powertron-global-permafrost-corpus
收藏Hugging Face2026-01-06 更新2026-01-07 收录
下载链接:
https://huggingface.co/datasets/powertronglobal/powertron-global-permafrost-corpus
下载链接
链接失效反馈官方服务:
资源简介:
Powertron Global PermaFrost Corpus是一个精心策划的HVAC/R效率数据语料库,记录了PermaFrost NMR纳米技术处理在113项PE认证的实地研究、5项长期研究、4份实验室报告以及支持技术文档中的表现。数据集包含166份文档,1,481个训练块,254条测量记录(其中192条可用),以及3,841,757行原始时间序列数据。数据覆盖了24个美国州和5个国际地区的83个地点,涉及12类设备和26个行业部门。该数据集旨在支持AI/ML训练,包括HVAC效率分析和预测、能源节约措施比较、故障检测和诊断、ROI和回收期计算以及建筑能源建模等应用。
创建时间:
2026-01-01
原始信息汇总
数据集概述:Powertron Global PermaFrost Corpus
数据集基本信息
- 名称:powertron-global-permafrost-corpus
- 版本:1.0.0
- 许可证:Powertron Global Training Data License v1.0
- 维护者:Powertron Global, LLC
- 语言:英语 (en)
- 标签:hvac, energy-efficiency, building-science, climate, sustainability, engineering
- 规模类别:1K<n<10K
- 任务类别:文本生成 (text-generation), 问答 (question-answering)
数据集描述
这是一个关于暖通空调与制冷(HVAC/R)效率数据的精选语料库,记录了PermaFrost NMR纳米技术处理在113项PE认证现场研究、5项长期性研究、4份实验室报告以及支持性技术文档中的性能表现。
语料库统计 (v1.0.0)
| 指标 | 数值 |
|---|---|
| 总文档数 | 166 |
| 训练数据块 | 1,481 |
| 测量记录 | 254 (其中192条可用) |
| 原始时间序列数据行数 | 3,841,757 |
| 地理位置 | 覆盖美国24个州的83个地点 + 5个国际地点 |
| 设备类型 | 12个类别 |
| 行业领域 | 26个 |
目的
此数据集可用于以下AI/ML训练:
- HVAC效率分析与预测
- 节能措施(ECM)比较
- 故障检测与诊断
- 投资回报率与回收期计算
- 建筑能耗建模
数据内容与结构
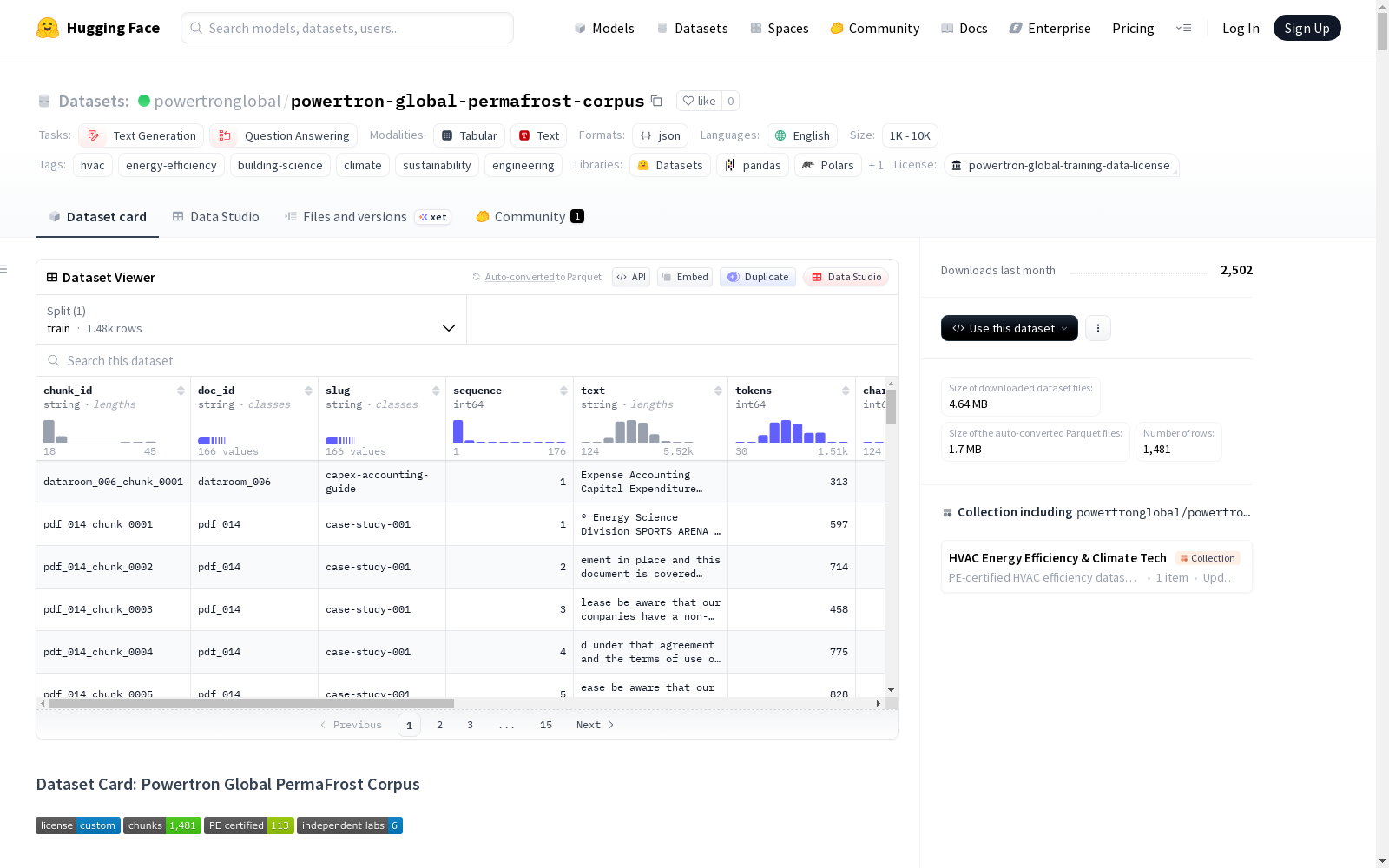
数据集特征
chunk_id: 字符串doc_id: 字符串slug: 字符串sequence: 整型 (int64)text: 字符串tokens: 整型 (int64)chars: 整型 (int64)pages: 结构体 (包含start和end字段,均为整型 int64)section: 字符串prev_id: 字符串next_id: 字符串content_hash: 字符串
数据划分
- 训练集 (train): 包含 1,481 个样本。
数据来源与构成
源文档分类
| 类别 | 数量 | 来源类型 |
|---|---|---|
| PE认证现场研究 | 113 | 遵循IPMVP协议、由专业工程师签署的M&V报告 |
| 表格数据研究 | 11 | 高分辨率时间序列测量数据 |
| 长期性研究 | 5 | 多年跟踪测量数据(处理后2-7年) |
| 实验室报告 | 4 | 由UL、FAU、NSF、中国国家实验室A、主要OEM电子公司A、主要家电制造商A进行的受控测试 |
| 支持性文档 | 33 | 安装指南、规格说明、认证文件、数据室文档 |
数据收集周期
