OmniThoughtV 大规模多模态推理数据集 过滤版
收藏魔搭社区2026-05-23 更新2025-12-13 收录
下载链接:
https://modelscope.cn/datasets/platformofai/OmniThoughtV_Filter_0.5M
下载链接
链接失效反馈官方服务:
资源简介:
## 数据集介绍
OmniThoughtV 是基于 [Finevision](https://huggingface.co/datasets/HuggingFaceM4/FineVision) 数据集和阿里云人工智能平台(PAI)的蒸馏工具包 [EasyDistill](https://github.com/modelscope/easydistill) 蒸馏得到的大规模多模态长思考数据集。该数据集构建了一套透明、可复现的数据蒸馏机制,实现了多模态推理思维链的高效构建。使用该数据集微调小模型可以成功赋予其更强的推理能力,并提升其在下游任务的表现。
## 数据集使用
```jsonc
from datasets import load_dataset
data_path='...YOUR_PATH_To.../OmmiThoughtV_Raw_1.8M/'
OmmiThoughtV=load_dataset(data_path, streaming=True)
```
## 数据集样例
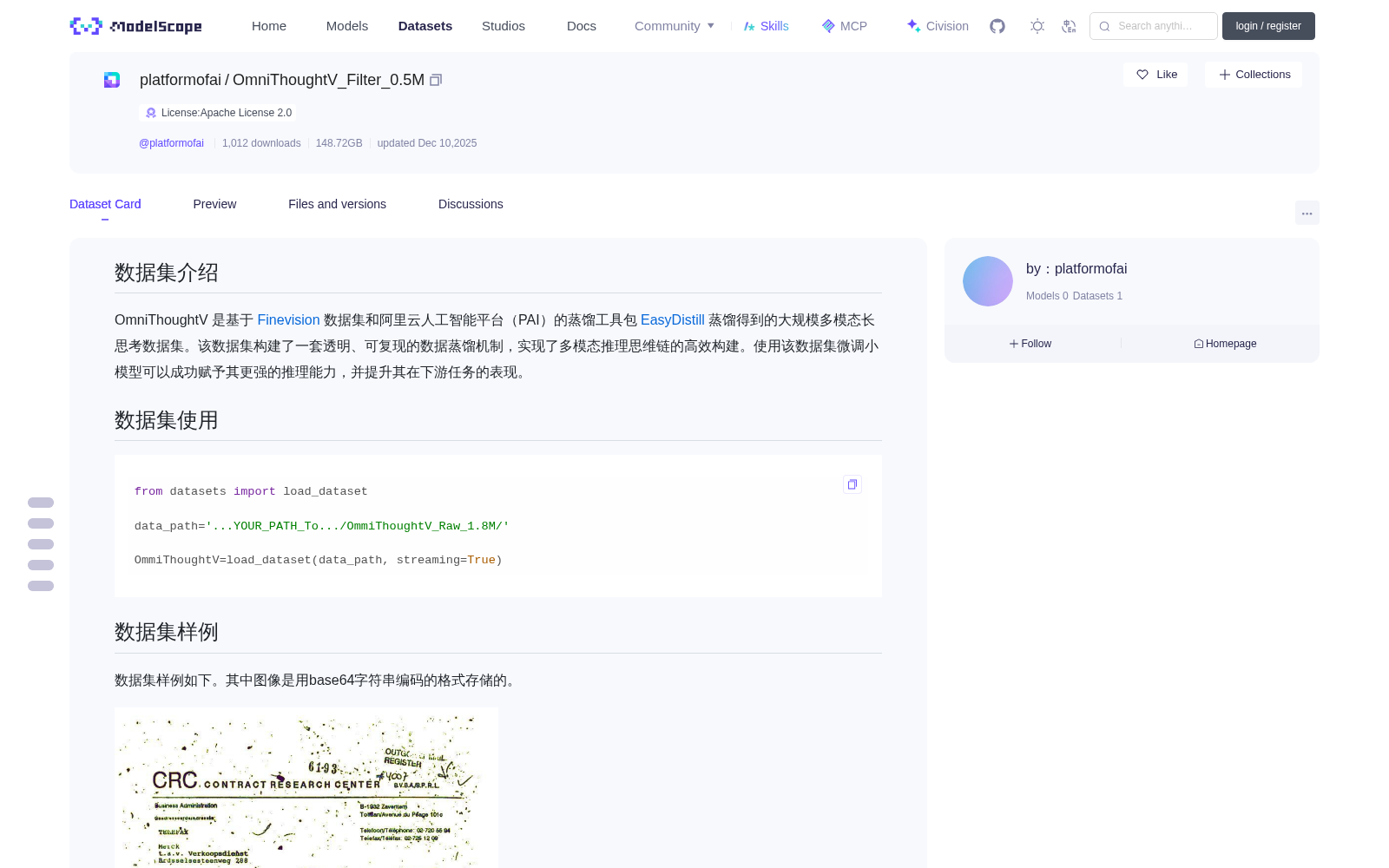
数据集样例如下。其中图像是用base64字符串编码的格式存储的。
<img src="readme/sample.png" alt="描述文字" width="50%">
```jsonc
[
{
"role": "system",
"content": "You are a helpful assistant to think step by step. Provide your reasoning steps within <thinking></thinking> tags and give your final answer within <answer></answer> tags."
