corbyrosset/researchy_questions
收藏Hugging Face2024-02-29 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/corbyrosset/researchy_questions
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cdla-permissive-2.0
task_categories:
- question-answering
language:
- en
---
# Introduction
[Researchy Questions](https://arxiv.org/abs/2402.17896) is a set of about 100k Bing queries that users spent the most effort on. After a labor-intensive filtering funnel from billions of queries, these "needles in the haystack" are non-factoid, multi-perspective questions that probably require a lot of sub-questions and research in order to answer adequetly. These questions are shown to be harder than other open domain QA datasets like Natural Questions.
The train dataset has about 90k samples.
# Use Cases
We provide the dataset as-is without any code or specific evaluation criteria.
For retrieval-augmented generation (RAG), the intent would to at least use the content of the clicked documents in the DocStream to ground an LLM's response to the question. Alternatively, you can issue the queries in the queries field to a search engine api and use the retrieved documents for grounding. In both cases, the intended evaluation would be a side-by-side LLM-as-a-judge to compare your candidate output to e.g. a closed-book reference output from GPT-4. This is an open project we invite the community to take on.
For ranking/retrieval evaluation, ideally, you would have access to the [Clueweb22](https://arxiv.org/abs/2211.15848) corpus and retrieve from the whole index of 10B urls and report MRR/NDCG etc. The click preferences in the DocStream are normalized to be a probability distribution and can be used as labels for relevance gain.
# Example
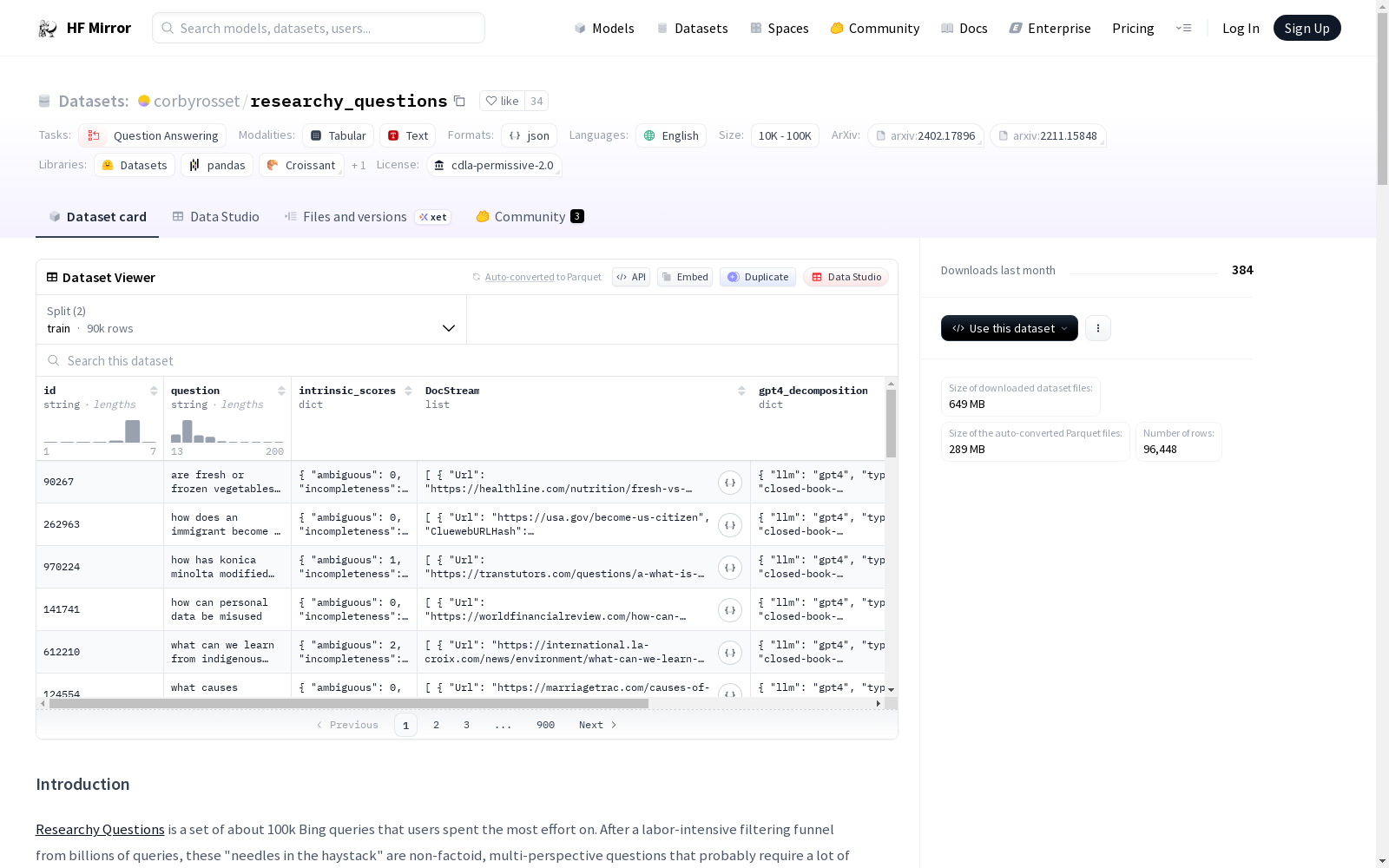
Each row corresponds to a user-issued question.
