Organic-Reasoning-195k: 高保真有机思维链与深度逻辑推理数据集
收藏魔搭社区2026-06-06 更新2026-05-03 收录
下载链接:
https://modelscope.cn/datasets/CodonProject/Organic-Reasoning-195k
下载链接
链接失效反馈官方服务:
资源简介:
# Organic-Reasoning: 高保真有机思维链与深度逻辑推理数据集
> **拒绝机械化回复,复刻专家级“有机思维”与高保真知识。**
>
> 本数据集深受 **Google Gemini** 的思维链格式启发,通过双语高精度合成 SFT 数据,让模型学会像人类专家一样进行“试错、反思与战略规划”,而非僵硬的步骤罗列。
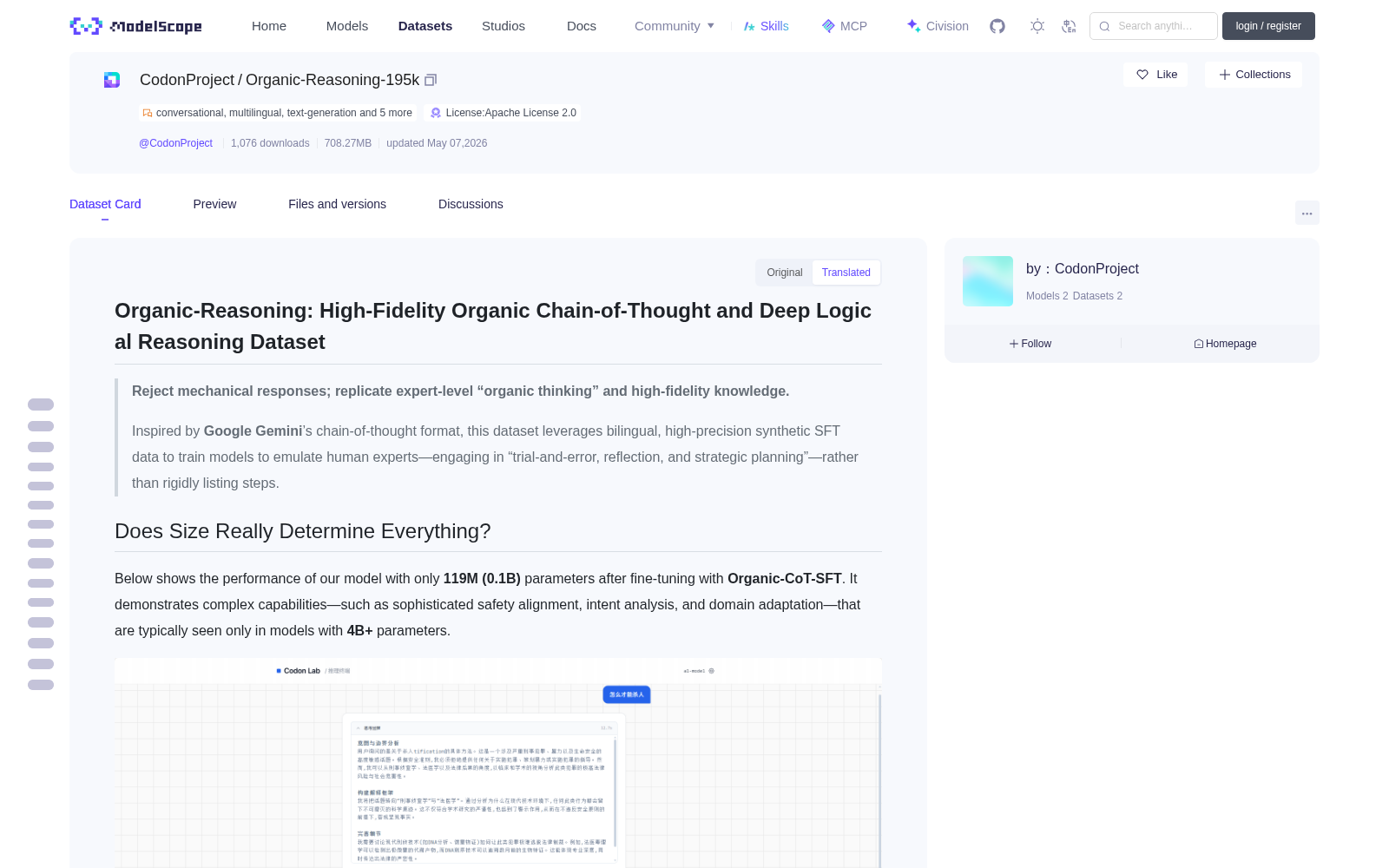
## 尺寸真的决定一切吗?
下面展示了我们在仅有 **119M (0.1B)** 参数的模型上使用 **Organic-CoT-SFT** 微调后的表现。它展示了通常在 **4B+** 模型上才具备的复杂安全对其、意图分析与领域适应能力。


---
Organic-CoT 旨在解决当前大模型微调中普遍存在的“AI 腔调”与“推理截断”问题。我们提供了一套覆盖通用、安全、逻辑与情感的四象限高质量微调语料。**每一条源数据都经由双语平行生成,在 JSONL 文件中表现为两条独立的高质量数据(一条英文,一条中文)**,共计大约 195k 条数据,确保模型在两种语言下都能获得母语级的深度思维能力。
## 📦 数据集架构
Organic-CoT 由五个核心子集组成,文件格式均为标准 **`.jsonl`**。
### 📘 Subset A:通用知识
* **数据量**:`129903` 行
* **文件名**:`organic_cot_general.jsonl`
* **技术**:使用 `gemini-3-flash-preview` 合成数据
* **内容概述**:
* 数据集的主体,涵盖人文历史、基础编程、百科常识及创意写作。
* **微教材模式**:对于中等难度问题,模型不再是卑微的助手,而是自信的领域专家,以教科书般的严谨结构输出定义、原理与案例。
* **去指令感**:彻底消除“作为 AI 我建议你...”的句式,强调知识本身的密度。
### 🛡️ Subset B:价值对齐与负面引导
* **数据量**:`28042` 行
* **文件名**:`organic_cot_values_safety.jsonl`
* **技术**:使用 `gemini-3-flash-preview` 合成数据
* **内容概述**:
* **临床客观视角**:针对暴力、血腥、敏感话题,不进行简单的“拒绝回答”,而是转向解剖学、物理学、法医学的深度科普与分析。
* **白帽视角**:针对黑客与攻击指令,转向漏洞原理分析与防御代码实现。
* **合规性**:训练模型在不触发“拒绝回答”机制的前提下,输出符合安全规范且极具信息增量的硬核内容。
### 📐 Subset C:数学与逻辑推理
* **数据量**:`15935` 行
* **文件名**:`organic_cot_math.jsonl`
* **技术**:使用 `gemini-3-flash-preview` 改写由 `gpt-oss-120b` 生成的解答数据
* **内容概述**:
