ML-ready-dataset
收藏github2024-07-27 更新2024-07-28 收录
下载链接:
https://github.com/akidwai1/ML-ready-dataset
下载链接
链接失效反馈官方服务:
资源简介:
该项目生成的数据集帮助预测蛋白质上的N-连接和O-连接糖基化位点。数据集包含了蛋白质的访问号、糖基化类型、氨基酸修改以及相关的基因本体术语,适用于机器学习应用。
The dataset generated by this project aids in predicting N-linked and O-linked glycosylation sites on proteins. It includes protein accession numbers, glycosylation types, amino acid modifications, and relevant Gene Ontology terms, and is suitable for machine learning applications.
创建时间:
2024-07-27
原始信息汇总
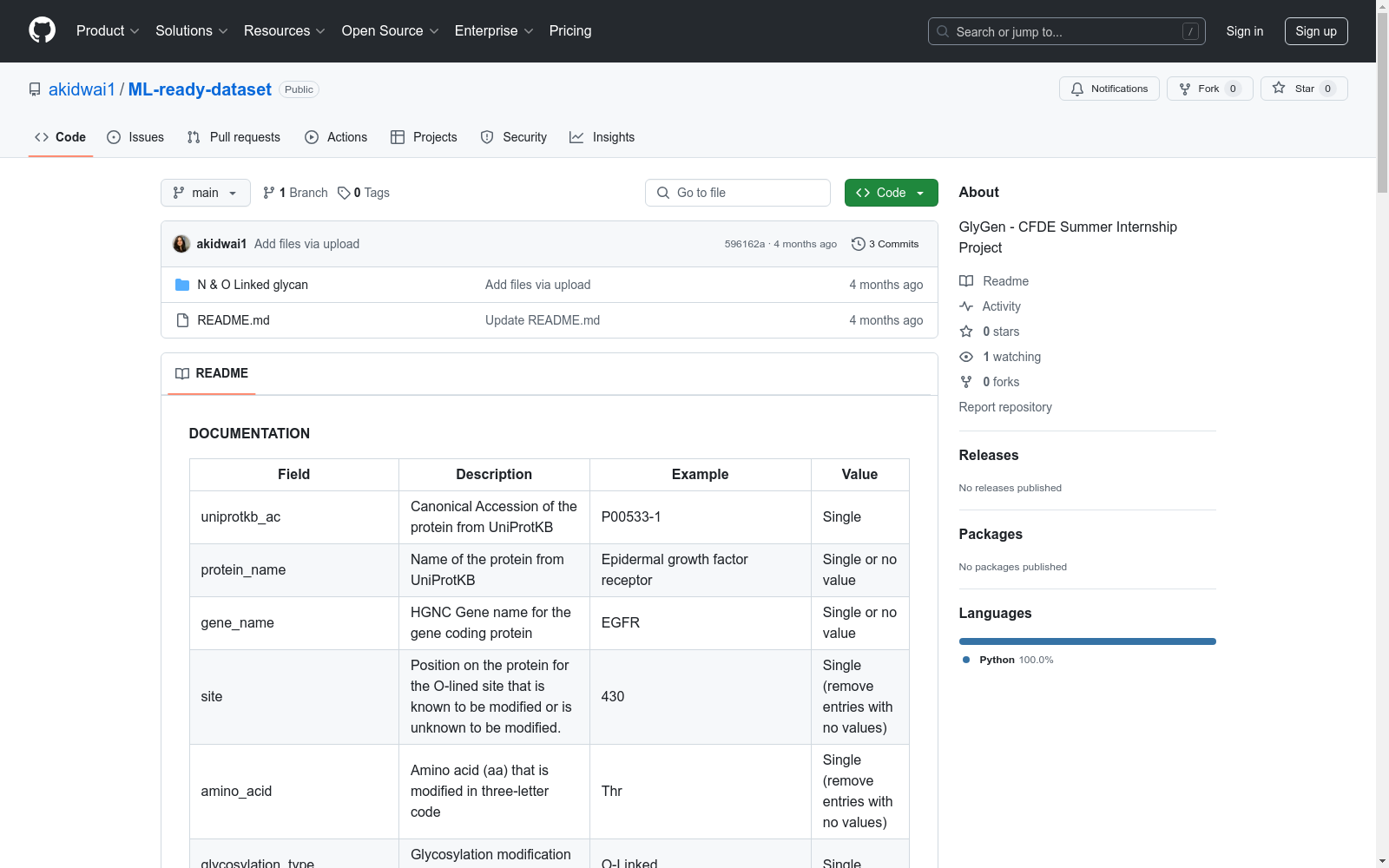
数据集字段说明
| 字段 | 描述 | 示例 | 值类型 |
|---|---|---|---|
| uniprotkb_ac | UniProtKB中蛋白质的规范访问号 | P00533-1 | 单值 |
| protein_name | UniProtKB中蛋白质的名称 | Epidermal growth factor receptor | 单值或无值 |
| gene_name | 编码蛋白质的HGNC基因名称 | EGFR | 单值或无值 |
| site | 已知或未知被修饰的O-连接位点的蛋白质位置 | 430 | 单值(删除无值条目) |
| amino_acid | 被修饰的氨基酸(aa)的三字母代码 | Thr | 单值(删除无值条目) |
| glycosylation_type | 蛋白质上存在的糖基化修饰 | O-Linked | 单值 |
| glycosylation_subtype | 蛋白质上糖基化的亚型或特定形式 | O-GlcNAcylation | 单值或其他 |
| glytoucan_ac | 附着在蛋白质上的特定糖结构的唯一标识符 | G49108TO | 单值或无值 |
| reducing_end_monosacchride | 糖结构的还原端存在的单糖 | GlcNAc | 单值 |
| core_fucosylated | 蛋白质是否含有核心岩藻糖修饰 | Y或N | 单值 |
| source_tissue | 蛋白质样本取自的组织 | gizzard (UBERON : 0005052) | |
| o-glcnacsylation | 残基上观察到的O-Glcnacsylation | Y或N | 单值 |
| peptide_seq_five_before | 修饰残基前5个aa的肽序列(向N端上游) | IIRGR | 单值或无值 |
| peptide_seqfive_after | 修饰残基后5个aa的肽序列(向C端下游) | KQHGQ | 单值或无值 |
| peptide_seq_ten_before | 修饰残基前10个aa的肽序列(向N端上游) | FENLEIIRGR | 单值或无值 |
| peptide_seqten_after | 修饰残基后10个aa的肽序列(向C端下游) | KQHGQFSLAV | 单值或无值 |
| organism | 蛋白质所属生物的科学名称 | Homo sapiens | 单值 |
| taxonomy_id | 生物科学名称的NCBI分类ID | 9606 | 单值 |
| molecular_function | 基因本体分子功能名称和ID | ATPase binding (GO:0051117) | ATP binding (GO:0005524) |
| biological_process | 基因本体生物学功能名称和ID | activation of phospholipase C activity (GO:0007202) | astrocyte activation (GO:0048143) |
