nafld-snrna-starsolo-qc-summary
收藏Hugging Face2026-05-07 更新2026-05-08 收录
下载链接:
https://huggingface.co/datasets/depinwang/nafld-snrna-starsolo-qc-summary
下载链接
链接失效反馈官方服务:
资源简介:
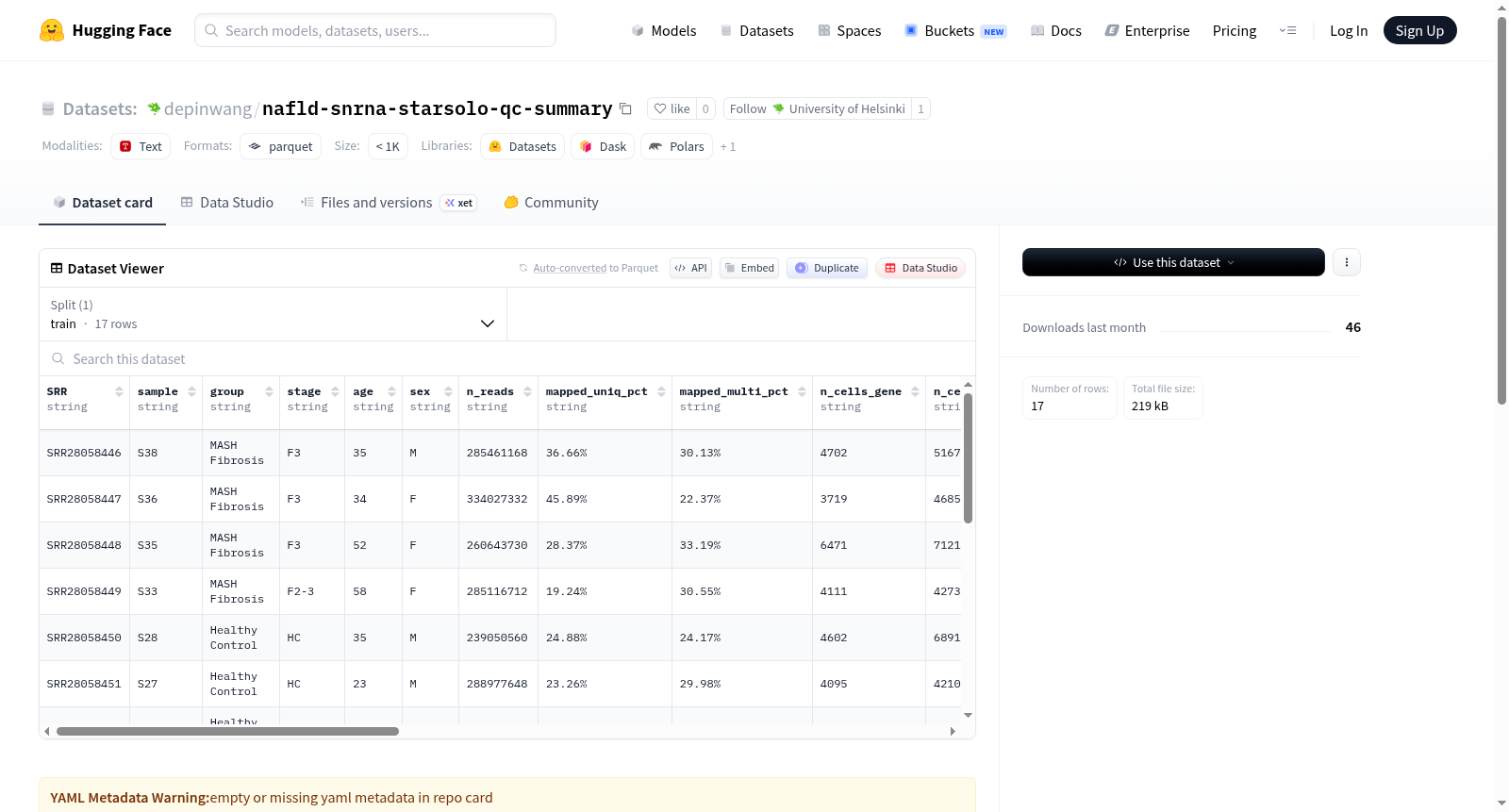
该数据集包含来自GSE256398 NAFLD研究的单核RNA测序(snRNA-seq)样本的STARsolo运行质量控制(QC)摘要。数据以parquet格式存储,按SRA运行编号(SRR)分片。数据集提供了每个样本的关键QC指标,包括输入读数、唯一映射读数百分比、使用GeneFull特征估计的细胞数量、每个细胞的UMI中位数、有效条形码百分比等。样本按疾病组分类(健康对照HC / MASLD F0 / MASH纤维化 / MASH肝硬化)。该数据集适用于研究NAFLD不同疾病阶段的单细胞转录组数据质量评估和分析。
创建时间:
2026-05-06
原始信息汇总
数据集概述:nafld-snrna-starsolo — 每样本质量控制摘要
基本信息
- 数据集名称:nafld-snrna-starsolo-qc-summary
- 数据集地址:https://huggingface.co/datasets/depinwang/nafld-snrna-starsolo-qc-summary
- 数据来源:GSE256398 NAFLD 轴,源自 STARsolo 运行结果
- 最后更新日期:2026-05-07T15:46:04.410424+00:00
- 数据格式:文件分片存储在
data/<SRR>.parquet下
加载方式
可通过 datasets.load_dataset(depinwang/nafld-snrna-starsolo-qc-summary) 直接加载。
字段说明
| 列名 | 含义 |
|---|---|
| SRR | SRA 运行编号(Run Accession) |
| group | 疾病分组(HC / MASLD F0 / MASH Fibrosis / MASH Cirrhosis) |
| n_reads | 输入读段数(来自 Log.final.out) |
| mapped_uniq_pct | 唯一比对读段百分比 |
| n_cells_genefull | 使用 GeneFull(含内含子)特征估计的细胞数 |
| median_umi_genefull | 使用 GeneFull 特征的中位 UMI 数 |
| valid_bc_pct | 有效(匹配白名单)条形码的读段百分比 |
| artifact_status | 人工状态(partial / final) |
