Chinese Natural Speech Complex Emotion Dataset
收藏DataCite Commons2025-04-27 更新2025-04-16 收录
下载链接:
https://www.scidb.cn/detail?dataSetId=394f27fbc9014cd486951b770fdefa10
下载链接
链接失效反馈官方服务:
资源简介:
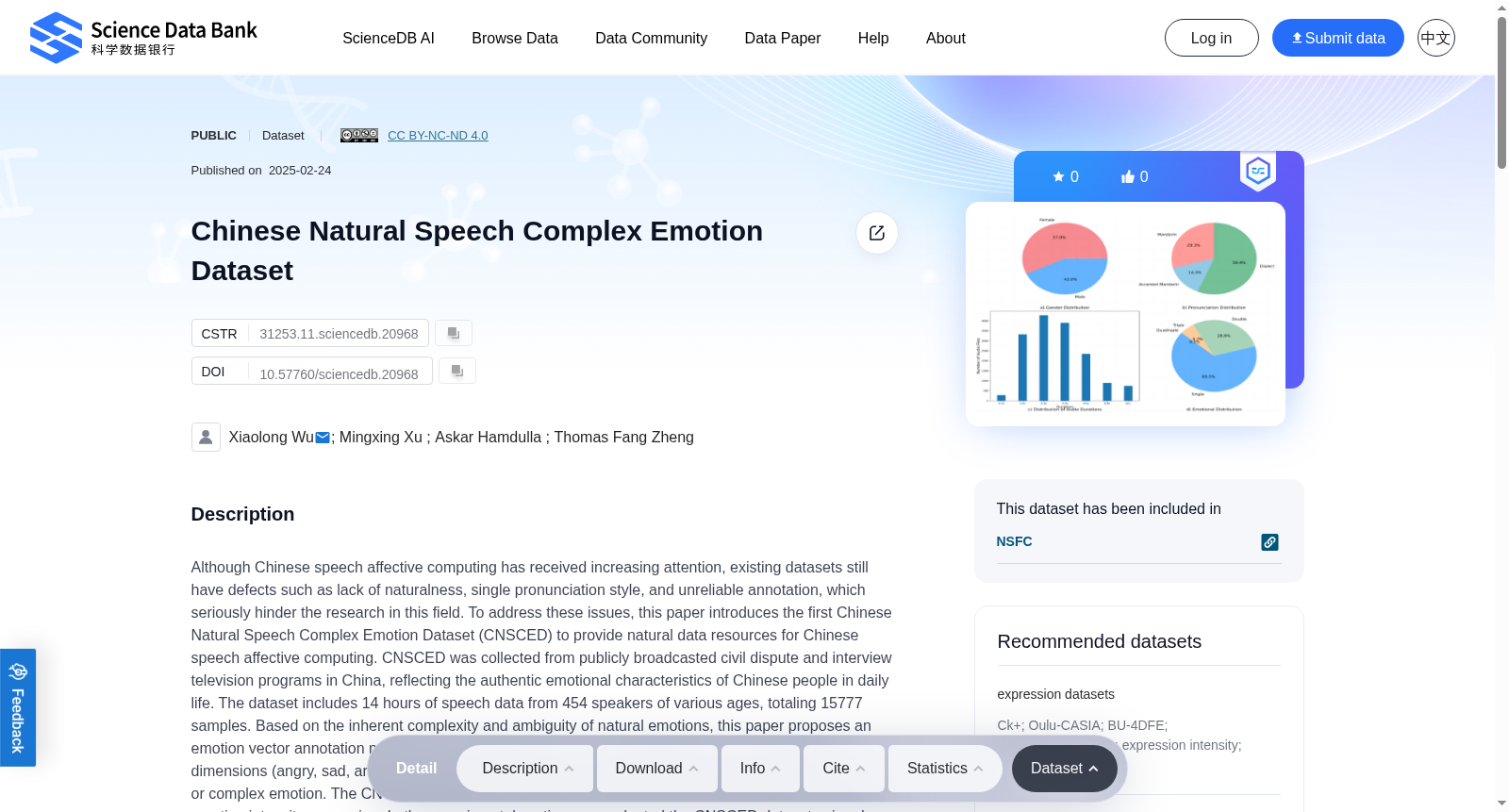
Although Chinese speech affective computing has received increasing attention, existing datasets still have defects such as lack of naturalness, single pronunciation style, and unreliable annotation, which seriously hinder the research in this field. To address these issues, this paper introduces the first Chinese Natural Speech Complex Emotion Dataset (CNSCED) to provide natural data resources for Chinese speech affective computing. CNSCED was collected from publicly broadcasted civil dispute and interview television programs in China, reflecting the authentic emotional characteristics of Chinese people in daily life. The dataset includes 14 hours of speech data from 454 speakers of various ages, totaling 15777 samples. Based on the inherent complexity and ambiguity of natural emotions, this paper proposes an emotion vector annotation method. This method utilizes a vector composed of six meta-emotional dimensions (angry, sad, aroused, happy, surprise, and fear) of different intensities to describe any single or complex emotion. The CNSCED released two subtasks: complex emotion classification and complex emotion intensity regression. In the experimental section, we evaluated the CNSCED dataset using deep neural network models and provided a baseline result. To the best of our knowledge, CNSCED is the first public Chinese natural speech complex emotion dataset, which can be used for scientific research free of charge.
尽管汉语语音情感计算领域受到的关注度与日俱增,但现有数据集仍存在自然度不足、发音风格单一、标注不可靠等缺陷,严重制约了该领域的研究进展。为解决上述问题,本文构建了首个汉语自然语音复杂情感数据集(Chinese Natural Speech Complex Emotion Dataset,CNSCED),旨在为汉语语音情感计算领域提供自然化的数据资源。该数据集采集自中国境内公开播出的民生纠纷与访谈类电视节目,能够真实反映中国人日常生活中的情感特质。该数据集收录了454名不同年龄段发声者的语音数据,总时长14小时,样本总量达15777条。鉴于自然情感本身具有复杂性与模糊性,本文提出了一种情感向量标注方法。该方法采用由愤怒、悲伤、亢奋、愉悦、惊讶、恐惧六种元情感维度及其不同强度构成的向量,来表征单一情感或复杂情感。该数据集设置了两项子任务:复杂情感分类与复杂情感强度回归。在实验环节,本文采用深度神经网络模型对CNSCED数据集进行了性能评估,并给出了基准实验结果。据我们所知,CNSCED是首个公开可用的汉语自然语音复杂情感数据集,可免费用于科学研究工作。
提供机构:
Science Data Bank
创建时间:
2025-02-24
搜集汇总
数据集介绍
背景与挑战
背景概述
Chinese Natural Speech Complex Emotion Dataset (CNSCED) 是首个公开的中文自然语音复杂情感数据集,包含14小时来自454名不同年龄段说话者的语音数据,采用六种元情感维度的向量标注方法,为中文语音情感计算研究提供了自然数据资源。
以上内容由遇见数据集搜集并总结生成