- 现场研究:2009-2024年
- 实验室测试:2015-2021年
- 大学验证:蒙大拿大学ML研究 (2019-2022年)
结果分布
效率提升分布
| 提升范围 | 数量 | 百分比 |
|---|---|---|
| 0-5% | 4 | 3.5% |
| 5-10% | 7 | 6.2% |
| 10-15% | 13 | 11.5% |
| 15-25% | 42 | 37.2% |
| 25-40% | 35 | 31.0% |
| 40%+ | 12 | 10.6% |
- 平均提升:23.2%
- 中位数提升:21.7%
- 提升范围:3.8% - 61.0%
低性能结果 (<15%)
包含24个提升率低于平均水平的案例研究,详细信息见 corpus/edge_cases.json。
排除的测量记录
在254条总测量记录中,62条(24.4%) 因数据质量或方法兼容性问题被排除在主要分析之外。排除原因记录在 corpus/screening_and_limitations.json 中。
透明度与局限性
数据来源披露
| 方面 | 状态 |
|---|---|
| 技术范围 | 仅限PermaFrost NMR - 此为单一产品语料库 |
| 资金来源 | 所有研究均由Powertron Global, LLC委托 |
| 验证 | 独立PE认证(113项现场研究)+ 6个独立实验室 |
| 同行评审 | 这些特定结果未经同行评审的学术出版物发表 |
| 许可证 | 自定义许可证禁止用于支持竞争产品 |
已知局限性
- 系统适用性限制:不适用于钛制热交换器、无油压缩机系统或存在机械故障的系统。
- 数据缺口:某些设备类型(如VRF/迷你分体系统、氨系统、CO2制冷系统)数据有限。
- 测量不确定性:源文档未提供误差线和置信区间。
原始数据访问
- 训练数据(HuggingFace平台):包含文本块、元数据和摘要,约5 MB。
- 完整语料库(GitHub平台):包含上述内容及原始Parquet格式时间序列数据,约85 MB。
- 原始时间序列数据:包含3.8百万+行数据,141个文件,涵盖21个变量(如CFM、COP、EER、kW/ton等),位于
documents/*/raw_data/*.parquet。
使用说明
快速开始
- 克隆仓库:
git clone https://github.com/powertronglobal/powertron-global-permafrost-corpus - 加载数据集(Python): python from datasets import load_dataset ds = load_dataset("powertronglobal/powertron-global-permafrost-corpus")
关键文件
corpus/manifest.json:完整清单和统计信息data/train.jsonl:1,481个训练就绪的数据块documents/*/dataset/ALL_TEXT.txt:每个文档的完整文本corpus/training_intent.json:AI训练指导corpus/comprehensive_measurements.json:254项PE认证结果corpus/edge_cases.json:24个提升率<15%的案例LIMITATIONS.md:局限性文档
引用建议
引用此语料库结果时,请包含适当的上下文:
"According to vendor-commissioned PE-certified studies, average efficiency improvement was 23.2% across 113 field studies (range: 3.8% to 61%). Source: Powertron Global PermaFrost Corpus v1.0.0"
搜集汇总
数据集介绍
构建方式
