RefineCode-code-corpus-meta
收藏Hugging Face2024-11-15 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/OpenCoder-LLM/RefineCode-code-corpus-meta
下载链接
链接失效反馈官方服务:
资源简介:
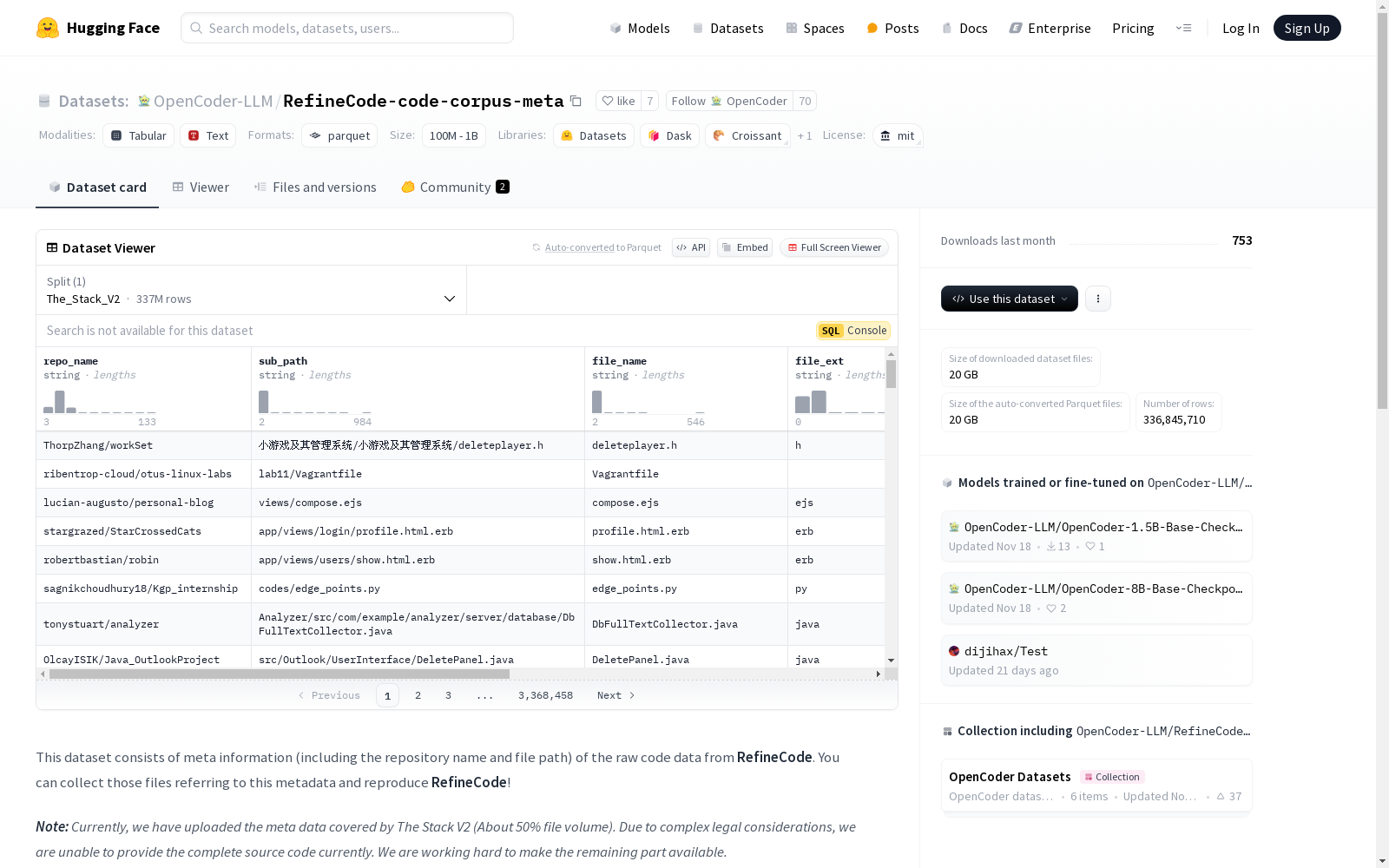
该数据集包含来自RefineCode的原始代码数据的元信息,包括仓库名称和文件路径。数据集展示了比The Stack V2训练子集更好的训练效果和效率。目前上传了The Stack V2覆盖的元数据(约50%的文件量),正在努力使剩余部分可用。RefineCode是一个高质量、可复制的代码预训练语料库,包含960亿个标记,涵盖607种编程语言和750亿个与代码相关的标记,结合了130多种特定语言的规则和自定义权重分配。
This dataset contains metadata of raw code data sourced from RefineCode, including repository names and file paths. It demonstrates better training performance and efficiency compared to the training subset of The Stack V2. Currently, metadata covered by The Stack V2 (approximately 50% of the total file volume) has been uploaded, and efforts are underway to make the remaining portion accessible. RefineCode is a high-quality, reproducible code pre-training corpus that includes 96 billion tokens spanning 607 programming languages, along with 75 billion code-related tokens, and incorporates over 130 language-specific rules and custom weight allocation schemes.