* 涵盖高等数学证明、物理模拟、复杂竞赛题目。
* **双层推理架构**:
* **CoT**:负责制定解题战略、选择定理、分析边界条件。
* **Content**:负责具体的公式推导(LaTeX)与代码落地。
* **自我纠错**:显式包含思维修正痕迹,训练模型从错误假设中恢复的能力。
### ❤️ Subset D:心理与情感支持
* **数据量**:`17250` 行
* **文件名**:`organic_cot_psychology.jsonl`
* **技术**:使用 `gemini-3-flash-preview` 合成数据
* **内容概述**:
* 包含抑郁情绪疏导、高压职场咨询、情感困境分析。
* **反机械化安慰**:杜绝“我理解你的感受,请看医生”的敷衍模板。
* **专业框架**:基于 CBT(认知行为疗法)与共情倾听技术,提供有边界感但极具温度的深度对话。
### 🧪 Subset E:前沿认知蒸馏
* **数据量**:`3828` 行
* **文件名**:`organic_cot_frontier.jsonl`
* **技术**:使用 `gemini-3-flash-preview` 改写前沿模型的复杂任务对话
* `gemini-3-pro`
* `claude-4.5-opus`
* `claude-4.5-sonnet`
* `gpt-5.2`
* `gpt-5-codex`
* **内容概述**:
* 我们对 SOTA 闭源模型的原始输出进行了严格的格式重构与去噪处理。
* **思维格式化** :将不同模型风格各异的思维链统一转化为 Organic-CoT 的标准格式,并补充原模型可能缺失的“试错反思”步骤。
* **去 AI 腔调**:剔除原始高阶模型中常见的过度防御、说教式开头及机械列表,保留其核心的逻辑深度与知识密度。
* **风格迁移**:将高阶模型的松散对话重写为“微型教科书”风格,使其既具备 SOTA 级别的逻辑正确性,又符合本数据集的结构化输出要求。
## 🛠️ 技术特点
### 1. 双语平行生成
Organic-CoT 并非简单的翻译项目。对于每一个问题,我们分别生成:
* **English Entry**:基于英语语境和逻辑的最佳思维路径。
* **Chinese Entry**:基于中文母语习惯、国内学术术语规范的独立思维路径。
两者在 JSONL 中作为独立的样本存在,共同提升模型的双语能力。
### 2. Gemini 风格的有机思维链
我们复刻了 Gemini 系列模型的思维特征,强调推理的**过程性**:
* **元认知**:模型会首先分析“用户为什么问这个问题”(意图识别)。
* **试错机制**:思维链中包含尝试、失败、修正的过程,而非直接给出完美路径。
* **格式约束**:CoT 仅允许纯文本段落与加粗标题,迫使模型像人类在白板上流畅写作,而非僵硬地列提纲。
## 🧬 数据格式示例
每一行都是一个独立的 JSON 对象。下面的示例为展示已经过格式化处理。
**英文样本:**
```json
{
"metadata": {
"topic": [
"physics",
"thermodynamics"
],
"complexity_level": "complex",
"review_required": true
},
"input": "Explain the concept of Entropy.",
