omegalabsinc/omega-multimodal
收藏Hugging Face2025-04-21 更新2024-05-25 收录
下载链接:
https://hf-mirror.com/datasets/omegalabsinc/omega-multimodal
下载链接
链接失效反馈官方服务:
资源简介:
OMEGA Labs Bittensor Subnet数据集是一个用于加速人工通用智能(AGI)研究和开发的多模态数据集。该数据集通过Bittensor去中心化网络提供,旨在成为世界上最大的多模态数据集,涵盖人类知识和创造的广泛领域。数据集包含超过100万小时的视频和3000多万个2分钟的视频片段,覆盖50多种场景和15000多个动作短语。数据集利用最先进的模型将视频组件转换为统一的潜在空间,从而开发强大的AGI模型,并有可能改变多个行业。
The OMEGA Labs Bittensor Subnet Dataset is a groundbreaking resource for accelerating Artificial General Intelligence (AGI) research and development. This dataset, powered by the Bittensor decentralized network, aims to be the worlds largest multimodal dataset, capturing the vast landscape of human knowledge and creation. With over 1 million hours of footage and 30 million+ 2-minute video clips, the OMEGA Labs dataset will offer unparalleled scale and diversity, covering 50+ scenarios and 15,000+ action phrases. By leveraging state-of-the-art models to translate video components into a unified latent space, this dataset enables the development of powerful AGI models and has the potential to transform various industries.
提供机构:
omegalabsinc
原始信息汇总
OMEGA Labs Bittensor Subnet Dataset Summary
Overview
The OMEGA Labs Bittensor Subnet Dataset is designed to accelerate Artificial General Intelligence (AGI) research by providing a large-scale, multimodal dataset. This dataset includes over 1 million hours of footage and more than 30 million 2-minute video clips, covering over 50 scenarios and 15,000+ action phrases. It leverages advanced models to translate video components into a unified latent space, facilitating the development of AGI models.
Key Features
- Constant Stream of Fresh Data: The dataset is regularly updated with new entries, with an estimated addition of 5 million new videos daily.
