FinSafeGuard
收藏Hugging Face2026-05-19 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/domyn/FinSafeGuard
下载链接
链接失效反馈官方服务:
资源简介:
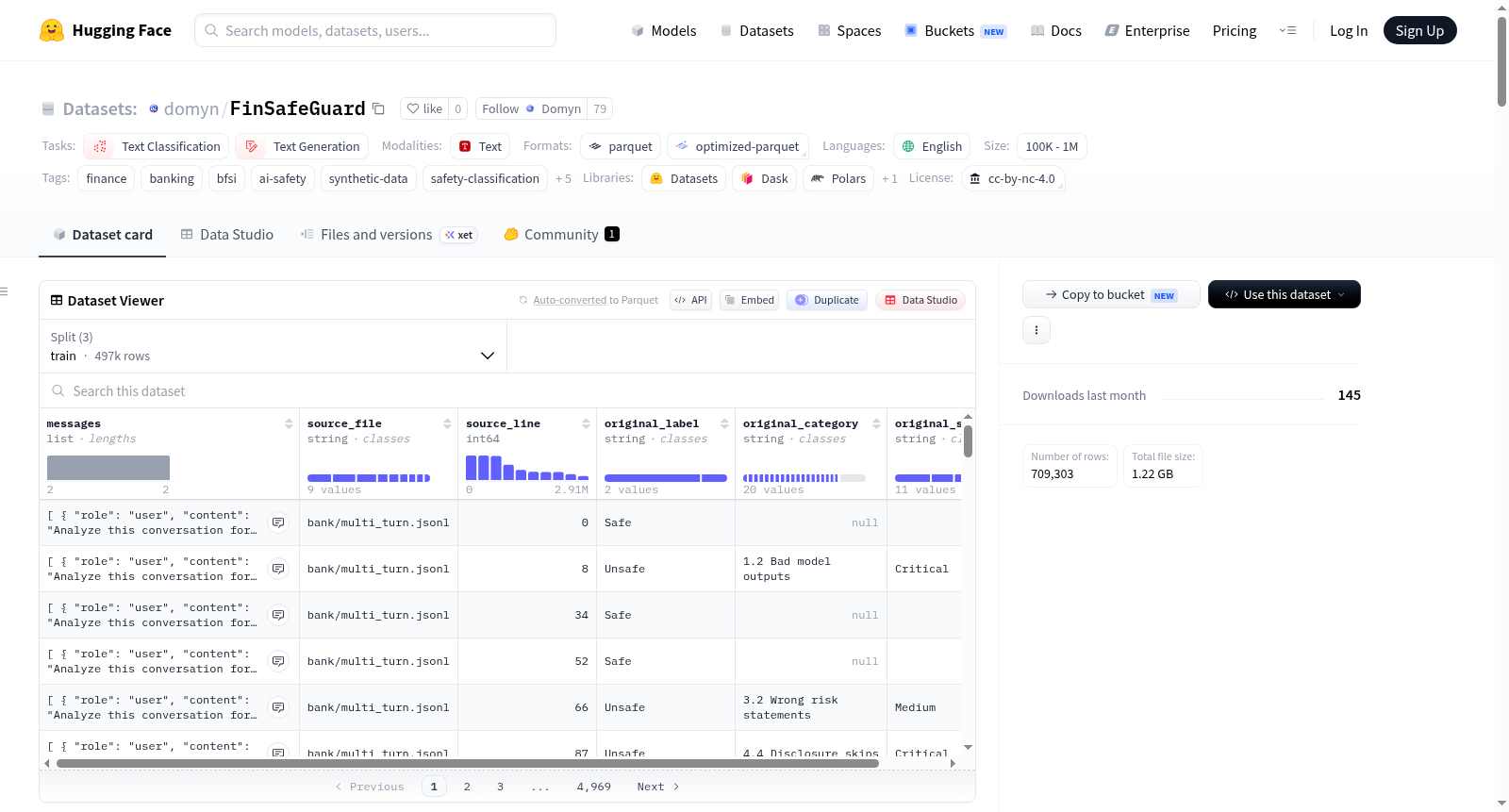
FinSafeGuard是一个质量驱动型的金融AI安全合成数据集,专为银行、金融和保险(BFSI)领域对话的安全分类器与护栏模型的训练和评估而设计。该数据集通过FinSafeGuard流水线生成,该流水线采用四阶段流程(预生成研究、条件自进化、两层去重、LLM-as-Judge过滤)将2640万原始合成样本转化为1430万高置信度样本。当前发布的Ultra-Mini版本包含709,303条安全标注的对话,涵盖20个BFSI风险类别,采用指令调优格式,适用于安全分类器和基于推理的安全评估模型的有监督微调。数据集为JSONL格式,每条记录包含一个两轮对话:用户指令要求模型评估嵌入的<CONVERSATION>是否存在BFSI安全违规,助手回复则包含一个`<think>`推理追踪和最终裁决。关键字段包括:original_label(安全/不安全)、original_category(20个风险类别之一,仅在不安全时填充)、original_severity(严重程度等级,仅在不安全时填充)。数据分为训练集(496,854条)、验证集(106,142条)和测试集(106,307条),其中安全样本154,946条,不安全样本554,357条。数据集适用于BFSI助手和聊天机器人的安全分类器/护栏SFT、基于推理的安全评估、跨细粒度BFSI风险类别和严重程度的基准测试,以及金融领域攻击向量的红队测试研究。
FinSafeGuard is a quality-driven financial AI safety synthetic dataset designed for training and evaluating safety classifiers and guardrail models in dialogues for the Banking, Financial Services, and Insurance (BFSI) domain. The dataset is generated through the FinSafeGuard pipeline, which employs a four-stage process (pre-generation research, conditional self-evolution, two-layer deduplication, LLM-as-Judge filtering) to transform 26.4 million raw synthetic samples into 14.3 million high-confidence samples. The currently released Ultra-Mini version contains 709,303 safety-annotated dialogues, covering 20 BFSI risk categories, in an instruction-tuning format, suitable for supervised fine-tuning of safety classifiers and reasoning-based safety