MikhailT/cmu-arctic
收藏Hugging Face2023-06-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/MikhailT/cmu-arctic
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
language:
- en
pretty_name: CMU Arctic
dataset_info:
features:
- name: speaker
dtype: string
- name: file
dtype: string
- name: text
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
splits:
- name: aew
num_bytes: 124532319
num_examples: 1132
- name: ahw
num_bytes: 65802249
num_examples: 593
- name: aup
num_bytes: 55771949
num_examples: 593
- name: awb
num_bytes: 106781643
num_examples: 1138
- name: axb
num_bytes: 67641455
num_examples: 593
- name: bdl
num_bytes: 97845496
num_examples: 1131
- name: clb
num_bytes: 123294691
num_examples: 1132
- name: eey
num_bytes: 55460671
num_examples: 592
- name: fem
num_bytes: 57115651
num_examples: 593
- name: gka
num_bytes: 64208369
num_examples: 592
- name: jmk
num_bytes: 103401609
num_examples: 1114
- name: ksp
num_bytes: 114080099
num_examples: 1132
- name: ljm
num_bytes: 51847413
num_examples: 593
- name: lnh
num_bytes: 120446549
num_examples: 1132
- name: rms
num_bytes: 127163811
num_examples: 1132
- name: rxr
num_bytes: 83873386
num_examples: 666
- name: slp
num_bytes: 72360869
num_examples: 593
- name: slt
num_bytes: 108798337
num_examples: 1132
download_size: 1577150976
dataset_size: 1600426566
size_categories:
- 10K<n<100K
---
# CMU Arctic Dataset
许可证:MIT许可证
语言:
- 英语
数据集友好名称:CMU Arctic
数据集详情:
数据特征:
- 名称:说话人,数据类型:字符串
