IIIT5k
收藏arXiv2025-09-30 收录
下载链接:
https://cvit.iiit.ac.in/projects/SceneTextUnderstanding/IIIT5K.html
下载链接
链接失效反馈官方服务:
资源简介:
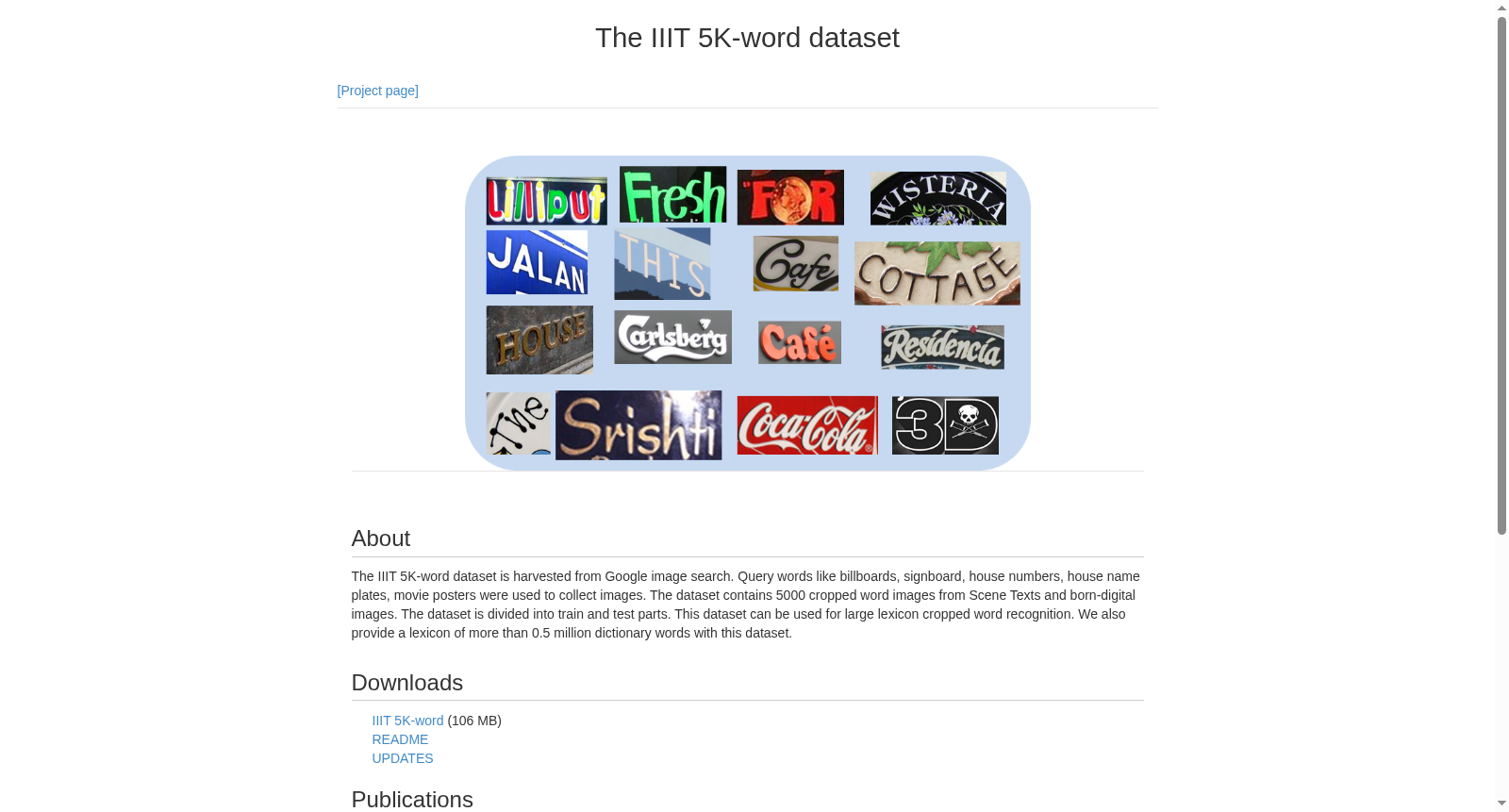
该数据集名为IIIT5k,是一个广受欢迎的场景文本识别基准,包含了字符级别的标注。它由从互联网上收集的5,000张裁剪后的单词图像组成,其中2,000张用于训练,3,000张用于测试。字符类别包括英文字母和数字。该数据集的规模为5,000张图像,主要任务为场景文本识别。
The IIIT5k dataset is a widely adopted benchmark for scene text recognition, with character-level annotations. It consists of 5,000 cropped word images collected from the Internet, where 2,000 samples are allocated for training and the remaining 3,000 for testing. The character categories include English letters and numerals. With a total of 5,000 images, its primary task is scene text recognition.
提供机构:
IIIT5k
搜集汇总
数据集介绍
背景与挑战
背景概述
IIIT5k数据集包含5000个从场景文本和数字图像中裁剪的单词图像,适用于大规模词典裁剪单词识别任务,并提供超过50万词的词典支持。
以上内容由遇见数据集搜集并总结生成