},
{
"role": "user",
"content":
“
### Question
What is the currency used in the invoice?
### Output Format (Strictly Enforced)
<thinking>
Clearly explain your reasoning step by step. Describe how you arrived at the conclusion.
The reasoning process MUST BE enclosed within <thinking> </thinking> tags.
</thinking>
<answer>
Your final answer to the user's question.
</answer>
<image>
”
},
{
"role": "assistant",
"content":
"<thinking>
To determine the currency used in the invoice, I will analyze the document for any indications of currency symbols or references.
1. The invoice is from the CRC Contract Research Center, and it includes prices listed next to each item.
2. Looking at the prices, such as \"5.574,-\", \"10.580,-\", \"6.968,-\", \"689,-\", and \"3.242,-\", these numbers are followed by a comma and a dash, which is typical formatting in some European countries for decimal points and currency notation.
3. The total amount at the bottom is \"24.153,-\". This format is consistent with Belgian francs (BEF), which was the currency used in Belgium before the euro.
4. The document is dated November 24, 1993, and Belgium used the Belgian franc until 2002 when it adopted the euro.
5. Additionally, the company's address is in Belgium (B-1932 Zaventem), and the phone number format is also consistent with Belgium.
6. The use of \"BP\" in the price column likely stands for \"Belgian Francs\" (Belgische Frank), which was the currency code for the Belgian franc.
Given all these observations, the currency used in the invoice is the Belgian franc (BEF).
</thinking>
<answer>
Belgian franc (BEF)
</answer>
“
}
]
```
## 评测
我们对 Qwen3-VL 2B、4B、8B 在50万条的 OmniThoughtV 数据集过滤版上进行了微调。并使用 LMMs-Eval 框架进行评测。由于不同 Prompt 评测模板会对测评结果产生影响,我们在评测过程中统一固定了一套推理 Prompt (详见 [评测说明](eval/eval.md) )。实验结果如下表所示。 我们成功验证了数据集的有效性,实验数据显示,无论是在通用视觉理解能力 benchmark(如 AI2D、MMStar),还是在对推理能力更敏感的 benchmark(如 MMMU_Pro_standard、MMMU_Pro_vision、 MathVerse、 MathVision)上,所有经过微调的模型均实现了性能提升,在强调推理能力的 benchmark 上提升尤为显著。这充分证明了高质量数据的蒸馏、筛选与规模扩展对模型推理能力提升的有效性。
<img src="readme/ovbch.png" alt="评测结果" width="100%">
## 参考:EasyDistill系列相关论文
- Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Reasoning with OmniThought: A Large CoT Dataset with Verbosity and Cognitive Difficulty Annotations. arXiv preprint
- Yuanjie Lyu, Chengyu Wang, Jun Huang, Tong Xu. From Correction to Mastery: Reinforced Distillation of Large Language Model Agents. arXiv preprint
- Chengyu Wang, Junbing Yan, Wenrui Cai, Yuanhao Yue, Jun Huang. EasyDistill: A Comprehensive Toolkit for Effective Knowledge Distillation of Large Language Models. EMNLP 2025
- Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Thinking with DistilQwen: A Tale of Four Distilled Reasoning and Reward Model Series. EMNLP 2025
- Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Enhancing Reasoning Abilities of Small LLMs with Cognitive Alignment. EMNLP 2025
- Chengyu Wang, Junbing Yan, Yuanhao Yue, Jun Huang. DistilQwen2.5: Industrial Practices of Training Distilled Open Lightweight Language Models. ACL 2025
- Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Building a Family of Data Augmentation Models for Low-cost LLM Fine-tuning on the Cloud. COLING 2025
- Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Distilling Instruction-following Abilities of Large Language Models with Task-aware Curriculum Planning. EMNLP 2024
# 数据集介绍
OmniThoughtV 是基于 Finevision(Finevision)数据集和阿里云人工智能平台(PAI)的蒸馏工具包 EasyDistill 蒸馏得到的大规模多模态长思考数据集。该数据集构建了一套透明、可复现的数据蒸馏机制,实现了多模态推理思维链的高效构建。利用该数据集对小型模型进行微调,可有效赋予模型更强的推理能力,并提升其在下游任务中的性能表现。
## 数据集使用
jsonc
from datasets import load_dataset
data_path='...YOUR_PATH_To.../OmmiThoughtV_Raw_1.8M/'
OmmiThoughtV=load_dataset(data_path, streaming=True)
## 数据集样例
数据集样例如下。其中图像以base64字符串编码格式存储。
<img src="readme/sample.png" alt="描述文字" width="50%">
jsonc
[
{
"role": "system",
"content": "您是一位擅长逐步思考的助手。请在<thinking></thinking>标签内给出推理步骤,并在<answer></answer>标签内给出最终答案。"
},
{
"role": "user",
"content":
""
### 问题
该发票使用的货币是什么?