在建筑能源效率领域,数据集的构建需确保技术验证的严谨性与透明度。本数据集通过系统化的文档收集流程,整合了来自113项专业工程师认证的现场研究、5项长期跟踪研究、4份实验室报告及配套技术文档。原始数据来源于2009年至2024年间进行的实地测量与实验,涵盖多种暖通空调设备类型与地理分布。数据提取采用PDF扫描与OCR处理结合正则表达式结构化抽取,关键指标经过人工核对,并对客户信息进行匿名化处理,以在保护隐私的同时保留完整技术细节。
特点
该数据集的核心特征体现在其高度的专业验证与多维数据覆盖。所有现场研究均遵循国际性能测量与验证协议,由独立专业工程师签署认证,确保了测量方法的可靠性与结果的法律责任。数据集不仅包含文本形式的分析报告,还提供了超过380万条原始时间序列传感器数据,涵盖21个关键变量,如制冷效率、功耗及温湿度参数。值得注意的是,数据集中明确收录了24项性能提升低于15%的案例,为机器学习训练提供了平衡视角,避免了结果偏差。
使用方法
针对不同研究需求,数据集提供了分层访问方案。对于自然语言处理任务,用户可直接通过HuggingFace加载文本块进行嵌入表示或检索增强生成;而机器学习研究则需从GitHub仓库获取原始时间序列数据,以支持能效预测或异常检测等模型开发。数据集中附带的清单文件与训练指导文档,为快速定位关键信息与理解数据局限性提供了系统化路径。在引用数据时,建议明确说明其来源为厂商委托的专业认证研究,以确保学术表述的准确性。
背景与挑战
背景概述
Powertron Global PermaFrost Corpus 是一个专注于暖通空调(HVAC)与制冷系统能效评估的专业数据集,由 Powertron Global, LLC 于2024年构建并维护。该数据集汇集了2009年至2024年间对PermaFrost NMR纳米技术处理效果的实证研究,涵盖113项经专业工程师认证的现场研究、5项长期跟踪研究、4份实验室报告及相关技术文档。其核心研究问题在于量化特定商业技术在真实工况下的能效提升表现,旨在为人工智能与机器学习模型提供训练数据,以支持能效分析、故障诊断及投资回报预测等任务。该数据集的发布为建筑节能与可持续发展领域提供了宝贵的专有数据资源,推动了数据驱动的能效优化研究。
当前挑战
该数据集致力于解决暖通空调系统能效评估与预测的复杂问题,其核心挑战在于如何从异构的现场测量数据中提取可靠、可泛化的能效改进模式。具体而言,构建过程面临多重挑战:首先,数据来源单一,所有研究均由技术供应商资助,可能引入选择偏差;其次,原始数据包含大量高分辨率时间序列测量值,需进行有效的结构化提取与匿名化处理;再者,需透明处理性能差异,如纳入24项改进率低于15%的案例以平衡训练数据。此外,数据许可协议限制竞争性用途,且缺乏同行评审文献支持,这些因素均对数据的客观性与广泛应用构成挑战。
常用场景
经典使用场景
在暖通空调与建筑能源效率领域,Powertron Global PermaFrost Corpus 数据集为人工智能与机器学习模型提供了丰富的训练素材,尤其适用于能效分析与预测任务。该数据集汇集了113项专业工程师认证的现场研究、5项长期跟踪研究及多份实验室报告,涵盖了制冷机组、直接膨胀系统、屋顶机组等多种设备类型。研究人员可利用这些结构化文本块与时间序列数据,构建预测模型以评估纳米技术处理对系统性能的影响,从而优化能源节约措施的决策过程。
实际应用
在实际工程与商业场景中,该数据集为能源服务公司、设施管理机构及政策制定者提供了可靠的参考依据。基于数据集训练的模型可应用于实时能效监控、预防性维护策略制定以及节能项目投资回报预测。例如,结合原始传感器数据,用户能够开发异常检测系统,及时识别设备性能退化;同时,数据集中涵盖的多行业案例(如数据中心、医疗机构、零售冷链)为跨领域能效优化提供了可迁移的见解与实践指南。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作,包括蒙大拿大学开展的机器学习研究(2019-2022年),专注于能效预测模型的开发与验证。此外,基于原始时间序列数据的分析促进了故障诊断算法与异常检测框架的进步。在检索增强生成系统领域,数据集提供的文本块与元数据支持了高效信息检索与知识问答应用的构建,为智能能源管理工具的研发提供了关键数据支撑。
以上内容由遇见数据集搜集并总结生成