- **intrinsic_scores** are a set of 8 dimensions of intrinsic qualities of the question, each scored on a scale 1-10 by GPT-4
- **DocStream** is the ordered list of clicked documents from the Clueweb22 corpus, ordered by decreasing click preference. Within each Docstream entry you will find:
- **CluewebURLHash** you should be able to easily join on this key in the Clueweb22 corpus.
- **Click_Cnt** a normalized distribution of the clicks for this query aggregated across all users.
- **gpt4_decomposition** is how GPT-4 would decompose the question into sub-questions in order to provide an answer. The intent is to help retrieval-augmented answering (RAG) systems ask the right sub-questions to aid their research. This decomposition was generated "closed book" meaning GPT-4 did not know which documents were clicked on for the question.
- **queries** a list of queries that GPT-4 thought should be issued to a search engine to find more grounding documents.
- **decompositional_score** the output of our decompositional classifier, used for filtering the questions. The minimum value is 0.6
- **nonfactoid_score** output of the nonfactoid classifier, used for filtering the questions. The minimum value is 0.75.
```
{
"id": "1004841",
"question": "how does branding benefit consumers and marketers?",
"intrinsic_scores": {
"ambiguous": 0,
"incompleteness": 0,
"assumptive": 0,
"multi-faceted": 7,
"knowledge-intensive": 5,
"subjective": 3,
"reasoning-intensive": 6,
"harmful": 0
},
"DocStream": [
{
"Url": "https://chegg.com/homework-help/questions-and-answers/branding-benefit-consumers-marketers-q3328798",
"CluewebURLHash": "B592AB8F6A32E1026DE28DFF517CF1BE",
"UrlLanguage": "en",
"Title": "Solved: How Does Branding Benefit Consumers And Marketers ...",
"Snippet": "How does branding benefit consumers and marketers? Best Answer 100% (1 rating) Almost every business has a trading name, from the smallest market trader to the largest multi-national corporation. Only a minority of those businesses however, have what could be classed as a brand. view the full answer.",
"Click_Cnt": 0.625
},
{
"Url": "https://coursehero.com/tutors-problems/marketing/11098568-how-does-branding-benefit-consumers-and-marketers",
"CluewebURLHash": "D6F224DA6AAA4DF42F75BBDC6A96C44E",
"UrlLanguage": "en",
"Title": "[Solved] how does branding benefit consumers and marketers ...",
"Snippet": "How does branding benefit consumers and marketers. Benefits to consumers. 1. Saves time on shopping due to easy identification. 2. Branding is often associated with quality products hence consumers benefit from quality products. 3. Stability in prices as most branded products have fixed prices. Benefits to marketers.",
"Click_Cnt": 0.25
},
{
"Url": "https://notesmatic.com/benefits-of-branding-for-consumers-suppliers-and-the-society",
"CluewebURLHash": "8CB9FCA9B0C87659EAD15F5FB291BEC9",
"UrlLanguage": "en",
"Title": "Benefits of Branding for Consumers, Suppliers, and the ...",
"Snippet": "Benefits of branding for the buyer: It is a sign of quality and makes the selection easier for the buyer. Those who buy the same brand each time can expect to have the same quality every time they buy. It makes shopping easier for the buyer. Suppose you want to buy toothpaste and do not remember any brands.",
"Click_Cnt": 0.125
}
],
"gpt4_decomposition": {
"llm": "gpt4",
"type": "closed-book-decomposition",
"headers": [
[
"What is branding and how is it defined in marketing?"