- 名称:文件,数据类型:字符串
- 名称:文本,数据类型:字符串
- 名称:音频,数据类型:
采样率:16000 Hz
数据拆分:
- 名称:aew,字节数:124532319,样本数:1132
- 名称:ahw,字节数:65802249,样本数:593
- 名称:aup,字节数:55771949,样本数:593
- 名称:awb,字节数:106781643,样本数:1138
- 名称:axb,字节数:67641455,样本数:593
- 名称:bdl,字节数:97845496,样本数:1131
- 名称:clb,字节数:123294691,样本数:1132
- 名称:eey,字节数:55460671,样本数:592
- 名称:fem,字节数:57115651,样本数:593
- 名称:gka,字节数:64208369,样本数:592
- 名称:jmk,字节数:103401609,样本数:1114
- 名称:ksp,字节数:114080099,样本数:1132
- 名称:ljm,字节数:51847413,样本数:593
- 名称:lnh,字节数:120446549,样本数:1132
- 名称:rms,字节数:127163811,样本数:1132
- 名称:rxr,字节数:83873386,样本数:666
- 名称:slp,字节数:72360869,样本数:593
- 名称:slt,字节数:108798337,样本数:1132
下载总大小:1577150976 字节
数据集总大小:1600426566 字节
规模类别:10000 < n < 100000
---
# CMU Arctic 数据集
提供机构:
MikhailT
原始信息汇总
CMU Arctic 数据集概述
数据集基本信息
- 许可证: MIT
- 语言: 英语
- 数据集名称: CMU Arctic
数据集特征
- speaker: 字符串类型
- file: 字符串类型
- text: 字符串类型
- audio: 音频类型,采样率为16000 Hz
数据集分割
- aew: 1132个样本,124532319字节
- ahw: 593个样本,65802249字节
- aup: 593个样本,55771949字节
- awb: 1138个样本,106781643字节
- axb: 593个样本,67641455字节
- bdl: 1131个样本,97845496字节
- clb: 1132个样本,123294691字节
- eey: 592个样本,55460671字节
- fem: 593个样本,57115651字节
- gka: 592个样本,64208369字节
- jmk: 1114个样本,103401609字节
- ksp: 1132个样本,114080099字节
- ljm: 593个样本,51847413字节
- lnh: 1132个样本,120446549字节
- rms: 1132个样本,127163811字节
- rxr: 666个样本,83873386字节
- slp: 593个样本,72360869字节
- slt: 1132个样本,108798337字节
数据集大小
- 下载大小: 1577150976字节
- 数据集大小: 1600426566字节
- 大小类别: 10K<n<100K
搜集汇总
数据集介绍
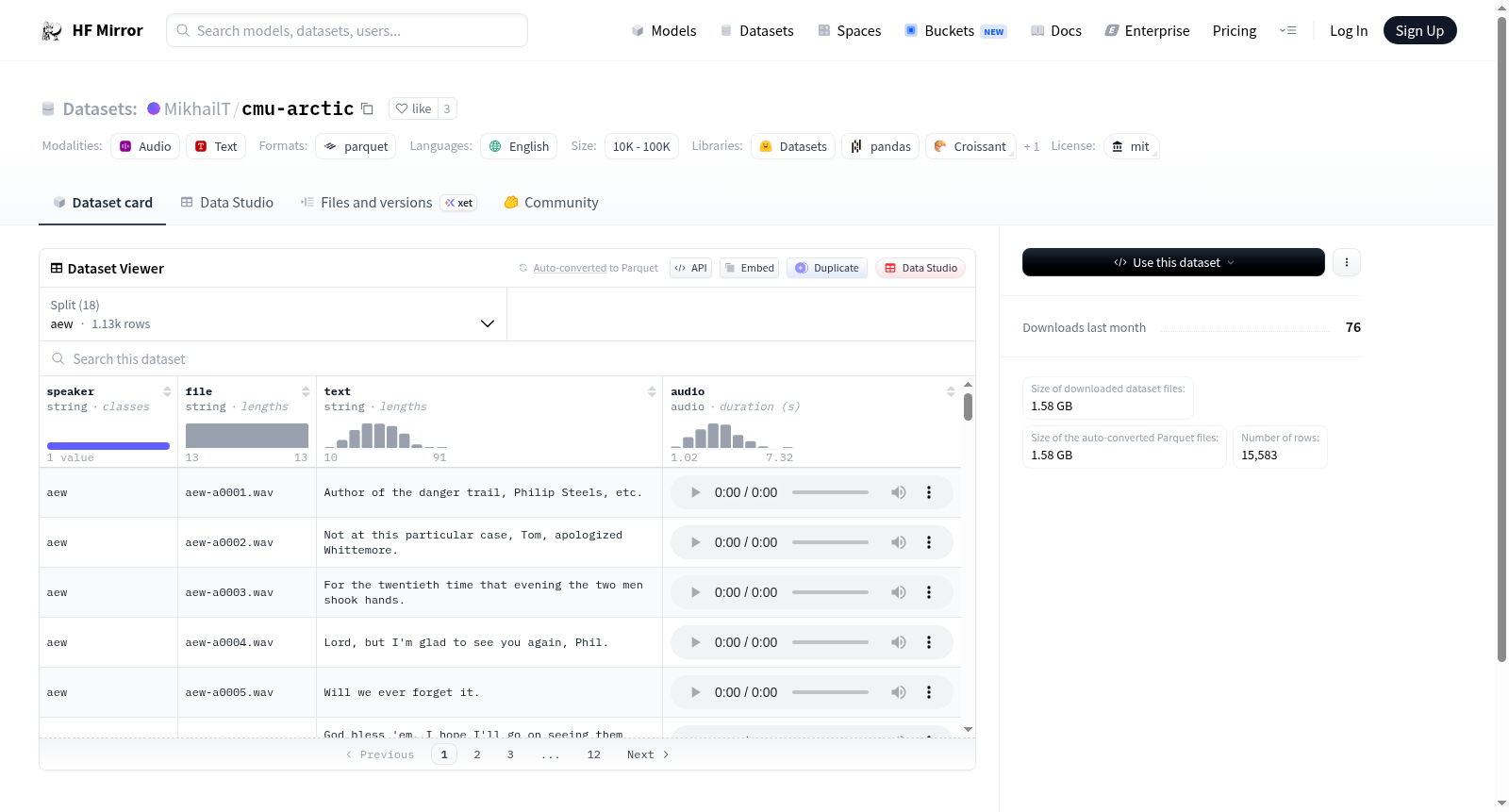