evaluation models. The dataset is in JSONL format, with each record containing a two-turn dialogue: a user instruction asking the model to evaluate whether an embedded <CONVERSATION> has BFSI safety violations, and an assistant response that includes a `<think>` reasoning trace and a final verdict. Key fields include: original_label (safe/unsafe), original_category (one of 20 risk categories, filled only when unsafe), original_severity (severity level, filled only when unsafe). The data is split into training (496,854 entries), validation (106,142 entries), and test (106,307 entries) sets, with 154,946 safe samples and 554,357 unsafe samples. The dataset is applicable for safety classifier/guardrail SFT for BFSI assistants and chatbots, reasoning-based safety evaluation, benchmarking across fine-grained BFSI risk categories and severity levels, and red-teaming research on financial attack vectors.
创建时间:
2026-05-07
搜集汇总
数据集介绍
构建方式
FinSafeGuard数据集由Domyn团队构建,旨在应对金融领域人工智能安全挑战。其构建过程遵循一套严谨的四阶段流水线:首先进行预生成研究,设计涵盖银行业、金融服务与保险(BFSI)的层次化安全分类体系;其次实施条件自动演化,基于九维场景元组(涵盖风险类别、严重程度、角色、意图、渠道等)进行领域与模式特定的合成生成;随后通过双层去重机制,依次执行基于n-gram的词汇去重与基于嵌入的语义去重,消除冗余样本;最终借助LLM-as-Judge筛选,保留仅高置信度的安全与不安全样本,并附带推理轨迹。原始数据从2640万条粗糙合成样本精炼至1430万条高质量示例,本版本为超迷你变体,包含709,303条对话,覆盖20种BFSI风险类别。
使用方法
用户可通过Hugging Face的datasets库直接加载该数据集,使用load_dataset('domyn/FinSafeGuard')即可获取训练、验证与测试三个划分。数据以JSONL格式存储,每条记录遵循OpenAI风格的多轮对话结构,包含用户指令与助理响应,后者融合了推理轨迹与最终裁决。该数据集适用于多种下游任务:可对安全分类器与守卫模型进行监督微调,训练基于推理的安全评判模型,或作为细粒度BFSI风险类别与严重程度的基准测试集。同时,其丰富的对抗场景还可用于金融领域红队攻击向量研究。值得注意的是,数据集的Ultra-Mini版本规模适合快速实验,而完整版本可供大规模训练,且所有数据均遵循CC-BY-NC-4.0许可协议。