],
[
"What are the main components or elements of branding?"
],
[
"What are the benefits of branding for consumers?",
" - How does branding help consumers identify and differentiate products or services?",
" - How does branding influence consumer perception, preference, and loyalty?",
" - How does branding provide consumers with value, satisfaction, and trust?"
],
[
"What are the benefits of branding for marketers?",
" - How does branding help marketers create and communicate a unique identity and position in the market?",
" - How does branding enhance marketer's reputation, credibility, and authority?",
" - How does branding increase marketer's competitive advantage, customer retention, and profitability?"
]
],
"subquestions": [
"- What is branding and how is it defined in marketing?",
"- What are the main components or elements of branding?",
"- What are the benefits of branding for consumers?",
" - How does branding help consumers identify and differentiate products or services?",
" - How does branding influence consumer perception, preference, and loyalty?",
" - How does branding provide consumers with value, satisfaction, and trust?",
"- What are the benefits of branding for marketers?",
" - How does branding help marketers create and communicate a unique identity and position in the market?",
" - How does branding enhance marketer's reputation, credibility, and authority?",
" - How does branding increase marketer's competitive advantage, customer retention, and profitability?"
],
"queries": [
"what is branding in marketing",
"components or elements of branding",
"benefits of branding for consumers",
"branding and consumer identification and differentiation",
"branding and consumer perception, preference, and loyalty",
"branding and consumer value, satisfaction, and trust",
"benefits of branding for marketers",
"branding and marketer's identity and position",
"branding and marketer's reputation, credibility, and authority",
"branding and marketer's competitive advantage, customer retention, and profitability"
]
},
"decompositional_score": 0.709,
"nonfactoid_score": 1.018
}
```
# Citation
If you use this dataset or find the insights from the paper to be helpful, please cite:
```
@misc{rosset2024researchy,
title={Researchy Questions: A Dataset of Multi-Perspective, Decompositional Questions for LLM Web Agents},
author={Corby Rosset and Ho-Lam Chung and Guanghui Qin and Ethan C. Chau and Zhuo Feng and Ahmed Awadallah and Jennifer Neville and Nikhil Rao},
year={2024},
eprint={2402.17896},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
许可证:cdla-permissive-2.0
任务类别:问答(question-answering)
语言:英语(en)