### 输出格式(严格遵循)
<thinking>
请清晰地逐步解释您的推理过程,描述您得出结论的方式。推理过程必须封装在<thinking> </thinking>标签内。
</thinking>
<answer>
您对用户问题的最终答案。
</answer>
<image>
""
},
{
"role": "assistant",
"content":
"<thinking>
为确定该发票使用的货币,我将分析文档中所有涉及货币符号或相关表述的线索。
1. 该发票来自CRC合同研究中心,其中每个商品旁均标注了价格。
2. 观察价格项,如"5.574,-"、"10.580,-"、"6.968,-"、"689,-"与"3.242,-",这些数字后紧跟逗号与短横线,这是部分欧洲国家用于表示小数点与货币格式的典型写法。
3. 底部的总金额为"24.153,-",该格式与比利时法郎(BEF)的格式一致,比利时法郎是欧元启用前比利时使用的货币。
4. 文档日期为1993年11月24日,比利时在2002年启用欧元前一直使用比利时法郎。
5. 此外,该公司的地址位于比利时(B-1932 扎芬特姆),电话号码格式也与比利时一致。
6. 价格列中的"BP"大概率代表"比利时法郎(Belgische Frank)",即比利时法郎的货币代码。
综合以上所有观察结果,该发票使用的货币为比利时法郎(BEF)。
</thinking>
<answer>
比利时法郎(BEF)
</answer>"
}
]
## 评测
我们对 Qwen3-VL 2B、4B、8B 在50万条的 OmniThoughtV 数据集过滤版上进行了微调,并使用 LMMs-Eval 框架进行评测。由于不同提示词(Prompt)评测模板会对测评结果产生影响,我们在评测过程中统一固定了一套推理提示词(详见 [评测说明](eval/eval.md))。实验结果如下表所示。
我们成功验证了该数据集的有效性,实验数据显示,无论是在通用视觉理解能力基准测试集(benchmark,如 AI2D、MMStar),还是在对推理能力更敏感的基准测试集(benchmark,如 MMMU_Pro_standard、MMMU_Pro_vision、MathVerse、MathVision)上,所有经过微调的模型均实现了性能提升,在强调推理能力的基准测试集上提升尤为显著。这充分证明了对高质量数据进行蒸馏、筛选与规模扩展,可有效提升模型的推理能力。
<img src="readme/ovbch.png" alt="评测结果" width="100%">
## 参考:EasyDistill系列相关论文
- 蔡文瑞、王承宇、严俊冰、黄俊、方祥忠. 《OmniThought推理:具备详细程度与认知难度标注的大型思维链(Chain of Thought,CoT)数据集》. arXiv预印本
- 吕元杰、王承宇、黄俊、徐通. 《从修正到掌握:大型语言模型智能体(AI Agent)的强化蒸馏》. arXiv预印本
- 王承宇、严俊冰、蔡文瑞、岳元浩、黄俊. 《EasyDistill:面向大型语言模型高效知识蒸馏的综合工具包》. EMNLP 2025
- 蔡文瑞、王承宇、严俊冰、黄俊、方祥忠. 《DistilQwen推理:四款蒸馏推理与奖励模型系列的实践》. EMNLP 2025
- 蔡文瑞、王承宇、严俊冰、黄俊、方祥忠. 《通过认知对齐提升小型大型语言模型的推理能力》. EMNLP 2025
- 王承宇、严俊冰、岳元浩、黄俊. 《DistilQwen2.5:开源轻量级语言模型蒸馏的工业实践》. ACL 2025
- 岳元浩、王承宇、黄俊、王鹏. 《构建面向云端低成本大语言模型微调的数据增强模型家族》. COLING 2025
- 岳元浩、王承宇、黄俊、王鹏. 《基于任务感知课程规划的大型语言模型指令遵循能力蒸馏》. EMNLP 2024
提供机构:
maas
创建时间:
2025-12-05
搜集汇总
数据集介绍
背景与挑战
背景概述
OmniThoughtV过滤版是一个基于Finevision数据集通过蒸馏工具构建的大规模多模态推理数据集,包含50万条数据,旨在通过微调提升小模型的推理能力和下游任务表现。评测结果显示,该数据集在多个视觉理解和推理基准测试中均有效提升了模型性能。
以上内容由遇见数据集搜集并总结生成