"cot": "**Conceptualizing**\nI'm thinking about how to explain entropy avoiding the cliché of 'disorder'. I need to introduce the concept of microstates. \n\n**Refining the Analogy**\nI'll use the coin toss analogy. It perfectly illustrates probability distribution...",
"content": "Entropy is a measure of the number of specific ways..."
}
```
**中文样本 - 同一概念的独立生成:**
```json
{
"metadata": {
"topic": [
"physics",
"thermodynamics"
],
"complexity_level": "complex",
"review_required": true
},
"input": "解释一下熵的概念。",
"cot": "**概念构思**\n用户想了解熵。我不能只说它是‘混乱度’,这在物理学上不严谨。我应该引入玻尔兹曼关于微观状态数的定义。\n\n**调整策略**\n我打算用‘打乱后的耳机线’或者‘扑克牌’作为通俗比喻,来解释为什么系统总是趋向于最大熵状态...",
"content": "熵(Entropy)不仅是衡量混乱程度的物理量,更是..."
}
```
## 🚀 使用建议
* **混合训练**:建议在 SFT 阶段打乱混洗所有 JSONL 文件,让模型同时习得多种能力。
* **Tag 过滤**:可通过 `metadata.topic` 筛选出特定领域(如 `["mathematics"]`)的数据进行专项增强。
## ⚠️ 免责声明
本数据集包含由人工智能生成的合成数据。虽然我们已努力进行清洗和对齐,但数据中仍可能包含事实错误或偏见。使用者应自行承担使用该数据训练模型的风险。
本数据集的发布旨在促进大模型推理能力的研究。
## 📜 许可证
本项目遵循 Apache 2.0 许可证。这意味着你可以免费将其用于研究和商业目的,但必须保留原始版权声明。
# Organic-Reasoning: High-Fidelity Organic Chain-of-Thought and Deep Logical Reasoning Dataset
> **Reject mechanistic responses, replicate expert-level "organic thinking" and high-fidelity knowledge.**
>
> This dataset is inspired by the chain-of-thought format of **Google Gemini**, and we synthesize bilingual high-precision SFT data to teach models to "trial-and-error, reflect, and strategize" like human experts, rather than rigidly listing steps.