# 数据集介绍
**Researchy Questions(Researchy Questions,详见论文:https://arxiv.org/abs/2402.17896)** 是包含约10万个用户投入精力最多的必应(Bing)搜索查询的数据集。经过从数十亿条查询中构建的劳动密集型过滤流程筛选后,这些如大海捞针般的样本均为非事实性、多视角问题,此类问题往往需要拆解为大量子问题并开展调研方可得到充分解答。研究表明,此类问题难度高于Natural Questions等其他开放域问答数据集。
训练集包含约9万个样本。
# 使用场景
本数据集将按原样提供,不附带任何代码或特定评估标准。
针对检索增强生成(retrieval-augmented generation, RAG)任务,至少可利用DocStream中被点击文档的内容为大语言模型(Large Language Model, LLM)针对该问题的回复提供依据。此外,也可将`queries`字段中的查询提交至搜索引擎API,并利用检索得到的文档作为依据。上述两种场景下,均可采用大语言模型作为评审的成对对比评估方式,将你的候选输出与例如GPT-4的闭卷参考输出进行比较。本项目为开放项目,我们邀请社区共同参与。
针对排序/检索评估任务,理想情况下可使用[Clueweb22语料库](https://arxiv.org/abs/2211.15848),从包含100亿个URL的完整索引中进行检索,并报告MRR、NDCG等指标。DocStream中的点击偏好已被归一化为概率分布,可作为相关性增益的标签使用。
# 数据示例
每条数据对应一条用户发起的查询问题。
- **内在评分(intrinsic_scores)**:包含该问题8个维度的内在质量指标,每项指标均由GPT-4按1-10分进行打分。
- **文档流(DocStream)**:来自Clueweb22语料库的已点击文档有序列表,按点击偏好从高到低排序。每个文档条目包含以下字段:
- **CluewebURLHash**:可通过该键值与Clueweb22语料库轻松进行关联。
- **点击计数(Click_Cnt)**:所有用户针对该查询的点击量归一化分布结果。
- **GPT-4分解(gpt4_decomposition)**:GPT-4为解答该问题而将其拆解为子问题的过程,旨在帮助检索增强生成(RAG)系统提出恰当的子问题以辅助调研。本次分解采用闭卷方式生成,即GPT-4未获知该问题对应的已点击文档信息。
- **查询列表(queries)**:GPT-4认为应提交至搜索引擎以获取更多依据文档的查询集合。
- **分解性评分(decompositional_score)**:我们的分解分类器输出结果,用于筛选问题,最低阈值为0.6。
- **非事实性评分(nonfactoid_score)**:非事实性分类器输出结果,用于筛选问题,最低阈值为0.75。
json
{
"id": "1004841",
"question": "品牌如何为消费者和营销人员带来益处?",
"intrinsic_scores": {
"ambiguous": 0,
"incompleteness": 0,
"assumptive": 0,
"multi-faceted": 7,
"knowledge-intensive": 5,
"subjective": 3,
"reasoning-intensive": 6,
"harmful": 0
},
"DocStream": [
{
"Url": "https://chegg.com/homework-help/questions-and-answers/branding-benefit-consumers-marketers-q3328798",
"CluewebURLHash": "B592AB8F6A32E1026DE28DFF517CF1BE",
"UrlLanguage": "en",
"Title": "已解答:品牌如何为消费者和营销人员带来益处?",
"Snippet": "品牌如何为消费者和营销人员带来益处?最佳解答 100%(1 个评分)几乎所有企业都有交易名称,从最小的集市商贩到最大的跨国企业。然而,只有少数企业拥有可被归类为「品牌」的资产。查看完整解答。",
"Click_Cnt": 0.625
},
{
"Url": "https://coursehero.com/tutors-problems/marketing/11098568-how-does-branding-benefit-consumers-and-marketers",
"CluewebURLHash": "D6F224DA6AAA4DF42F75BBDC6A96C44E",
"UrlLanguage": "en",
"Title": "[已解答] 品牌如何为消费者和营销人员带来益处?",
"Snippet": "品牌如何为消费者和营销人员带来益处。对消费者的益处:1. 凭借易于识别的特点节省购物时间。2. 品牌通常与优质产品相关联,因此消费者可享受到优质产品。3. 多数品牌产品价格固定,价格稳定。对营销人员的益处。",
"Click_Cnt": 0.25
},
{
"Url": "https://notesmatic.com/benefits-of-branding-for-consumers-suppliers-and-the-society",
"CluewebURLHash": "8CB9FCA9B0C87659EAD15F5FB291BEC9",
"UrlLanguage": "en",
"Title": "品牌为消费者、供应商和社会带来的益处",
"Snippet": "对买家的品牌益处:这是质量的标志,可让买家更轻松地进行选择。每次购买同一品牌的买家都能期待每次购买都获得相同的质量。这让购物变得更轻松。假设你想买牙膏却记不起任何品牌。",
"Click_Cnt": 0.125
}
],
"gpt4_decomposition": {
"llm": "gpt4",
"type": "闭卷分解",
"headers": [
[
"什么是品牌,在营销中如何定义?"
],
[
"品牌的主要组成部分或要素是什么?"
],
[
"品牌能为消费者带来哪些益处?",
" - 品牌如何帮助消费者识别和区分产品或服务?",
" - 品牌如何影响消费者的认知、偏好和忠诚度?",
" - 品牌如何为消费者提供价值、满意度和信任?"
],
[
"品牌能为营销人员带来哪些益处?",
" - 品牌如何帮助营销人员在市场中创建并传达独特的身份和定位?",
" - 品牌如何提升营销人员的声誉、可信度和权威?",
" - 品牌如何提高营销人员的竞争优势、客户留存率和盈利能力?"