| canary | 布尔值,指示该行是否来自 canary 运行 |
数据特点
- 该数据集为流式处理生成,提供来自 STARsolo 运行的每样本质量控制表格
- 覆盖 NAFLD 疾病谱系,包括健康对照(HC)、MASLD F0、MASH 纤维化、MASH 肝硬化四个疾病分组
- 包含关键质量控制指标,如唯一比对率、有效条形码比例、估计细胞数及中位 UMI 数
搜集汇总
数据集介绍
构建方式
本数据集源自GSE256398项目中NAFLD相关样本的STARsolo流程运行结果,以每个SRA测序运行(SRR)为单位生成质量控制表。数据以Parquet格式分片存储于`data/<SRR>.parquet`路径下,通过HuggingFace的`datasets.load_dataset('depinwang/nafld-snrna-starsolo-qc-summary')`接口直接加载,便于大规模单细胞转录组数据的流式处理。数据集结构清晰,包含SRR标识、疾病分组(HC、MASLD F0、MASH Fibrosis、MASH Cirrhosis)、输入读数数量、唯一比对百分比、基于GeneFull特征估计的细胞数及中位UMI数、有效条形码比例、加工状态(partial/final)和canary标记等字段,全面覆盖STARsolo输出的关键质控指标。
特点
该数据集聚焦于非酒精性脂肪性肝病(NAFLD)谱系的单核RNA测序质控,具有鲜明的疾病分层特色。核心特点在于整合了STARsolo流程的流式质控信息,提供从原始读数到细胞鉴定全链条的可追溯指标,尤其通过GeneFull特征(含内含子区域)估算细胞数和中位UMI,提升了细胞检测的灵敏度。数据集引入'canary'标记用于识别试运行批次,同时'artifact_status'字段区分部分与终态数据,便于用户筛选稳定结果。整体设计兼顾了大规模数据的高效存储与深度质控分析需求。
使用方法
用户可通过`datasets.load_dataset`函数一键加载整个数据集,无需手动处理分片文件。每个样本的质控摘要以字典形式存在,字段包括SRR(用于匹配原始测序数据)、group(疾病分组)、n_reads(输入读数)、mapped_uniq_pct(唯一比对百分比)、n_cells_genefull(基于GeneFull的估计细胞数)、median_umi_genefull(中位UMI)、valid_bc_pct(有效条形码比例)、artifact_status(数据状态)和canary(试运行标记)。建议先利用`artifact_status`筛选'final'状态行以保证数据质量,再根据group字段进行疾病亚组间的质控指标比较,或结合canary标记排除试运行批次的影响。
背景与挑战
背景概述