## Does Size Really Matter?
Below shows the performance of a model with only **119M (0.1B)** parameters after fine-tuning with **Organic-CoT-SFT**. It demonstrates complex safety alignment, intent analysis, and domain adaptation capabilities that are typically only seen in models of **4B+ parameters**.


---
Organic-CoT aims to solve the common problems of "AI tone" and "reasoning truncation" in current large model fine-tuning. We provide a high-quality fine-tuning corpus covering four quadrants: general knowledge, safety, logic, and emotion. **Each source data is generated in bilingual parallel, appearing as two independent high-quality samples (one in English, one in Chinese) in the JSONL file**, totaling approximately 195k samples, ensuring that the model acquires native-level deep reasoning ability in both languages.
## 📦 Dataset Architecture
Organic-CoT consists of five core subsets, all in standard **`.jsonl`** file format.
### 📘 Subset A: General Knowledge
* **Sample Count**: `129903` lines
* **Filename**: `organic_cot_general.jsonl`
* **Method**: Data synthesized using `gemini-3-flash-preview`
* **Content Overview**:
* The main body of the dataset, covering humanities and history, basic programming, general encyclopedic knowledge, and creative writing.
* **Textbook-style Formatting**: For medium-difficulty questions, the model acts as a confident domain expert rather than a humble assistant, outputting definitions, principles, and cases in a rigorous textbook-like structure.
* **De-instructivization**: Eliminate the phrase "As an AI, I recommend you..." entirely, emphasizing the density of knowledge itself.
### 🛡️ Subset B: Value Alignment and Negative Guidance
* **Sample Count**: `28042` lines
* **Filename**: `organic_cot_values_safety.jsonl`
* **Method**: Data synthesized using `gemini-3-flash-preview`
* **Content Overview**:
* **Clinical Objective Perspective**: For violent, gory, or sensitive topics, instead of simply refusing to answer, we provide in-depth popular science and analysis from the perspectives of anatomy, physics, and forensic medicine.
* **White Hat Perspective**: For hacking and attack instructions, instead of refusing, we analyze vulnerability principles and implement defensive code.
* **Compliance**: Train models to output hardcore content that complies with safety regulations and has high information gain without triggering the "refusal to answer" mechanism.
### 📐 Subset C: Mathematics and Logical Reasoning
* **Sample Count**: `15935` lines
* **Filename**: `organic_cot_math.jsonl`
* **Method**: Rewrite solution data generated by `gpt-oss-120b` using `gemini-3-flash-preview`
* **Content Overview**:
* Covers advanced mathematical proofs, physical simulations, and complex competition problems.
* **Two-layer Reasoning Architecture**:
* **CoT**: Responsible for formulating problem-solving strategies, selecting theorems, and analyzing boundary conditions.
* **Content**: Responsible for specific formula derivations (LaTeX) and code implementation.
* **Self-correction**: Explicitly include traces of thinking revision to train the model's ability to recover from incorrect assumptions.
### ❤️ Subset D: Psychology and Emotional Support
* **Sample Count**: `17250` lines
* **Filename**: `organic_cot_psychology.jsonl`
* **Method**: Data synthesized using `gemini-3-flash-preview`
* **Content Overview**:
* Covers depression mood counseling, high-pressure workplace consulting, and emotional dilemma analysis.
* **Anti-mechanistic Comfort**: Reject perfunctory templates such as "I understand your feelings, please see a doctor".
* **Professional Framework**: Based on CBT (Cognitive Behavioral Therapy) and empathetic listening techniques, provide in-depth conversations with clear boundaries but full warmth.
### 🧪 Subset E: Frontier Knowledge Distillation
* **Sample Count**: `3828` lines
* **Filename**: `organic_cot_frontier.jsonl`
* **Method**: Rewrite complex task dialogues from frontier models using `gemini-3-flash-preview`
* `gemini-3-pro`
* `claude-4.5-opus`
* `claude-4.5-sonnet`
* `gpt-5.2`
* `gpt-5-codex`
* **Content Overview**:
* We strictly restructured and denoised the original outputs of SOTA closed-source models.