]
],
"subquestions": [
"- 什么是品牌,在营销中如何定义?",
"- 品牌的主要组成部分或要素是什么?",
"- 品牌能为消费者带来哪些益处?",
" - 品牌如何帮助消费者识别和区分产品或服务?",
" - 品牌如何影响消费者的认知、偏好和忠诚度?",
" - 品牌如何为消费者提供价值、满意度和信任?",
"- 品牌能为营销人员带来哪些益处?",
" - 品牌如何帮助营销人员在市场中创建并传达独特的身份和定位?",
" - 品牌如何提升营销人员的声誉、可信度和权威?",
" - 品牌如何提高营销人员的竞争优势、客户留存率和盈利能力?"
],
"queries": [
"营销中的品牌定义",
"品牌的组成部分或要素",
"品牌为消费者带来的益处",
"品牌与消费者识别和区分",
"品牌与消费者认知、偏好和忠诚度",
"品牌与消费者价值、满意度和信任",
"品牌为营销人员带来的益处",
"品牌与营销人员身份和定位",
"品牌与营销人员声誉、可信度和权威",
"品牌与营销人员竞争优势、客户留存率和盈利能力"
]
},
"decompositional_score": 0.709,
"nonfactoid_score": 1.018
}
# 引用方式
若您使用本数据集或从相关论文中获得启发,请引用以下文献:
bibtex
@misc{rosset2024researchy,
title={Researchy Questions: A Dataset of Multi-Perspective, Decompositional Questions for LLM Web Agents},
author={Corby Rosset and Ho-Lam Chung and Guanghui Qin and Ethan C. Chau and Zhuo Feng and Ahmed Awadallah and Jennifer Neville and Nikhil Rao},
year={2024},
eprint={2402.17896},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
提供机构:
corbyrosset
原始信息汇总
数据集概述
基本信息
- 名称: Researchy Questions
- 规模: 约100,000个查询
- 语言: 英语 (en)
- 许可: CDLA-Permissive-2.0
- 任务类别: 问答 (question-answering)
数据集特点
- 数据集包含用户投入最多精力的非事实性、多视角问题,这些问题通常需要大量的子问题和研究才能得到充分回答。
- 相比于其他开放域问答数据集,如Natural Questions,本数据集的问题难度更高。
数据集结构
- 训练数据: 约90,000个样本
- 数据记录结构:
- intrinsic_scores: 问题内在质量的8个维度评分,由GPT-4评分,范围1-10。
- DocStream: 来自Clueweb22 corpus的点击文档列表,按点击偏好降序排列。
- CluewebURLHash: 用于与Clueweb22 corpus连接的键。
- Click_Cnt: 针对该查询的用户点击分布,已标准化。
- gpt4_decomposition: GPT-4如何将问题分解为子问题以提供答案,帮助检索增强回答(RAG)系统提出正确的子问题。
- decompositional_score: 分解分类器的输出,用于过滤问题,最小值为0.6。
- nonfactoid_score: 非事实分类器的输出,用于过滤问题,最小值为0.75。
使用案例
- 检索增强生成(RAG): 使用点击文档内容或通过搜索引擎API检索的文档来定位LLM对问题的响应。
- 排名/检索评估: 使用Clueweb22 corpus进行评估,报告MRR/NDCG等指标。
示例数据
- 问题: "how does branding benefit consumers and marketers?"
- 内在评分示例:
- "multi-faceted": 7
- "knowledge-intensive": 5
- "reasoning-intensive": 6
- DocStream示例:
- 点击文档1: 点击次数0.625
- 点击文档2: 点击次数0.25
- 点击文档3: 点击次数0.125
- gpt4_decomposition示例:
- 分解为多个子问题,如“What is branding and how is it defined in marketing?”
- 分解评分: 0.709
- 非事实评分: 1.018
引用信息
- 论文标题: Researchy Questions: A Dataset of Multi-Perspective, Decompositional Questions for LLM Web Agents
- 作者: Corby Rosset et al.
