scikit-learn/auto-mpg|汽车燃油效率数据集|机器学习数据集
收藏hugging_face2023-12-05 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/scikit-learn/auto-mpg
下载链接
链接失效反馈资源简介:
---
license: apache-2.0
task_categories:
- tabular-classification
- tabular-regression
language:
- en
tags:
- scikit-learn
pretty_name: auto-mpg
---
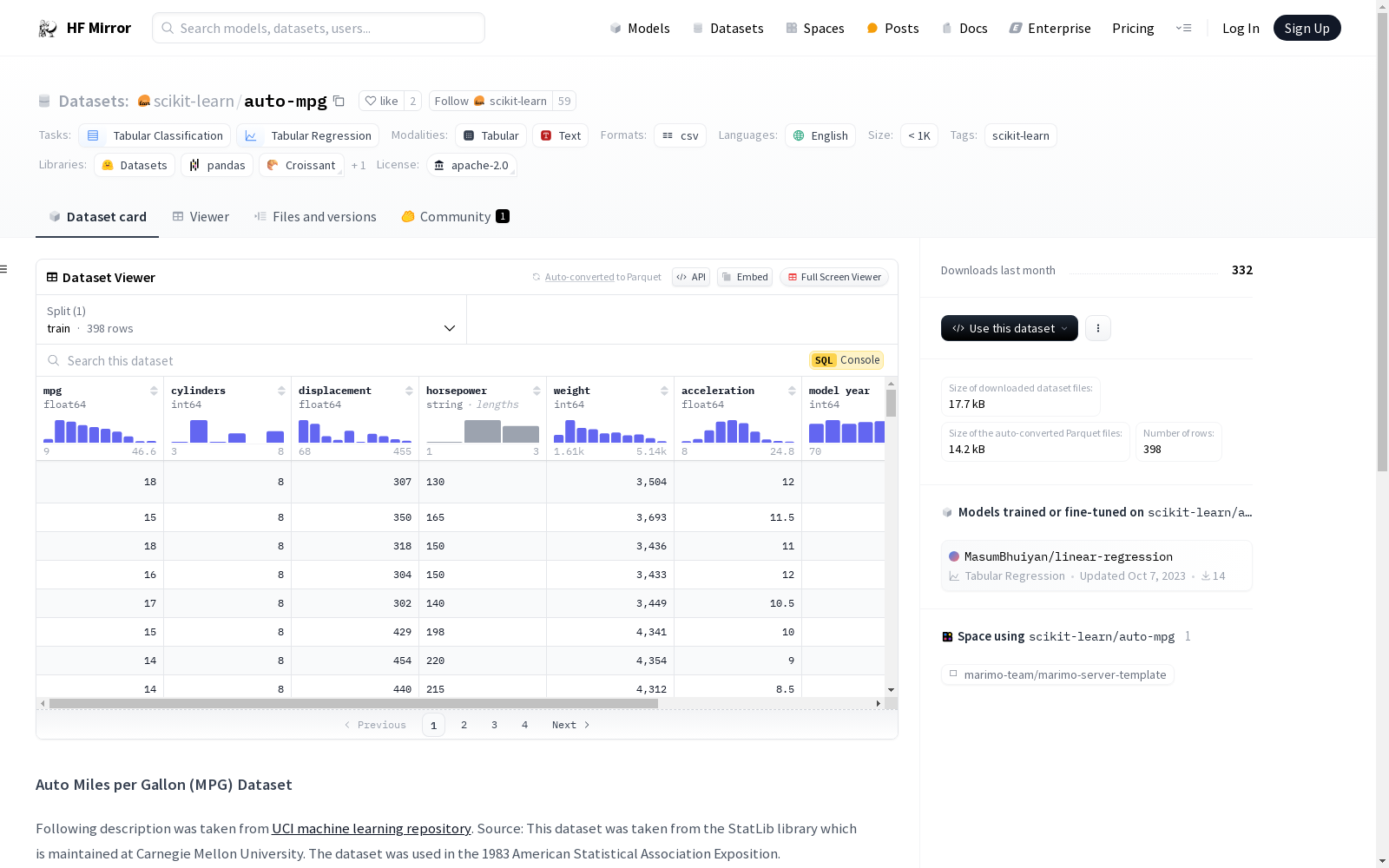
## Auto Miles per Gallon (MPG) Dataset
Following description was taken from [UCI machine learning repository](https://archive.ics.uci.edu/ml/datasets/auto+mpg).
Source: This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University. The dataset was used in the 1983 American Statistical Association Exposition.
## Data Set Information:
This dataset is a slightly modified version of the dataset provided in the StatLib library. In line with the use by Ross Quinlan (1993) in predicting the attribute "mpg", 8 of the original instances were removed because they had unknown values for the "mpg" attribute. The original dataset is available in the file "auto-mpg.data-original".
