,导致研究复现困难与资源浪费。RACA-PROJECT-MANIFEST通过构建结构化的中央注册机制,系统性地解决了数据集发现与溯源问题,使研究者能够基于清单精准定位所需数据,同时确保数据集的依赖关系与更新历史清晰可查。这一创举为可重复性研究奠定了坚实基础,推动了开放科学与标准化数据治理范式的演进。
衍生相关工作
围绕数据集中央注册的理念,该清单已衍生出多项系统性工作,包括跨组织数据集目录的联邦化设计、基于版本差异的增量加载协议,以及结合知识图谱的数据集关系推理工具。这些工作在RACA-PROJECT-MANIFEST的基础上,进一步探索了元数据标注标准化、数据集互操作性以及自动数据溯源等前沿方向,共同编织起现代机器学习中数据资产治理的完整技术生态。
以上内容由遇见数据集搜集并总结生成


