zcc-ir-prime-v1
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://huggingface.co/datasets/zkaedi/zcc-ir-prime-v1
下载链接
链接失效反馈官方服务:
资源简介:
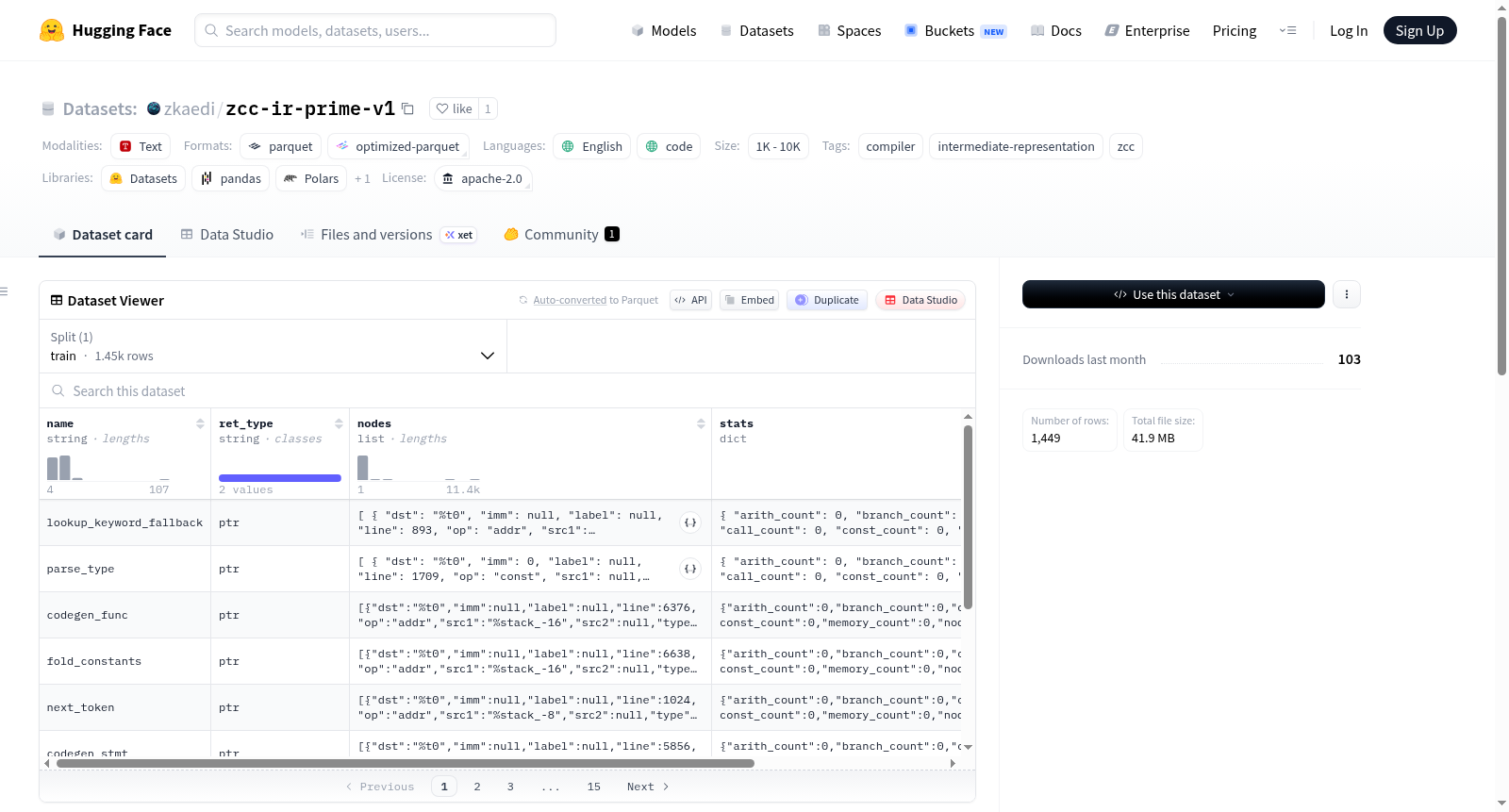
该数据集以YAML格式提供了结构化的描述,详细说明了数据特征、分割和配置。数据集模式包含多个字段,如操作类型(op)、源操作数(src1, src2)、目标操作数(dst)和类型(type),暗示其可能代表某种代码或指令数据。此外,数据集包含统计特征(stats),如算术操作计数(arith_count)、分支计数(branch_count)、调用计数(call_count)等,以及能量相关指标(prime_energy, prime_h0, prime_h_final),表明其可能用于性能或能耗分析任务。数据集仅包含一个训练集(train),共有177个样本,总大小为2,113,219字节。
创建时间:
2026-04-07
搜集汇总
数据集介绍
构建方式
在编译器优化与中间表示分析领域,ZCC IR PRIME v1数据集通过Zkaedi C编译器(ZCC)系统化生成。该数据集收录了1,449个函数级别的中间表示图,涵盖ZCC自编译过程与libcurl网络库的编译结果。构建过程中,每个C函数被编译为三地址静态单赋值形式的中间表示,并采用自主PRIME哈密顿能量动力学模型与语义评估体系进行量化评分,从而形成兼具结构表征与优化负载度量的标准化数据集合。
使用方法
研究人员可将该数据集应用于编译器优化算法评估、中间表示模式分析及代码生成模型训练。使用时可依据source字段区分自编译与库编译样本,通过ir_text字段获取中间表示的结构信息,并利用prime_score字段进行优化负载的量化比较。数据集支持对ZCC编译器在嵌入式架构(如thumbv6m-none-eabi后端)的跨编译器验证研究,亦可用于分析编译过程中出现的特定错误模式,为编译器开发与静态分析提供实证数据支撑。
背景与挑战
背景概述
在编译器设计与程序分析领域,中间表示作为源代码与目标机器码之间的桥梁,其质量直接影响编译优化的效能与可靠性。ZCC IR PRIME v1数据集由Zkaedi C编译器项目于2026年前后创建,旨在提供一组经过能量动力学与语义评估标注的函数级IR图。该数据集聚焦于ZCC编译器在自编译及编译libcurl网络库时生成的静态单赋值形式三地址码,为核心研究问题——如何量化评估中间表示的复杂度与优化潜力——提供了实证基础。通过结合自主PRIME哈密顿能量动态评分,该数据集为编译器优化、代码生成验证及硬件后端测试等研究方向提供了关键数据支撑,尤其对嵌入式系统编译链的成熟度验证具有显著影响力。