背景与挑战
背景概述
FinSafeGuard是由Domyn研究团队于2025年构建的面向金融人工智能安全的质量驱动合成数据集,旨在解决银行、金融服务与保险(BFSI)领域对话中安全分类与护栏模型训练的数据匮乏问题。该数据集源于对26.4百万原始合成样本的严格治理,经过预生成研究、条件自演进、双层去重及大语言模型评审过滤四阶段流程,最终产出709,303条高质量标注样本,覆盖20种细粒度BFSI风险类别与5级严重程度分级。作为首个系统性地聚焦金融领域AI安全的合成基准资源,FinSafeGuard填补了从通用安全数据集到垂直金融安全评估的语义鸿沟,对推动可负责任金融大语言模型的研发具有里程碑意义。
当前挑战
金融对话安全评估面临的核心挑战在于风险类别的专业性与动态性:BFSI领域涉及反洗钱、合规规避、欺诈识别等20种专属风险类型,其判断依赖深厚的领域知识,远超通用安全模型的认知边界。数据构建阶段亦遭遇多维困难——如何设计可覆盖罕见金融攻击向量的多样化场景元组、如何消除大规模合成数据中的语义冗余、以及如何确保LLM评审判定的置信度一致性。FinSafeGuard通过9维场景条件生成与双层去重策略缓解了分布偏差,并引用严格的金标准标签机制保证了标注可靠性,为金融安全评估提供了稀缺的高置信度训练信号。
常用场景
经典使用场景
在金融科技与负责任人工智能的交汇领域中,FinSafeGuard数据集被广泛用于微调银行、金融服务与保险场景下的安全分类器与护栏模型。该数据集通过两轮指令微调格式,将用户对金融对话安全性的评估请求与助手包含推理链的安全判定无缝融合,适用于构建能够对多层风险对话进行精准判定的监督式安全模型。其涵盖20个细粒度BFSI风险类别的标注体系,使其成为金融领域安全推理基准测试与红队演练语料库的不二之选。
解决学术问题
该数据集系统性地解决了金融领域人工智能安全治理中标注数据匮乏的核心难题。其通过条件自动演化与LLM判别过滤相结合的流水线方法,产出了高质量的安全标注样本,填补了金融合规场景下对抗性安全测试与风险分类研究的空白。它为学术界提供了从洗钱规避到暗黑模式等20种风险类别的标准化评估框架,使得细粒度安全模型性能度量和跨方法比较成为可能,推动了金融对话系统中可解释性安全判据的学术探索。
实际应用
在产业界,FinSafeGuard被部署于金融助手的实时安全监控系统,其多轮对话风险识别能力可有效拦截不合规的财务建议、风险披露缺失及欺诈诱导行为。金融机构利用该数据集训练的护栏模型,能够在客户服务对话中自动标记潜在的反洗钱规避类发言。此外,该数据集还被用于构建监管合规审计工具,帮助企业在符合CC-BY-NC-4.0许可的前提下,对内部AI系统的金融安全表现进行持续评测与合规保障。
数据集最近研究
最新研究方向
在金融AI安全的前沿研究中,FinSafeGuard的诞生回应了银行业、金融服务与保险(BFSI)领域对可信AI护栏模型的迫切需求。该数据集通过创新的四阶段流水线——涵盖预生成研究、条件自动演进、双层去重及LLM-as-Judge过滤——从2640万原始合成样本中精炼出1430万高置信度示例,其Ultra-Mini变体包含70.9万条涵盖20种BFSI风险类别的安全标注对话。这一方向不仅为细粒度风险分类与推理式安全裁判模型的监督微调提供了高质量训练基准,更推动了金融领域红队测试语料库的建设,助力应对反洗钱合规规避、欺诈身份窃取等现实威胁,为负责任的AI在金融系统的安全部署奠定了可靠的数据根基。
以上内容由遇见数据集搜集并总结生成