"The data concerns city-cycle fuel consumption in miles per gallon, to be predicted in terms of 3 multivalued discrete and 5 continuous attributes." (Quinlan, 1993)
## Attribute Information:
- mpg: continuous
- cylinders: multi-valued discrete
- displacement: continuous
- horsepower: continuous
- weight: continuous
- acceleration: continuous
- model year: multi-valued discrete
- origin: multi-valued discrete
- car name: string (unique for each instance)
提供机构:
scikit-learn
原始信息汇总
数据集概述
数据集名称
- 名称: Auto Miles per Gallon (MPG) Dataset
数据集来源
- 来源: 该数据集源自StatLib图书馆,由卡内基梅隆大学维护,并在1983年美国统计协会博览会上使用。
数据集信息
- 描述: 此数据集是StatLib库提供的原始数据集的稍微修改版本。为了与Ross Quinlan(1993)在预测属性“mpg”时的使用保持一致,移除了8个具有“mpg”属性未知值的原始实例。
- 目的: 数据涉及城市循环燃料消耗的英里每加仑(mpg),旨在通过3个多值离散属性和5个连续属性进行预测。
属性信息
- mpg: 连续
- cylinders: 多值离散
- displacement: 连续
- horsepower: 连续
- weight: 连续
- acceleration: 连续
- model year: 多值离散
- origin: 多值离散
- car name: 字符串(每个实例唯一)
许可
- 许可: Apache-2.0
任务类别
- 任务类别:
- 表格分类
- 表格回归
语言
- 语言: 英语
标签
- 标签: scikit-learn
AI搜集汇总
数据集介绍
构建方式
该数据集源自卡内基梅隆大学的StatLib库,最初用于1983年美国统计协会博览会。为适应特定预测任务,数据集经过轻微调整,移除了8条因缺失'mpg'属性值而无法使用的原始实例。这一调整确保了数据集在预测城市循环燃料消耗方面的实用性和完整性。
使用方法
该数据集适用于表格分类和回归任务,特别适合用于预测汽车的燃油效率。用户可通过加载数据集,利用其包含的连续和离散属性进行模型训练,以实现对'mpg'属性的精准预测。数据集的结构清晰,属性定义明确,便于直接应用于各类机器学习算法中。
背景与挑战
背景概述
Auto Miles per Gallon (MPG) 数据集,源自卡内基梅隆大学的StatLib库,最初用于1983年美国统计协会博览会。该数据集的核心研究问题围绕城市循环燃料消耗的预测,具体是通过3个多值离散属性和5个连续属性来预测每加仑行驶的英里数(MPG)。数据集经过Ross Quinlan(1993年)的修改,移除了8条因MPG属性值缺失的原始实例,从而形成了当前版本。此数据集在机器学习领域,特别是在表格分类和回归任务中,具有重要的应用价值,为研究者提供了一个标准化的基准数据集,用以评估和比较不同算法的性能。
当前挑战
Auto MPG数据集在构建和应用过程中面临多项挑战。首先,数据集的原始版本包含缺失值,这要求在预处理阶段进行数据清洗和插补,以确保数据的完整性和准确性。其次,数据集涉及多个属性的混合类型,包括连续变量和离散变量,这增加了模型选择的复杂性,需要考虑不同类型变量的处理方法。此外,数据集的规模相对较小,可能限制了某些复杂模型的训练效果,尤其是在需要大量数据进行参数估计的深度学习模型中。最后,数据集的应用场景主要集中在燃料效率的预测,这要求模型不仅要具有高预测精度,还需具备良好的解释性,以便于理解影响燃料效率的关键因素。
常用场景
经典使用场景
在汽车工程与数据科学交叉领域,scikit-learn/auto-mpg数据集常用于预测汽车的燃油效率,即每加仑汽油可行驶的英里数(MPG)。通过分析汽车的多个属性,如气缸数、排量、马力、重量和加速度等,研究者可以构建回归模型,从而精准预测不同车型的燃油经济性。这一经典应用场景不仅为汽车制造商提供了优化设计的可能性,也为消费者在购车决策时提供了数据支持。
解决学术问题
该数据集有效解决了在汽车燃油效率预测中的关键学术问题,特别是在多变量回归分析领域。通过整合多种离散和连续属性,研究者能够探索各属性对燃油效率的独立与交互影响,进而提升模型的预测精度。这一研究不仅推动了回归分析技术的发展,还为相关领域的学者提供了标准化的数据集,促进了学术研究的深入与广泛应用。
实际应用
在实际应用中,scikit-learn/auto-mpg数据集被广泛用于汽车行业的燃油效率优化与消费者决策支持系统。汽车制造商利用该数据集进行车型设计优化,以提高燃油经济性,降低运营成本。同时,消费者可通过基于该数据集的预测模型,比较不同车型的燃油效率,从而做出更为理性的购车选择。此外,该数据集还被用于政府和环保组织的政策制定,以推动节能减排目标的实现。
数据集最近研究
最新研究方向
在汽车工程与数据科学的交叉领域,scikit-learn/auto-mpg数据集因其对城市循环燃油效率的详细记录而备受关注。最新研究方向主要集中在利用机器学习技术,如回归分析和分类模型,来精准预测汽车的燃油消耗。这些研究不仅有助于优化车辆设计,提升燃油经济性,还为政策制定者提供了科学依据,以推动更环保的交通解决方案。此外,随着可持续发展和绿色技术的日益重要,该数据集的应用前景愈发广阔,尤其是在智能交通系统和自动驾驶技术的研发中,其潜在价值不容忽视。
以上内容由AI搜集并总结生成