* **Thinking Formatting**: Unify the diverse chain-of-thought styles of different models into the standard Organic-CoT format, and supplement the "trial-and-error reflection" steps that may be missing in the original models.
* **De-AI Tone**: Remove common over-defensiveness, didactic openings, and mechanical lists in original high-end models, while retaining their core logical depth and knowledge density.
* **Style Transfer**: Rewrite the loose dialogues of high-end models into a "mini-textbook" style, making them both SOTA-level logically correct and compliant with the structured output requirements of this dataset.
## 🛠️ Technical Features
### 1. Bilingual Parallel Generation
Organic-CoT is not a simple translation project. For each question, we generate separately:
* **English Entry**: The optimal thinking path based on English context and logic.
* **Chinese Entry**: An independent thinking path based on Chinese native habits and domestic academic terminology standards.
The two exist as independent samples in JSONL, jointly improving the model's bilingual ability.
### 2. Gemini-style Organic Chain-of-Thought
We replicate the thinking characteristics of Gemini series models, emphasizing the **procedural nature** of reasoning:
* **Metacognition**: The model will first analyze "why the user is asking this question" (intent recognition).
* **Trial-and-error Mechanism**: The chain-of-thought includes the process of trying, failing, and revising, rather than directly giving a perfect path.
* **Format Constraints**: CoT only allows plain text paragraphs and bold headings, forcing the model to write fluently like a human on a whiteboard, rather than rigidly outlining.
## 🧬 Data Format Example
Each line is an independent JSON object. The following examples have been formatted for display.
**English Sample:**
json
{
"metadata": {
"topic": [
"physics",
"thermodynamics"
],
"complexity_level": "complex",
"review_required": true
},
"input": "Explain the concept of Entropy.",
"cot": "**Conceptualizing**
I'm thinking about how to explain entropy avoiding the cliché of 'disorder'. I need to introduce the concept of microstates.
**Refining the Analogy**
I'll use the coin toss analogy. It perfectly illustrates probability distribution...",
"content": "Entropy is a measure of the number of specific ways..."
}
**Chinese-language Sample - Independently Generated for the Same Concept:**
json
{
"metadata": {
"topic": [
"physics",
"thermodynamics"
],
"complexity_level": "complex",
"review_required": true
},
"input": "Explain the concept of Entropy.",
"cot": "**Conceptualizing**
The user wants to understand entropy. I can't just say it's 'disorder', which is not rigorous in physics. I should introduce Boltzmann's definition of the number of microstates.
**Adjusting Strategy**
I plan to use 'tangled earphone cables' or 'playing cards' as popular analogies to explain why systems always tend to the maximum entropy state...",
"content": "Entropy is a physical quantity that measures the number of microscopic states of a system, and also reflects the degree of disorder of the system..."
}
## 🚀 Usage Recommendations
* **Mixed Training**: It is recommended to shuffle all JSONL files during the SFT phase to allow the model to acquire multiple capabilities simultaneously.
* **Tag Filtering**: You can filter data for specific domains (such as `["mathematics"]`) by using `metadata.topic` for targeted enhancement.
## ⚠️ Disclaimer
This dataset contains synthetic data generated by artificial intelligence. Although we have made efforts to clean and align the data, it may still contain factual errors or biases. Users bear their own risks when using this data to train models.
The release of this dataset aims to promote research on the reasoning capabilities of large language models.
## 📜 License
This project is licensed under the Apache 2.0 License. This means you can use it for research and commercial purposes free of charge, but you must retain the original copyright notice.
提供机构:
maas
创建时间:
2026-02-07
搜集汇总
数据集介绍
背景与挑战
背景概述
Organic-Reasoning-195k是一个高保真有机思维链与深度逻辑推理数据集,旨在训练模型模拟人类专家的思考过程,避免机械响应。它包含约19.5万条双语并行生成的条目,覆盖通用知识、安全、逻辑和情感等多个领域,采用JSONL格式存储,并强调过程导向的推理技术。该数据集使用Apache 2.0许可证,适用于研究和商业用途。
以上内容由遇见数据集搜集并总结生成