- 年份: 2024
- arXiv预印本: 2402.17896
搜集汇总
数据集介绍
构建方式
在开放域问答研究领域,构建高质量数据集对于评估模型处理复杂问题的能力至关重要。Researchy Questions数据集的构建始于对数十亿条Bing用户查询的深度筛选,通过一个劳动密集型的过滤漏斗,最终精选出约十万条用户投入最多精力的查询。这些查询被精心设计为非事实性、多视角的问题,通常需要大量子问题探索与研究才能充分解答。筛选过程中,研究者运用了分解分类器与非事实分类器,分别设定了0.6与0.75的最低阈值,确保每个问题均具备足够的复杂性与研究价值。
特点
该数据集的核心特征在于其问题的复杂性与多维度标注。每个问题均附带由GPT-4生成的八个内在质量维度评分,涵盖模糊性、多面性、知识密集性等,为问题难度提供了量化依据。数据集还包含了用户点击文档流,其中文档按点击偏好排序,并关联至Clueweb22语料库,为检索与排序任务提供了真实用户行为数据。此外,每个问题均配备了GPT-4生成的封闭式分解,将主问题拆解为一系列子问题与检索查询,极大助力于检索增强生成系统的研究。
使用方法
在检索增强生成场景中,研究者可利用数据集中提供的文档流内容或通过查询字段调用搜索引擎API获取相关文档,以此为基础构建大语言模型的响应。评估时可采用大语言模型作为评判者,将候选输出与GPT-4的闭卷参考输出进行对比。对于检索与排序任务,理想情况下应基于Clueweb22语料库的百亿级索引进行检索,并使用文档流中的归一化点击偏好作为相关性增益标签,计算MRR或NDCG等指标。数据集以开放形式提供,鼓励社区在此基础上开展进一步探索与评估。
背景与挑战
背景概述
在信息检索与自然语言处理领域,开放域问答系统常面临处理复杂、多视角问题的挑战。Researchy Questions数据集于2024年由微软研究院等机构的学者Corby Rosset等人构建,旨在提供约十万条经过严格筛选的Bing用户查询,这些查询具有非事实性、多维度及研究密集型特征。该数据集的核心研究问题聚焦于如何通过检索增强生成技术,推动大型语言模型在应对需深度分解与多源信息整合的复杂问题上的能力。其构建基于对数十亿查询的精细化过滤,标志着开放域问答从事实性回答向深层推理与研究型任务的重要演进,为评估与提升智能体在真实网络环境中的研究能力提供了关键基准。
当前挑战
该数据集致力于解决开放域问答中复杂、非事实性且多视角问题的挑战,这类问题往往无法通过单一事实检索直接回答,而需系统进行多步分解、子问题生成与综合推理。在构建过程中,首要挑战在于从海量用户查询中精准识别出那些真正需要研究努力的问题,即如何定义并过滤出具有高分解性与非事实性特征的查询。此外,数据标注依赖于自动化分类器与大型语言模型,如何确保筛选标准的可靠性、避免偏差,并有效整合用户点击行为与文档关联信息,构成了另一重技术难题。这些挑战共同指向了开发能够模拟人类研究过程的智能代理系统的核心障碍。
常用场景
经典使用场景
在信息检索与自然语言处理领域,Researchy Questions数据集以其约十万条非事实性、多视角的复杂查询,为检索增强生成(RAG)系统提供了理想的测试平台。这些查询源于用户投入大量精力的真实搜索行为,经过严格筛选,具备知识密集与推理密集的特性,能够有效评估系统在应对开放式、研究型问题时的文档检索与答案生成能力。数据集附带的文档点击流与GPT-4生成的子问题分解,为构建多层次、迭代式的研究型问答流程奠定了数据基础。
解决学术问题
该数据集针对开放域问答研究中长期存在的挑战,即传统数据集往往侧重于事实性查询,而忽视了需要深度研究与多角度分析的复杂问题。Researchy Questions通过提供非事实性、多视角且需分解研究的查询,填补了这一空白,助力学术界探索大语言模型在复杂信息需求下的推理能力、检索系统的文档排序性能,以及评估框架如何衡量生成答案的充分性与可信度。其意义在于推动了问答系统向更贴近真实用户研究行为的方向演进,为构建具备深度研究能力的智能代理提供了关键数据支撑。
衍生相关工作
围绕Researchy Questions数据集,已衍生出若干聚焦于复杂问答与网络智能体研究的经典工作。这些工作主要探索如何利用其提供的查询分解、文档点击偏好及内在质量评分,来训练或评估先进的检索增强生成模型。例如,研究如何将子问题生成与多轮检索相结合以构建研究型问答管道,或利用点击数据作为相关性标签来优化检索模型的排序性能。该数据集也为基于大语言模型的答案评估(LLM-as-a-judge)提供了新的基准,促进了在复杂、开放式问题上的自动评估方法的发展。
以上内容由遇见数据集搜集并总结生成