- Rich Data: Data quality is ensured through a reward system based on diversity, richness, and relevance of the data.
- Latent Representations: Pre-computed ImageBind embeddings for video, audio, and captions are provided.
- Empowering Digital Agents: The dataset supports the development of intelligent agents capable of complex task navigation and user assistance.
- Flexible Metadata: Users can filter the dataset by various criteria, including topic relevance and cosine similarity.
Dataset Structure
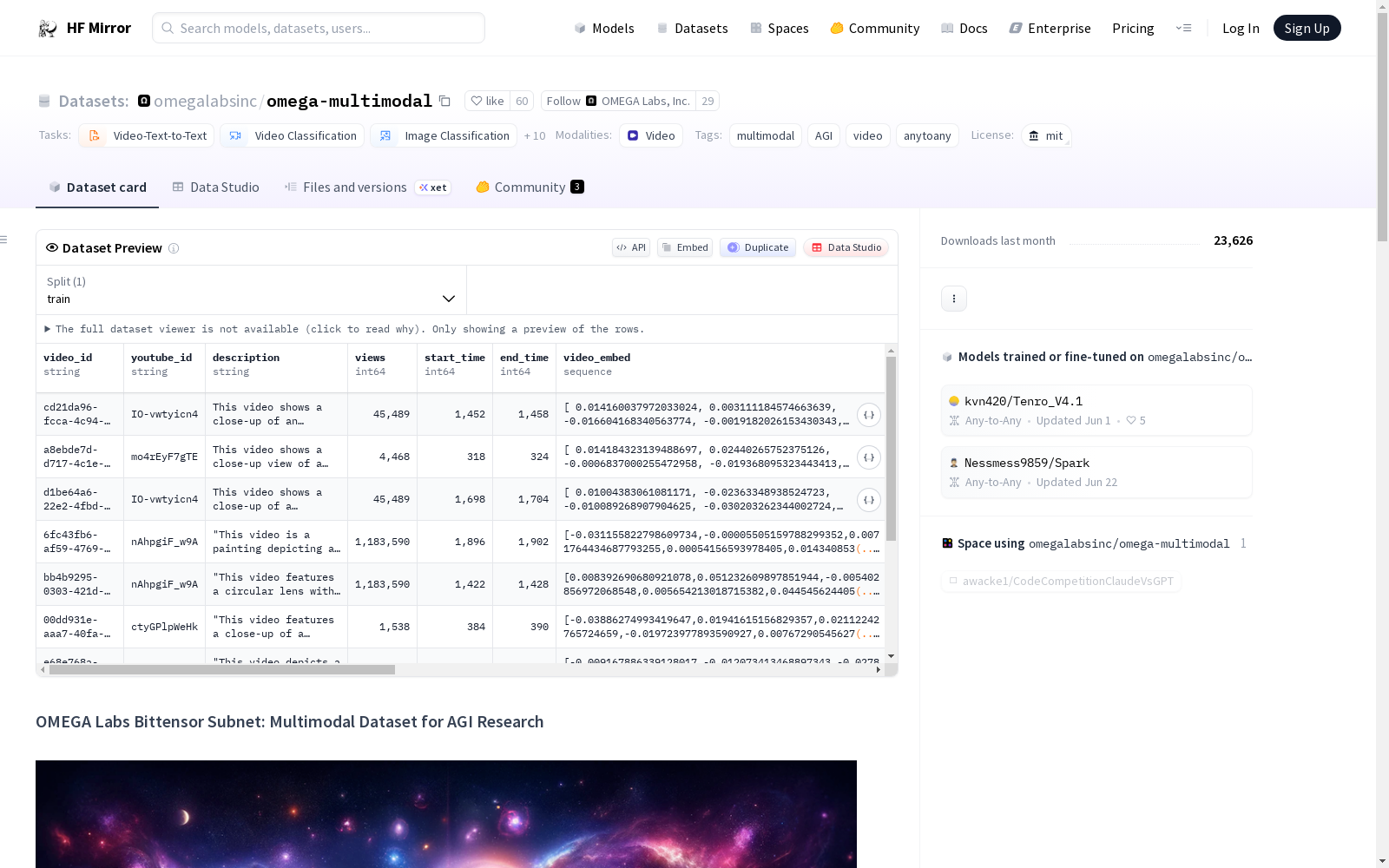
The dataset includes the following columns:
video_id: Unique identifier for each video clip.youtube_id: Original YouTube video ID.description: Description of the video content.views: Number of views on the original YouTube video.start_time: Start time of the clip within the original video.end_time: End time of the clip within the original video.video_embed: Latent representation of the video content.audio_embed: Latent representation of the audio content.description_embed: Latent representation of the video description.description_relevance_score: Relevance score of the video description.query_relevance_score: Relevance score of the video to the search query.query: Search query used to retrieve the video.submitted_at: Timestamp of when the video was added to the dataset.
Applications
The dataset is applicable for various AGI research and development tasks, including:
- Unified Representation Learning: Training models to learn across different modalities.
- Any-to-Any Models: Developing models that can translate between various modalities.
- Digital Agents: Creating intelligent agents for complex task management.
- Immersive Gaming: Enhancing gaming environments with realistic physics and interactions.
- Video Understanding: Advancing video processing tasks like transcription, motion analysis, and object detection.
