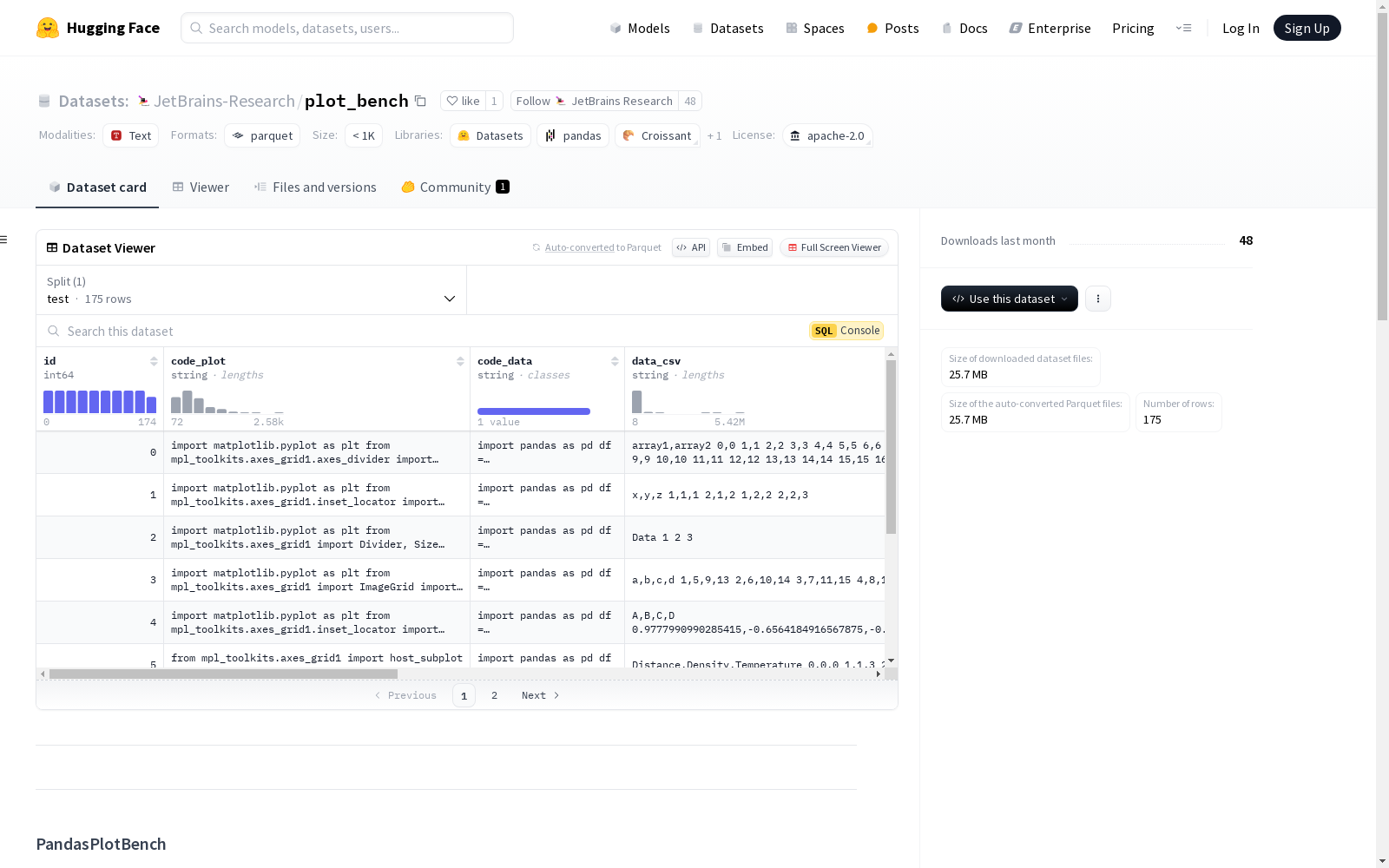
PandasPlotBench
收藏arXiv2024-12-04 更新2024-12-08 收录
下载链接:
https://huggingface.co/datasets/JetBrains-Research/plot_bench
下载链接
链接失效反馈官方服务:
资源简介:
PandasPlotBench是由JetBrains Research开发的人工策划数据集,旨在评估语言模型在数据可视化探索中的辅助效果。该数据集包含175个独特的任务,专注于根据自然语言指令生成Pandas DataFrame的绘图代码。数据集通过从Matplotlib图库中提取数据并进行处理生成,确保任务和数据文件是合成生成的,以避免数据泄露。PandasPlotBench的应用领域主要集中在数据分析和可视化,旨在解决复杂任务中生成可执行绘图代码的挑战。
PandasPlotBench is a manually curated dataset developed by JetBrains Research, designed to evaluate the auxiliary capabilities of language models in data visualization exploration. This dataset comprises 175 unique tasks focused on generating plotting code for Pandas DataFrames based on natural language instructions. The dataset is constructed by extracting and processing data from the Matplotlib gallery, ensuring that both the tasks and their associated data files are synthetically generated to prevent data leakage. Primarily targeted at the fields of data analysis and visualization, PandasPlotBench aims to address the challenge of generating executable plotting code for complex tasks.