创建时间:
2024-11-15
原始信息汇总
RefineCode 代码语料库元数据集
数据集概述
该数据集包含来自 RefineCode 的原始代码数据的元信息,包括仓库名称和文件路径。用户可以参考这些元数据收集文件,以重现 RefineCode。
数据集特征
- repo_name: 仓库名称,数据类型为字符串。
- sub_path: 子路径,数据类型为字符串。
- file_name: 文件名,数据类型为字符串。
- file_ext: 文件扩展名,数据类型为字符串。
- file_size_in_byte: 文件大小(字节),数据类型为整数(int64)。
- line_count: 行数,数据类型为整数(int64)。
- lang: 语言,数据类型为字符串。
- program_lang: 编程语言,数据类型为字符串。
- doc_type: 文档类型,数据类型为字符串。
数据集分割
- The_Stack_V2: 包含 46,577,045,485 字节的数据,共有 336,845,710 个样本。
数据集大小
- 下载大小: 20,019,085,005 字节。
- 数据集大小: 46,577,045,485 字节。
配置
- default: 数据文件路径为
data/The_Stack_V2-*。
数据集特点
- 高质量: RefineCode 是一个高质量的代码预训练语料库。
- 可重现: 用户可以根据元数据重现 RefineCode。
- 规模: 包含 9600 亿个标记,涵盖 607 种编程语言,750 亿个与代码相关的标记。
- 规则: 包含超过 130 种特定语言的规则,并具有自定义权重分配。
数据集优势
- 训练效率: 与 The Stack V2 的训练子集相比,RefineCode 显示出更好的训练效率和效果。
- 可视化: 使用 PCA 对从 CodeBERT 提取的嵌入进行可视化,显示 RefineCode 在预训练数据集上的明显优势。
搜集汇总
数据集介绍
构建方式
RefineCode-code-corpus-meta数据集通过提取RefineCode项目的原始代码元信息构建而成,涵盖了代码库名称、文件路径、文件扩展名、文件大小、行数、语言类型等关键信息。该数据集基于The Stack V2的元数据,尽管目前仅覆盖了约50%的文件量,但其设计旨在为研究者提供高质量的代码预训练语料库。通过复杂的法律考量,团队正在努力使剩余部分的数据可用。
特点
RefineCode-code-corpus-meta数据集以其高质量和可复现性著称,包含9600亿个标记,覆盖607种编程语言,并从网络语料库中提取了750亿个与代码相关的标记。该数据集通过130多种语言特定规则和定制权重分配,显著提升了训练效果和效率。与The Stack V2的训练子集相比,RefineCode在嵌入可视化中展现出明显的优势,进一步验证了其作为预训练数据集的优越性。
使用方法
研究者可通过该数据集的元信息定位并收集RefineCode的原始代码文件,从而复现RefineCode项目。数据集以The Stack V2的元数据为基础,用户可通过指定路径下载相关文件。尽管目前仅提供部分数据,但其结构清晰,便于用户根据需求进行扩展和应用。通过结合CodeBERT等模型,用户可进一步探索代码嵌入的可视化与优化,提升代码预训练模型的效果。
背景与挑战
背景概述
RefineCode-code-corpus-meta数据集由OpenCoder团队创建,旨在为代码预训练提供高质量、可复现的语料库。该数据集涵盖了607种编程语言,包含9600亿个代码相关令牌,并引入了130多种语言特定的规则与定制权重分配。相较于The Stack V2的训练子集,RefineCode在训练效率和效果上表现出显著优势。通过PCA可视化技术,研究人员能够直观地对比CodeBERT在The Stack V2和RefineCode上的嵌入表现,进一步验证了其优越性。该数据集的发布为代码理解和生成任务提供了重要的资源支持,推动了编程语言处理领域的研究进展。
当前挑战
RefineCode-code-corpus-meta数据集在构建过程中面临多重挑战。首先,数据集的规模庞大,涉及9600亿个令牌和607种编程语言,如何确保数据的多样性和质量成为核心问题。其次,由于法律和版权限制,部分源代码无法公开,导致数据集的不完整性,这对研究人员的复现工作提出了额外要求。此外,数据预处理和语言特定规则的定制权重分配需要大量的人工干预和计算资源,进一步增加了构建难度。在应用层面,如何高效利用该数据集进行模型训练,并验证其在代码理解和生成任务中的实际效果,也是当前研究的重要挑战。
常用场景
经典使用场景
RefineCode-code-corpus-meta数据集在代码预训练领域具有重要应用,特别是在构建和优化大规模代码语料库时。通过提供包含9600亿个标记的元数据信息,研究人员能够高效地筛选和整合来自607种编程语言的代码文件,从而为代码生成、代码补全和代码理解等任务提供高质量的预训练数据。
衍生相关工作
基于RefineCode-code-corpus-meta数据集,多项经典研究工作得以展开。例如,研究人员利用该数据集优化了CodeBERT等预训练模型,提升了其在代码理解和生成任务中的表现。此外,该数据集还推动了多语言代码生成和跨语言代码迁移等领域的研究,为代码智能技术的进一步发展奠定了基础。
数据集最近研究
最新研究方向
在代码预训练领域,RefineCode-code-corpus-meta数据集以其高质量和可复现性成为研究热点。该数据集涵盖了607种编程语言,包含9600亿个令牌,并通过130多种语言特定规则进行定制化权重分配,显著提升了训练效果和效率。与The Stack V2相比,RefineCode在嵌入提取和分布可视化方面展现出明显优势,特别是在使用PCA技术对CodeBERT嵌入进行可视化时,其分布更加集中和清晰。这一进展不仅推动了代码预训练模型的发展,还为多语言代码理解和生成任务提供了强有力的支持。随着开源社区的不断壮大,RefineCode的广泛应用将进一步促进代码智能化的研究与实践。
以上内容由遇见数据集搜集并总结生成