构建方式
在语音合成研究领域,高质量语音数据集的构建至关重要。CMU Arctic数据集由卡内基梅隆大学语言技术研究所精心构建,其核心在于收录了多位英语母语者的语音录音。每位发言者均录制了数百条语音样本,每条样本均配有精确的文本转录。录音过程在专业声学环境下进行,确保了音频信号的纯净度,并以16kHz的采样率统一保存,为后续的声学建模提供了标准化的高质量数据源。
特点
该数据集在语音技术领域以其丰富的说话人多样性和高质量音频而著称。数据集囊括了多位发音人,每位发音人对应一个独立的数据子集,例如aew、bdl、clb等,共计提供了超过一万条语音-文本对。其音频特征统一,采样率均为16kHz,确保了声学特征提取的一致性。这种多说话人、大规模且标注精确的架构,使其成为训练和评估文本到语音系统、说话人自适应模型以及语音转换算法的理想基准资源。
使用方法
对于语音合成与处理领域的研究者而言,该数据集提供了便捷的接入途径。用户可通过Hugging Face数据集库直接加载,利用其标准化的数据结构快速获取特定说话人的音频及其对应文本。典型应用流程包括:首先加载目标说话人子集,随后提取音频波形与文本标签,进而用于训练声学模型或进行语音质量评估。其清晰的字段划分和统一的音频格式,极大简化了数据预处理流程,支持研究者高效地开展各类语音生成与识别实验。
背景与挑战
背景概述
CMU Arctic数据集由卡内基梅隆大学语言技术研究所于2003年创建,旨在为语音合成研究提供高质量的多说话人语音语料库。该数据集收录了多位英语母语者的录音,涵盖不同性别与口音变体,其核心研究问题聚焦于构建自然流畅的文本到语音转换系统。作为早期开放语音数据集之一,CMU Arctic显著推动了参数化与拼接式语音合成技术的发展,为后续神经语音合成模型的演进奠定了数据基础。
当前挑战
该数据集致力于解决文本到语音转换中自然度与表现力不足的挑战,尤其在于建模多样化的发音风格与情感韵律。在构建过程中,研究人员面临录音环境一致性控制、说话人发音稳定性保持以及大规模语音标注成本高昂等难题。此外,早期录音设备的频响限制与背景噪声干扰,亦对语音信号的质量与纯净度提出了严峻考验。
常用场景
经典使用场景
在语音合成领域,CMU Arctic数据集作为一项经典资源,常被用于训练和评估文本到语音转换系统。该数据集包含多位英语母语者的高质量录音,覆盖了多样化的语音特征和发音风格,为研究者提供了丰富的声学建模素材。通过利用这些标注清晰的语音-文本配对数据,学者们能够构建出自然度较高的合成语音模型,尤其在参数化语音合成和统计声学建模方面展现出显著价值。
解决学术问题
CMU Arctic数据集有效解决了语音合成研究中数据稀缺与质量不均的难题,为声学模型训练提供了标准化、多说话人的语音资料。它助力于探索语音个性转换、韵律建模以及跨语言语音合成等前沿课题,推动了合成语音自然度与表现力的提升。该数据集的广泛使用促进了语音合成技术的理论发展,为后续研究奠定了坚实的实验基础。
衍生相关工作
围绕CMU Arctic数据集,学术界衍生了一系列经典研究工作,包括基于隐马尔可夫模型的语音合成系统、深度神经网络声学模型以及端到端的语音合成框架。这些工作不仅优化了合成语音的质量,还拓展了多说话人合成与语音转换的技术边界。该数据集也常被用作基准测试工具,推动了语音合成领域的标准化评估与比较研究。
以上内容由遇见数据集搜集并总结生成


