Vikhrmodels/GrandMaster-PRO-MAX
收藏Hugging Face2024-10-25 更新2024-07-22 收录
下载链接:
https://hf-mirror.com/datasets/Vikhrmodels/GrandMaster-PRO-MAX
下载链接
链接失效反馈官方服务:
资源简介:
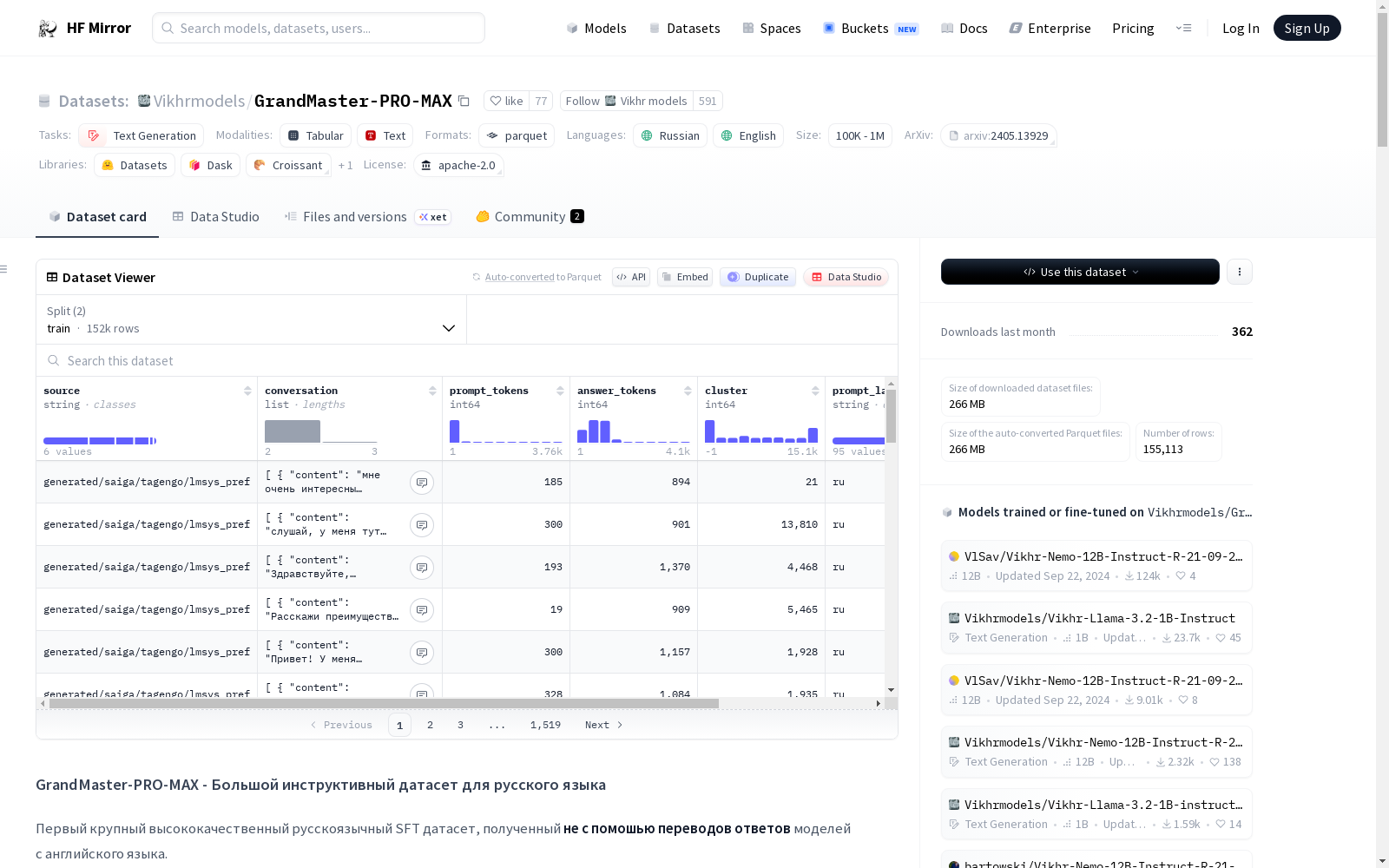
GrandMaster-PRO-MAX是一个高质量的俄语指令跟随数据集,主要用于训练模型以遵循不同语言的指令并生成相应的回答。数据集中的回答完全由GPT-4-Turbo-1106生成,基于用户提供的原始指令。数据集包含约142,000个独特的指令-回答对,生成成本约为4,000美元。数据集的特点包括内置的Chain-of-Thought (CoT)能力,通过使用复杂的提示来生成大多数回答。数据集的来源包括多个公开数据集和合成生成的提示,涵盖了广泛的数学、编程、逻辑、概念解释等主题。数据集还包括聚类信息、提示和回答的令牌数量统计。
GrandMaster-PRO-MAX is a high-quality Russian instruction-following dataset designed to train models to follow instructions in various languages and generate corresponding responses. The responses in the dataset are entirely generated by GPT-4-Turbo-1106 based on user-provided original instructions. The dataset contains approximately 142,000 unique instruction-response pairs, with a generation cost of around $4,000. A distinctive feature of the dataset is its built-in Chain-of-Thought (CoT) capability, achieved through the use of complex prompts for generating most responses. The datasets sources include multiple public datasets and synthetically generated prompts, covering a wide range of topics such as mathematics, programming, logic, concept explanations, and more. The dataset also includes clustering information and token count statistics for prompts and responses.