搜集汇总
数据集介绍
构建方式
在人工智能研究领域,构建高质量的多模态数据集是推动通用人工智能发展的关键。OMEGA Labs Bittensor Subnet数据集依托Bittensor去中心化网络,通过全球矿工持续爬取网络视频资源,每日可新增超过500万条视频片段。该数据集采用ImageBind模型对视频、音频及文本描述进行嵌入表示,并基于余弦相似度评估数据的多样性、丰富度与相关性,以此激励矿工贡献高质量内容,确保数据集的规模与质量同步提升。
特点
该数据集以其海量规模与动态更新机制著称,涵盖超过100万小时视频素材及3000余万条两分钟片段,覆盖50多种场景和15000多个动作短语。其核心特征在于预计算的视频、音频及文本的潜在表示,便于研究者直接进行跨模态分析。此外,数据集提供灵活的元数据过滤功能,允许用户根据主题相关性或余弦相似度筛选特定片段,为训练任务提供精准数据支持。
使用方法
研究者可通过HuggingFace平台直接访问该数据集,利用其预计算的嵌入表示进行跨模态学习任务,如统一表示学习或任意模态转换模型开发。数据集的结构化字段,如视频标识符、嵌入向量及相关性评分,支持快速检索与过滤,适用于视频理解、数字智能体构建等应用场景。用户还可结合Bittensor网络参与数据贡献,推动数据集的持续扩展与优化。
背景与挑战
背景概述
在人工智能迈向通用智能(AGI)的探索进程中,多模态数据融合成为关键突破口。OMEGA Labs Bittensor Subnet数据集由OMEGA Labs于近期依托Bittensor去中心化网络构建,旨在汇集全球最大规模的多模态数据资源,以加速AGI的研发进程。该数据集核心聚焦于解决跨模态统一表征学习与任意模态间转换的复杂问题,通过集成超过百万小时的视频素材及数千万条短视频片段,覆盖广泛场景与行为短语,为训练具备深层理解与生成能力的模型提供了前所未有的数据基础,对推动智能体、沉浸式交互等前沿领域发展具有深远影响。
当前挑战
该数据集致力于应对多模态人工智能领域中的核心挑战,即如何实现视频、音频、文本等异构数据的高效对齐与语义统一,以支撑任意模态间的流畅转换与复杂任务执行。在构建过程中,面临多重实际困难:首先,确保数据质量与多样性需平衡,需通过嵌入相似度等机制筛选高相关性内容,避免噪声干扰;其次,去中心化采集模式虽能实现数据动态更新,但维持标注一致性、处理版权合规性以及管理超大规模分布式存储均构成显著技术瓶颈;此外,预计算ImageBind嵌入虽提升效率,但对计算资源与算法优化提出了极高要求。
常用场景
经典使用场景
在人工智能研究领域,多模态数据融合已成为推动通用智能发展的关键路径。OMEGA多模态数据集以其海量的视频、音频与文本资源,为研究者提供了训练跨模态统一表示模型的理想平台。经典使用场景包括利用其预计算的ImageBind嵌入,构建能够理解视频内容、生成对应描述或进行跨模态转换的模型,例如从文本生成视频或从音频推断视觉场景,这些应用显著提升了模型在复杂环境中的感知与生成能力。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作,主要集中在跨模态生成模型、统一表示学习框架与智能代理系统。例如,基于其预计算嵌入的研究探索了视频到文本的自动描述生成,以及文本到视频的合成技术;同时,利用其多样性奖励机制,学者们开发了增强数据选择策略的算法,进一步优化了多模态训练的效能与泛化能力。
数据集最近研究
最新研究方向
在通用人工智能(AGI)研究领域,多模态数据集正成为推动模型泛化能力的关键基石。OMEGA Labs Bittensor Subnet数据集以其海量视频、音频及文本的跨模态对齐嵌入,为统一表征学习提供了前所未有的实验平台。当前前沿研究聚焦于利用该数据集构建任意模态间的转换模型,如文本到视频生成、音频到图像合成等,旨在突破传统单模态系统的局限。热点事件包括结合去中心化网络实现数据动态更新与质量优化,这促进了数字智能体在复杂工作流中的自主导航能力发展。此类研究不仅加速了沉浸式游戏与视频理解技术的革新,更对构建具备人类认知水平的通用智能系统产生了深远影响,标志着多模态人工智能向更广阔应用场景的实质性迈进。
以上内容由遇见数据集搜集并总结生成


