wittenator/imagenet
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/wittenator/imagenet
下载链接
链接失效反馈官方服务:
资源简介:
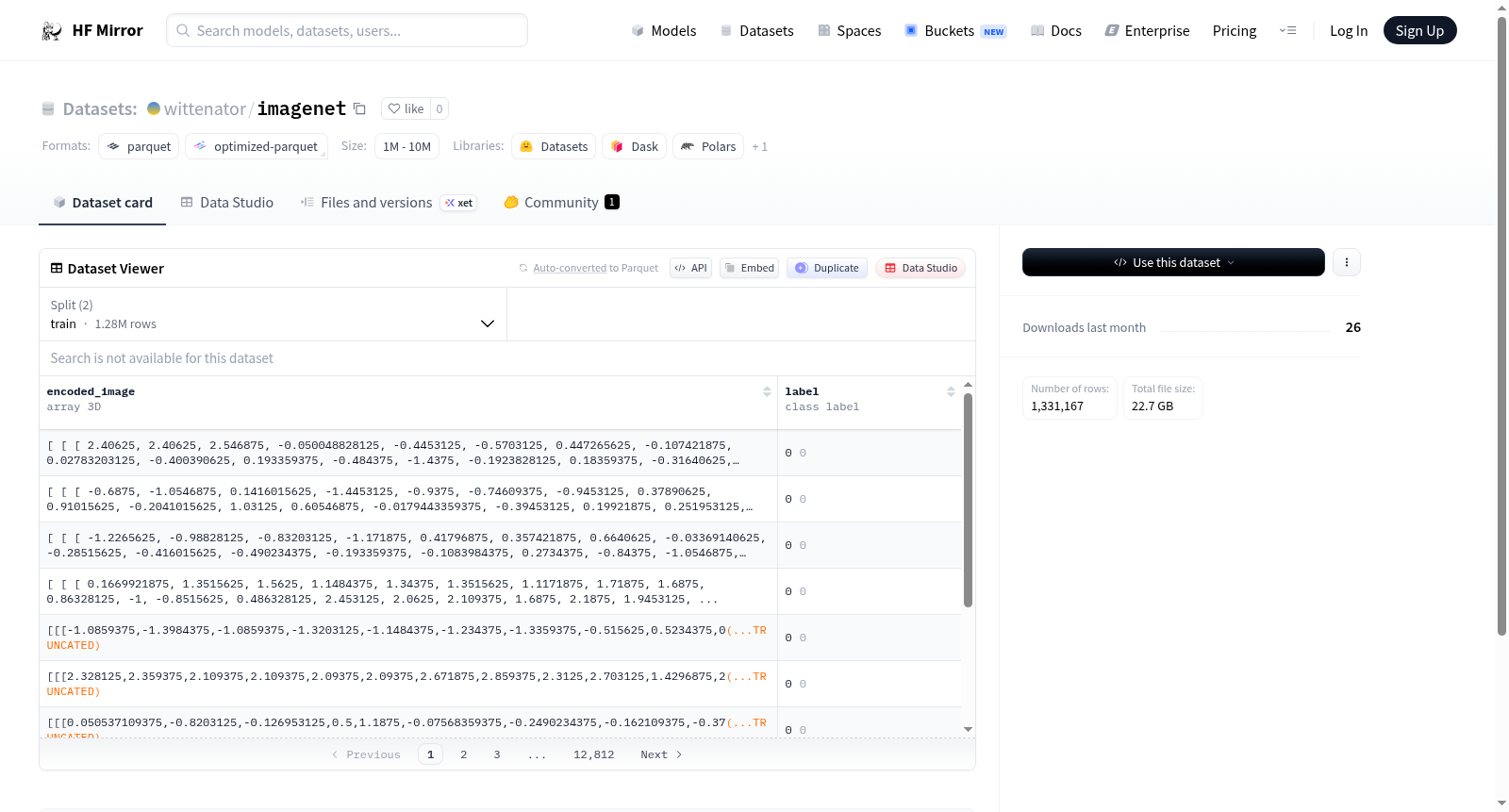
该数据集名为madebyollin~sdxl-vae-fp16-fix,是一个用于图像生成或处理任务的数据集,特别针对Stable Diffusion XL(SDXL)模型的变分自编码器(VAE)。数据以半精度浮点16位格式存储,并可能修复了某些技术问题。数据集包含编码后的图像表示,每个样本由形状为[4, 32, 32]的float32数组(encoded_image)组成,表示图像的潜在空间编码;同时包含一个类别标签(label),范围从0到867,共868个类别,可能用于分类或条件生成任务。数据集适用于训练或评估与VAE相关的机器学习模型,如图像重建、生成或特征学习。
The dataset named madebyollin~sdxl-vae-fp16-fix is designed for image generation or processing tasks, specifically related to the Variational Autoencoder (VAE) of the Stable Diffusion XL (SDXL) model. It is stored in half-precision floating-point 16-bit format and may include fixes for certain technical issues. The dataset consists of encoded image representations, where each sample includes a float32 array with shape [4, 32, 32] (encoded_image), representing the latent space encoding of an image, along with a class label (label) ranging from 0 to 867, totaling 868 categories, potentially used for classification or conditional generation tasks. This dataset is suitable for training or evaluating machine learning models involving VAEs, such as image reconstruction, generation, or feature learning.