提供机构:
JetBrains Research
创建时间:
2024-12-04
搜集汇总
数据集介绍
构建方式
PandasPlotBench数据集的构建基于Matplotlib图库中的501个脚本,通过一系列精心设计的步骤转化为175个独特的数据点。首先,在Jupyter环境中执行这些脚本,筛选出能够生成有效图形的脚本,数量减少至307个。接着,利用OpenAI GPT-4模型将每个脚本分割为数据生成部分和绘图部分,并手动验证分割的准确性,最终保留201个数据点。最后,通过GPT-4V模型生成详细的绘图任务指令,并进行手动验证,确保每个代码段能够正确绘制其关联的CSV文件中的数据,最终形成175个数据点。
使用方法
PandasPlotBench数据集主要用于评估大型语言模型(LLMs)在生成绘图代码方面的有效性。用户可以通过提供的模型生成绘图代码,并在Jupyter Notebook环境中执行,生成绘图图像。评估指标包括视觉评分和任务基础评分,通过GPT-4o Judge模型进行评分,确保评估的客观性和准确性。数据集和基准代码均可在HuggingFace和GitHub上获取,便于研究人员和开发者进行实验和验证。
背景与挑战
背景概述
PandasPlotBench数据集由JetBrains Research和Delft University of Technology的研究人员于2024年创建,旨在评估大型语言模型(LLMs)在生成数据可视化代码方面的有效性。该数据集专注于生成基于自然语言指令的Pandas DataFrame数据可视化代码,弥补了当前评估工具的不足,并扩展了其应用范围。PandasPlotBench包含175个独特的任务,通过实验评估了多个领先的LLMs在Matplotlib、Seaborn和Plotly三个可视化库中的表现。该数据集的引入为研究人员提供了一个强大的工具,以改进数据可视化和分析的用户体验。
当前挑战
PandasPlotBench数据集在构建过程中面临多个挑战。首先,生成完全可执行的复杂任务代码仍然是一个难题,尤其是在缺乏强大基准的情况下。其次,数据集的构建需要从Matplotlib库中筛选和转换数据,确保每个代码段能够正确绘制数据,这涉及大量的手动验证工作。此外,尽管LLMs在处理Matplotlib和Seaborn等流行库时表现良好,但在使用Plotly时仍存在显著挑战,这表明在不同可视化库之间的适应性仍需改进。最后,任务描述的长度对模型性能的影响也是一个重要的研究方向,尤其是在用户通常提供简短指令的情况下。
常用场景
经典使用场景
PandasPlotBench数据集的经典使用场景主要集中在评估大型语言模型(LLMs)在生成数据可视化代码方面的有效性。该数据集通过提供175个独特的任务,涵盖了从简单的数据处理到复杂的可视化需求,旨在测试模型根据自然语言指令生成Matplotlib、Seaborn和Plotly代码的能力。这种评估不仅限于代码的生成,还包括代码的执行和可视化结果的准确性,从而全面评估模型在实际数据探索中的辅助能力。
解决学术问题
PandasPlotBench数据集解决了当前学术研究中缺乏针对LLMs在数据可视化任务中生成准确代码的基准问题。通过提供详细的任务描述和合成数据,该数据集填补了现有基准在评估模型生成复杂可视化代码能力方面的空白。这不仅有助于提升模型在数据分析和可视化中的实用性,还为研究人员提供了一个标准化的工具,以比较和改进不同模型的性能,从而推动该领域的发展。
实际应用
在实际应用中,PandasPlotBench数据集被广泛用于开发和优化数据分析工具和用户界面。例如,数据科学家和分析师可以使用该数据集来训练和测试自动化数据可视化工具,这些工具能够根据用户的自然语言描述生成相应的可视化代码。此外,该数据集还可用于评估和改进现有的数据分析平台,确保其能够高效、准确地处理和展示复杂的数据集,从而提升用户体验和工作效率。
数据集最近研究
最新研究方向
在数据可视化领域,PandasPlotBench数据集的最新研究方向聚焦于评估大型语言模型(LLMs)在生成绘图代码方面的有效性。该数据集通过自然语言指令生成Pandas DataFrame的绘图代码,涵盖了Matplotlib、Seaborn和Plotly等多个可视化库。研究不仅关注任务压缩对模型性能的影响,还揭示了不同可视化库在LLMs中的表现差异,特别是Plotly的挑战。此外,该研究还探讨了任务描述长度对生成绘图质量的影响,发现即使任务描述简短,模型仍能保持较高的绘图能力,这为未来用户界面的开发提供了有价值的见解。
相关研究论文
- 1Drawing Pandas: A Benchmark for LLMs in Generating Plotting CodeJetBrains Research · 2024年
以上内容由遇见数据集搜集并总结生成