| cellular_component | 基因本体分子功能名称和ID | apical plasma membrane (GO:0016324) | basal plasma membrane (GO:0009925) |
| domain | 域的描述 | Protein kinase | 单值或无值 |
| range | 域内的氨基酸范围 | 150-408 | 单值或无值 |
| status | 该位点是否已知或未知被糖基化 | Known_glycoste<br>potential_glycosite | 单值或无值 |
搜集汇总
数据集介绍
构建方式
ML-ready-dataset的构建基于对蛋白质和糖基化信息的全面收集与处理。该数据集通过整合来自UniProtKB的蛋白质访问号、基因名称、氨基酸修饰位置等详细信息,以及Gene Ontology的分子功能、生物过程和细胞组分等生物学注释,形成了一个结构化的数据格式。此外,数据集还包含了糖基化类型、子类型、糖链结构标识符等关键信息,确保了数据的完整性和准确性。通过自动化脚本处理API请求和数据输出,最终生成了一个适用于机器学习应用的准备就绪的数据集。
特点
ML-ready-dataset的显著特点在于其高度结构化和详尽的信息内容。数据集不仅涵盖了蛋白质的基本属性,如访问号、基因名称和氨基酸修饰位置,还详细记录了糖基化修饰的类型、子类型及糖链结构的唯一标识符。此外,数据集还整合了Gene Ontology的生物学注释,提供了分子功能、生物过程和细胞组分的详细描述,为深入的生物学研究和机器学习模型的训练提供了丰富的数据支持。
使用方法
使用ML-ready-dataset时,用户首先需要确保系统中安装了Python 3.x版本,并通过pip安装必要的Python包,如requests和pandas。随后,用户可以通过克隆包含Python脚本的仓库,并执行相应的命令来运行程序。程序支持多种命令行选项,如无缓存重启、输出格式选择和API版本切换,用户可以根据需求灵活配置。最终,处理后的数据将以TSV或CSV格式保存,便于进一步的分析和应用。
背景与挑战
背景概述
ML-ready-dataset数据集由一位研究人员创建,旨在生成一个适用于机器学习的蛋白质N-连接和O-连接糖基化位点预测的数据集。该数据集的构建动机源于糖基化在多种生物过程中的关键作用,通过提供精确的蛋白质访问号、糖基化类型、氨基酸修饰及相关的基因本体论术语,该数据集为机器学习应用提供了结构化的格式。此数据集的创建不仅有助于识别糖基化位点,还为相关领域的研究提供了宝贵的资源。
当前挑战
ML-ready-dataset数据集在构建过程中面临多项挑战。首先,数据集需要处理来自不同来源的蛋白质和糖基化信息,确保数据的准确性和一致性。其次,数据集的构建涉及复杂的API请求和数据处理,需要确保脚本的稳定性和高效性。此外,数据集的输出格式需灵活适应不同的分析需求,如TSV和CSV格式。最后,数据集的维护和更新也是一个持续的挑战,确保其与最新的生物信息学资源保持同步。
常用场景
经典使用场景
在生物信息学领域,ML-ready-dataset数据集的经典使用场景主要集中在蛋白质糖基化位点的预测。该数据集通过整合来自UniProtKB的蛋白质信息、基因名称、氨基酸修饰位置及其糖基化类型等详细数据,为机器学习模型提供了丰富的特征输入。研究者可以利用这些特征,构建预测模型,以识别和预测蛋白质上的O-连接和N-连接糖基化位点,从而深入理解糖基化在生物过程中的作用。
解决学术问题
ML-ready-dataset数据集解决了生物信息学中关于蛋白质糖基化位点预测的常见学术问题。通过提供精确的蛋白质修饰信息和糖基化类型,该数据集为研究者提供了一个标准化的数据平台,有助于提高糖基化位点预测模型的准确性和可靠性。这不仅推动了糖基化生物学的研究进展,还为相关疾病的诊断和治疗提供了新的视角和方法。
衍生相关工作
ML-ready-dataset数据集的发布催生了一系列相关的经典工作。例如,基于该数据集,研究者开发了多种机器学习算法,用于预测蛋白质的糖基化位点,并在此基础上进一步研究糖基化对蛋白质功能的影响。此外,该数据集还被用于构建和验证新的生物信息学工具,如糖基化位点预测软件和数据库,这些工具在学术界和工业界都得到了广泛应用。
以上内容由遇见数据集搜集并总结生成