提供机构:
wittenator
搜集汇总
数据集介绍
构建方式
ImageNet数据集是一个专为图像分类任务设计的大规模基准库,其核心构建过程源于对自然图像的精细化收集与标注。该数据集以`madebyollin~sdxl-vae-fp16-fix`为配置名称,采用特征工程的思想,将原始图像通过预训练的SDXL-VAE模型编码为紧凑的潜在表示,存储为形状为(4, 32, 32)的浮点张量。同步保留的类别标签则覆盖了从'0'到'867'的868个细粒度类别,构成了一个结构化的映射字典,实现了从高维视觉数据到低维语义空间的转化。
特点
此版本ImageNet数据集呈现出鲜明的技术革新特征,其最核心的亮点在于数据形态的转变——告别传统的RGB像素矩阵,转而采用经由变分自编码器压缩后的潜在编码,极大缩减了单样本的数据体积。这种设计不仅提升了存储与传输效率,还为下游生成式模型的训练提供了接近隐空间分布的原料。同时,标签系统保留了ImageNet原生的广泛类别覆盖,确保了数据在分类评测任务中的兼容性。
使用方法
用户可通过加载该数据集的`encoded_image`和`label`字段来直接接入模型训练,其中`encoded_image`已是模型可直接消费的编码向量。典型应用场景包括利用HuggingFace的`datasets`库进行批量加载,配合PyTorch或TensorFlow框架构建潜空间中的分类或生成流水线。由于编码后的张量已在视觉语义上凝聚,研究人员可省略常规的预处理流程,直接将其送入解码器或分类头进行操作。
背景与挑战
背景概述
ImageNet数据集诞生于2009年,由斯坦福大学李飞飞教授团队主导创建,旨在推动计算机视觉领域在大规模图像识别任务上的发展。该数据集包含超过1400万张手工标注的图像,覆盖约2.2万个语义类别,其核心研究问题在于如何利用海量标注数据训练出具有强泛化能力的视觉识别模型。ImageNet的发布深刻影响了深度学习时代的进程,尤其是其子集ImageNet大规模视觉识别挑战赛(ILSVRC)成为算法性能的基准测试平台,催生了AlexNet、VGG、ResNet等里程碑式架构,极大促进了目标检测、图像分类等视觉任务的突破。
当前挑战
ImageNet所解决的领域问题核心在于大规模图像分类的难题,即如何让模型从百万级杂乱图像中准确辨别数千类目标,而该数据集构建过程中面临多重挑战:其一,需要从互联网海量图片中筛选并清洗出语义清晰的图像,并确保类别覆盖广泛且均衡;其二,依赖众包平台进行人工标注,需设计严格的质控流程以消除标签噪声;其三,随着数据规模膨胀,对存储、索引和分布式处理能力提出极高要求;此外,类别间的细粒度差异和长尾分布问题也为模型鲁棒性带来持续挑战。
常用场景
经典使用场景
ImageNet数据集在计算机视觉领域被誉为里程碑式的基准测试平台,其经典使用场景涵盖图像分类、目标检测与语义分割等核心任务。该数据集包含超过1400万张标注图像,涵盖1000个物体类别,为深度神经网络的大规模训练提供了坚实基础。研究者们常利用ImageNet对卷积神经网络(如AlexNet、ResNet)进行预训练,通过迁移学习将学到的特征泛化至下游任务,从而推动模型性能的持续突破。
解决学术问题
ImageNet的出现有效解决了视觉识别领域长期存在的过拟合与泛化能力不足问题。它通过海量且多样化的标注数据,为难样本学习与细粒度分类提供了标准评估范式。该数据集极大促进了深度架构设计、正则化技术及数据增强策略的演进,其每年举办的ILSVRC竞赛更成为衡量算法先进性的关键标尺,深刻影响了现代计算机视觉研究的方向与进程。
衍生相关工作
基于ImageNet衍生的经典工作不胜枚举,包括表征学习中的ResNet、Inception等深度架构,以及目标检测领域的Faster R-CNN、YOLO等。可视化工具Grad-CAM与特征解耦方法如SimCLR、MoCo也借助该数据集验证了有效性。近年来,Vision Transformer、CLIP等跨模态模型均以ImageNet为关键训练或评估基准,持续推动着视觉-语言融合技术的创新与发展。
以上内容由遇见数据集搜集并总结生成


