SANPO
收藏arXiv2023-09-21 更新2024-06-21 收录
下载链接:
https://google-research-datasets.github.io/sanpo_dataset/
下载链接
链接失效反馈官方服务:
资源简介:
SANPO数据集是由谷歌研究团队创建的大型户外场景理解数据集,专注于密集预测任务。该数据集包含112,000个真实视频和113,000个合成视频的密集分割掩码,以及相应的深度图。数据集采集自美国多个地点,覆盖了不同的环境、天气条件和时间。SANPO数据集不仅支持人类导航任务,还适用于多种密集预测任务,旨在推动视频分割、深度估计和合成到真实域适应等领域的技术发展。
The SANPO dataset is a large-scale outdoor scene understanding dataset created by the Google Research team, focusing on dense prediction tasks. It contains dense segmentation masks and corresponding depth maps for 112,000 real-world videos and 113,000 synthetic videos. The dataset is collected from multiple locations across the United States, covering diverse environments, weather conditions and time periods. Beyond supporting human navigation tasks, the SANPO dataset is applicable to a variety of dense prediction tasks, aiming to advance technological developments in fields such as video segmentation, depth estimation and synthetic-to-real domain adaptation.
提供机构:
谷歌研究
创建时间:
2023-09-21
搜集汇总
数据集介绍
构建方式
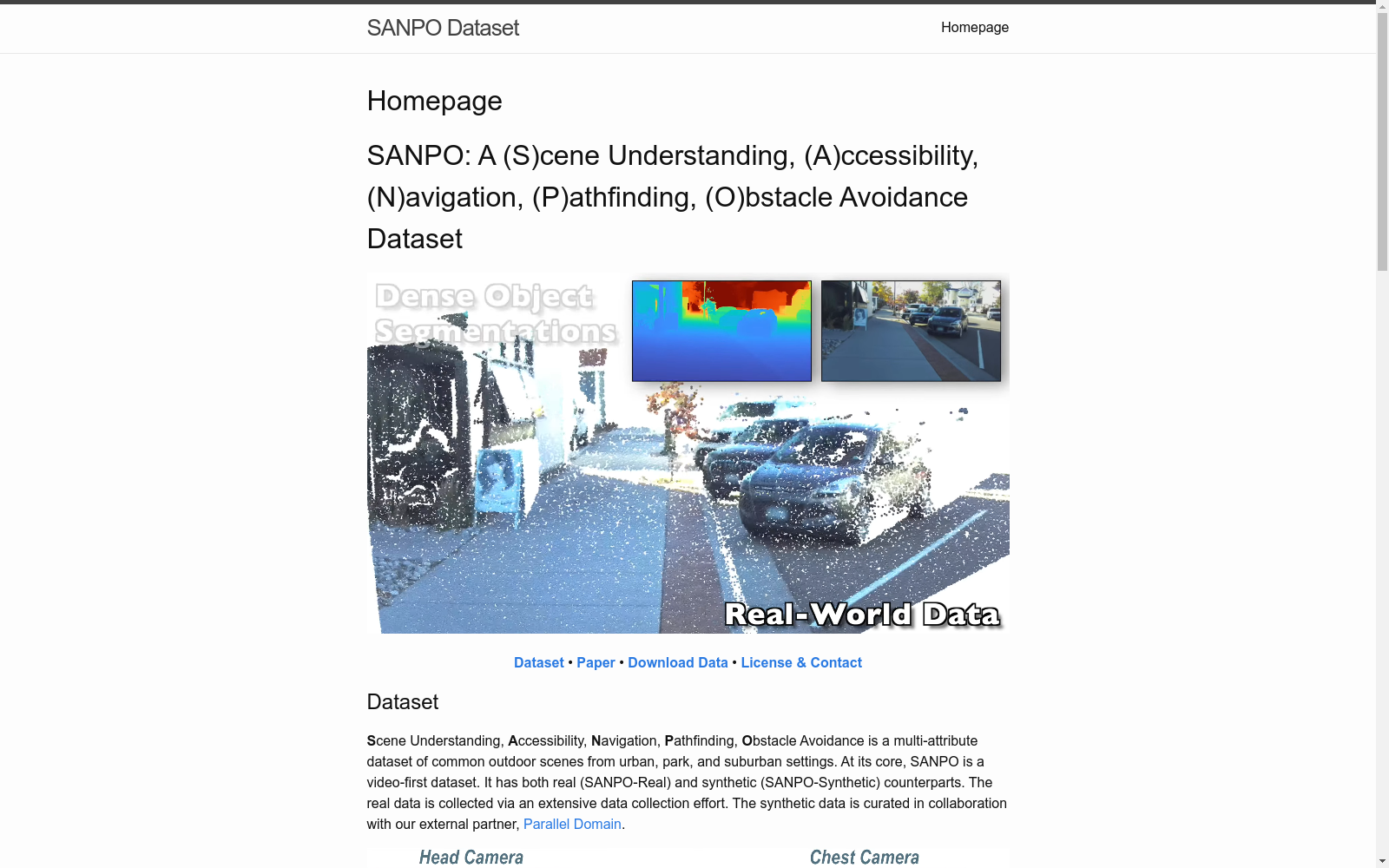
在户外场景理解领域,SANPO数据集的构建采用了双模态采集策略,融合了真实世界与合成环境的数据源。其实验数据通过定制化采集装置获取,志愿者佩戴头戴式ZED-M与胸戴式ZED-2i立体相机系统,在美国多地采集涵盖城市街道、公园、郊区等多样化场景的701个立体视频会话。合成数据则通过Parallel Domain虚拟环境生成,精确模拟真实相机的光学参数与空间布局。标注流程采用级联标注与AOT时序传播技术,对视频序列实施五帧采样标注,并通过算法插值确保全景分割标签的时序一致性,最终形成包含112K真实帧与113K合成帧的密集标注体系。
特点
该数据集的核心特征体现在多模态标注的完整性与场景复杂性。作为首个同时具备大规模密集全景分割与深度标注的人类第一视角视频数据集,SANPO提供617K真实深度图与113K合成深度图,并配备视觉里程计数据。其标注体系涵盖31个语义类别,区分物体实例与背景材质,合成数据更具备像素级精确的实例分割特性。数据场景涵盖昼夜变化、雨雪天气等真实环境变量,立体视频格式支持多视角视觉研究,而合成与真实数据的并行架构为域适应研究提供了理想实验平台。
使用方法