非酒精性脂肪性肝病(NAFLD)作为全球最常见的慢性肝病之一,其病理机制探索高度依赖单细胞转录组技术。该数据集由depinwang团队于2026年创建,基于GSE256398研究中的STARsolo流程对NAFLD相关样本进行单核RNA测序分析,重点解决不同疾病阶段(健康对照、MASLD F0、MASH纤维化、MASH肝硬化)的细胞异质性解析问题。通过汇总每样本的质控指标,该数据集为NAFLD转录组研究提供了标准化、可复现的质量评估基准,显著推动了肝病单细胞组学数据的高效整合与跨研究比较。
当前挑战
该数据集所应对的领域挑战在于:单核RNA测序数据中存在低质量细胞、批次效应及双细胞污染等干扰,直接影响下游疾病亚型识别与生物标志物挖掘的可靠性。构建过程中面临的数据挑战包括:来自不同疾病分组的样本间测序深度差异大,需通过mapped_uniq_pct与median_umi_genefull等参数平衡数据有效性;valid_bc_pct指标受白名单匹配效率制约,部分样本出现‘partial’人工制品状态,需人工判断是否纳入最终分析;此外,大量SRA运行文件的并行质控需设计流式处理架构,避免内存溢出并保证数据更新时效性。
常用场景
经典使用场景
在非酒精性脂肪性肝病(NAFLD)的转录组学研究中,单细胞核RNA测序(snRNA-seq)技术被广泛用于解析肝细胞与非实质细胞在疾病进展中的异质性。该数据集通过对GSE256398队列中NAFLD不同病理阶段(健康对照、代谢相关脂肪性肝病F0期、代谢相关脂肪性肝炎纤维化期及肝硬化期)的样本进行STARsolo流程质量控制,提供了每个样本的QC汇总表。研究者可基于此数据集快速筛选出高质量的单细胞核转录组样本,用于后续的细胞亚群鉴定、差异表达分析和疾病轨迹推断,从而确保下游生物信息学分析的可靠性。
衍生相关工作
该数据集衍生了一系列聚焦于NAFLD单细胞图谱质量控制方法学优化的经典工作。例如,研究者基于QC指标间的关联分析,提出了结合`mapped_uniq_pct`与`valid_bc_pct`的双参数过滤策略,显著提升了肝星状细胞和巨噬细胞亚群的识别纯度。此外,有工作利用该数据集的`group`列对比不同疾病阶段的中位UMI分布,开发了适应病理异质性的批次校正算法。这些衍进成果不仅提升了单细胞核数据分析在复杂肝脏疾病中的鲁棒性,也为其他慢性炎症性疾病的snRNA-seq质控体系提供了可推广的范式。
数据集最近研究
最新研究方向
在非酒精性脂肪性肝病(NAFLD)相关单细胞核RNA测序研究中,该数据集为探究不同疾病阶段(健康对照、代谢相关脂肪性肝病、脂肪性肝炎纤维化及肝硬化)的细胞异质性提供了关键质量控制指标。基于STARsolo流程生成的样本级QC摘要,揭示了从原始读段到有效细胞检测的全流程质控参数,尤其通过GeneFull特征评估内含子包含型转录本的细胞捕获效率,为解析NAFLD进展中肝细胞与非实质细胞的分子动态变化奠定了数据基础。当前该领域前沿方向聚焦于整合此类高质量质控数据与临床表型,以解析肝纤维化至肝硬化转变中的罕见细胞亚群转录特征,推动精准治疗靶点的发现。
以上内容由遇见数据集搜集并总结生成