当前挑战
该数据集致力于应对编译器中间表示分析与优化评估中的核心挑战,即如何建立一套能够全面衡量IR图结构复杂度、语义完整性及优化负载的量化指标体系。在构建过程中,研究人员需克服多方面的技术难题:其一,确保ZCC编译器在跨架构目标(如thumbv6m-none-eabi后端)上生成IR的准确性与一致性,尤其是在硬件验证环节需处理如CG-ARM系列的新增错误;其二,设计并实施自主PRIME能量动态评分模型,以融合形式化动力学与语义评价,避免评分偏差;其三,整合异构代码源(自编译代码与第三方库)的IR数据,保证数据集的代表性与平衡性,从而为编译器优化研究提供可靠基准。
常用场景
经典使用场景
在编译器设计与中间表示优化领域,zcc-ir-prime-v1数据集为研究人员提供了宝贵的实验资源。该数据集收录了由Zkaedi C编译器生成的函数级中间表示图,其经典使用场景集中于编译器后端优化算法的评估与验证。研究者可借助这些IR图分析不同优化策略对代码性能的影响,特别是在静态单赋值形式下探索指令调度与寄存器分配的效果。数据集中的PRIME评分机制进一步允许量化评估IR的复杂性与优化潜力,为自动化编译器调优提供了基准测试平台。
解决学术问题
该数据集有效应对了编译器研究中若干关键挑战。它通过提供真实编译场景下的IR实例,解决了传统优化算法评估依赖合成数据或有限基准的局限性。PRIME能量动力学评分体系为IR的质量度量引入了物理启发的数学模型,使得研究者能够从信息熵与语义保持角度量化优化效果。这促进了编译器中间表示的理论建模,并为跨平台编译验证提供了可重复的实验框架,尤其有助于嵌入式系统等资源受限环境的编译技术发展。
实际应用
在实际工程层面,zcc-ir-prime-v1数据集直接支持嵌入式系统与跨平台编译工具链的开发。例如,数据集包含的libcurl库编译IR可用于网络协议栈在微控制器上的性能优化研究。已验证的thumbv6m-none-eabi后端状态表明,该数据集能指导面向ARM Cortex-M系列硬件的编译器可靠性测试。此外,其记录的编译错误案例为工业级编译器调试提供了实证材料,加速了从理论IR设计到实际硬件部署的转化进程。
数据集最近研究
最新研究方向
在编译器优化与中间表示分析领域,ZCC IR PRIME v1数据集凭借其独特的PRIME哈密顿能量动力学评分机制,为静态程序分析与机器学习驱动的代码优化开辟了新路径。当前研究聚焦于利用该数据集中的语义评分矩阵,训练深度神经网络模型以预测中间表示图的优化潜力,从而自动化编译器启发式规则的设计。这一方向与嵌入式系统硬件验证热潮紧密相连,尤其在RP2040等微控制器平台上,数据集支持的交叉编译器后端验证工作,正推动着轻量级、高可靠编译工具链的发展,对物联网与边缘计算领域的软件效能提升具有实质性意义。
以上内容由遇见数据集搜集并总结生成