研究者可通过官方数据门户获取SANPO数据集,其结构化存储格式便于开展多任务学习。该数据集支持零样本基准测试与全监督训练两种范式:在零样本评估中,可利用预训练模型测试其在人类第一视角场景的泛化能力;在全监督模式下,可分别使用真实数据、合成数据或混合数据训练深度估计、语义分割与全景分割模型。数据划分已预设训练集与测试集,配套评估指标包括深度估计的δ≤1.25指标、语义分割的mIoU以及全景分割的PQ分数,支持跨域迁移与多任务联合学习等前沿研究方向。
背景与挑战
背景概述
在计算机视觉领域,以人为中心的场景理解是机器人学、增强现实及辅助技术等应用的核心基础。2023年,谷歌研究院与Parallel Domain合作推出了SANPO数据集,旨在填补户外人类自我中心视角下密集预测任务的空白。该数据集包含真实与合成两部分视频,涵盖立体视觉、密集深度、全景分割及视觉里程计等多模态标注,其规模达到数十万帧,覆盖多样化的环境与天气条件。SANPO的构建不仅推动了视频分割、深度估计等任务的进展,更为人类导航系统的开发提供了关键数据支持。
当前挑战
SANPO数据集致力于解决人类自我中心场景理解中的复杂问题,其核心挑战在于模型对非结构化户外环境的泛化能力。现有自动驾驶数据集虽具备丰富标注,却难以适应人类视角下的动态交互、运动模糊及非常规视角。构建过程中,数据采集面临隐私保护、多传感器同步及标注一致性的难题;合成数据虽提供精确标注,但与真实数据间的域差异仍显著,导致模型在跨域迁移时性能下降。这些挑战共同凸显了SANPO在推动密集预测与域适应研究中的关键价值。
常用场景
经典使用场景
在户外人类第一人称视觉导航研究领域,SANPO数据集凭借其大规模、多模态标注的特性,成为评估视频全景分割与深度估计模型性能的经典基准。该数据集通过头戴式与胸戴式立体相机采集的真实场景视频,以及高度仿真的合成视频,为研究者提供了涵盖复杂动态环境、多变天气条件及不同运动模式的丰富样本。其核心应用场景在于推动视觉导航系统在非结构化户外环境中的感知能力,特别是在处理人类视角特有的运动模糊、非常规视角及动态交互等挑战时,为模型训练与验证提供了前所未有的真实性与多样性。
衍生相关工作
围绕SANPO数据集,已衍生出多个具有影响力的研究方向与经典工作。在零样本泛化评估方面,研究团队利用DPT、ZoeDepth等先进深度估计模型,以及Kmax-Deeplab、Mask2Former等分割模型,建立了跨数据集性能基准,揭示了人类中心化任务与自动驾驶领域间的显著域差异。在合成到真实域适应研究中,SANPO提供的成对真实与合成数据,为探索域间差异量化与自适应算法提供了理想实验平台。此外,基于该数据集的全景分割与深度联合学习框架,推动了多任务视觉模型在复杂动态场景中的性能优化。这些工作不仅深化了对第一人称视觉理解本质的认识,也为后续在视觉导航、辅助技术等领域的算法创新提供了重要参考。
数据集最近研究
最新研究方向
在视觉场景理解领域,SANPO数据集的推出标志着人类以自我为中心(egocentric)的户外导航研究迈入了新阶段。该数据集融合了真实与合成的大规模立体视频,并提供了密集的全景分割与深度标注,填补了现有自动驾驶数据集在人类视角理解上的空白。当前的前沿研究聚焦于利用SANPO推动视频分割、深度估计、多任务视觉建模以及合成到真实域的适应技术发展。其独特的挑战性,如非传统视角、运动伪影及动态交互,正激励学界探索更具鲁棒性的模型,以服务于辅助导航、机器人及增强现实等应用,为构建普适性视觉系统提供了关键基准。
相关研究论文
- 1SANPO: A Scene Understanding, Accessibility, Navigation, Pathfinding, Obstacle Avoidance Dataset谷歌研究 · 2023年
以上内容由遇见数据集搜集并总结生成