提供机构:
Vikhrmodels
原始信息汇总
数据集概述
数据集信息
-
特征:
source: 数据来源,类型为字符串。conversation: 对话内容,包含以下子特征:content: 对话内容,类型为字符串。role: 角色,类型为字符串。
prompt_tokens: 提示词数量,类型为整数。answer_tokens: 回答词数量,类型为整数。cluster: 聚类标识,类型为整数。
-
数据分割:
train: 训练集,包含140,000个样本,大小为513,934,038字节。test: 测试集,包含1,812个样本,大小为6,588,699字节。
-
数据大小:
- 下载大小: 240,557,834字节。
- 数据集总大小: 520,522,737字节。
-
配置:
default: 默认配置,包含训练集和测试集的数据文件路径。
-
许可证: Apache 2.0
-
语言: 俄语
-
规模: 100K < n < 1M
数据集特点
- 数据集包含约142,000个独特的指令-回答对。
- 数据集中的回答完全由GPT-4-Turbo-1106生成,基于原始用户指令。
- 数据集中的回答使用Markdown格式,结构化且符合用户要求。
- 数据集包含9,438个独特的聚类。
数据来源
- 数据集的原始指令来自以下几个来源:
- Saiga和Tagengo数据集的一部分,约16,000个。
- lmsys/lmsys-chat-1m数据集的俄语部分,约30,000个。
- lmsys/lmsys-arena-human-preference-55k数据集的俄语翻译部分,约21,000个。
- 合成生成的指令,约50,000个。
- BAAI/Infinity-Instruct数据集的多语言部分,约30,000个。
合成生成的指令
- 合成生成的指令涵盖以下主题:
- 数学 - 基础学校/大学数学知识,数学题。
- 编程 - 基础学校/大学计算机科学知识,算法题。
- 逻辑和逻辑问题。
- 解释概念和术语。
- 概念和想法的开发。
- 敏感话题。
- 一般对话主题。
- 与俄罗斯和俄语相关的话题。
- 角色扮演。
- 操作指南和问题。
- 数学(第二部分)。
- 编程 - 常见工作任务。
- 文本处理任务。
- 对象、概念等的比较。
- 遵循提示中指定的回答格式。
数据集统计
-
提示词的分布:
- 数量: 141,812
- 平均值: 132.11
- 标准差: 196.12
- 最小值: 1
- 25%分位数: 31
- 中位数: 81
- 75%分位数: 177
- 最大值: 32,674
-
回答词的分布:
- 数量: 141,812
- 平均值: 761.63
- 标准差: 383.52
- 最小值: 1
- 25%分位数: 494
- 中位数: 826
- 75%分位数: 1,038
- 最大值: 4,096
搜集汇总
数据集介绍
背景与挑战
背景概述
GrandMaster-PRO-MAX是一个大型俄语指令调优数据集,包含约155,000个独特的指令-答案对,所有回答均由GPT-4-Turbo-1106生成,特别注重结构化回答和链式思考能力。数据集以俄语和英语为主,涵盖数学、编程、逻辑等多种主题,旨在提升模型在俄语环境下的指令遵循和回答生成能力。
以上内容由遇见数据集搜集并总结生成


