nlpso/m1_qualitative_analysis_ref_cmbert_io
收藏Hugging Face2023-02-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/nlpso/m1_qualitative_analysis_ref_cmbert_io
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- fr
multilinguality:
- monolingual
task_categories:
- token-classification
---
# m1_qualitative_analysis_ref_cmbert_io
## Introduction
This dataset was used to perform **qualitative analysis** of [Jean-Baptiste/camembert-ner](https://huggingface.co/Jean-Baptiste/camembert-ner) on **nested NER task** using Independant NER layers approach [M1].
It contains Paris trade directories entries from the 19th century.
## Dataset parameters
* Approach : M1
* Dataset type : ground-truth
* Tokenizer : [Jean-Baptiste/camembert-ner](https://huggingface.co/Jean-Baptiste/camembert-ner)
* Tagging format : IO
* Counts :
* Train : 6084
* Dev : 676
* Test : 1685
* Associated fine-tuned models :
* Level-1 : [nlpso/m1_ind_layers_ref_cmbert_io_level_1](https://huggingface.co/nlpso/m1_ind_layers_ref_cmbert_io_level_1)
* Level 2 : [nlpso/m1_ind_layers_ref_cmbert_io_level_2](https://huggingface.co/nlpso/m1_ind_layers_ref_cmbert_io_level_2)
## Entity types
Abbreviation|Entity group (level)|Description
-|-|-
O |1 & 2|Outside of a named entity
PER |1|Person or company name
ACT |1 & 2|Person or company professional activity
TITREH |2|Military or civil distinction
DESC |1|Entry full description
TITREP |2|Professionnal reward
SPAT |1|Address
LOC |2|Street name
CARDINAL |2|Street number
FT |2|Geographical feature
## How to use this dataset
```python
from datasets import load_dataset
train_dev_test = load_dataset("nlpso/m1_qualitative_analysis_ref_cmbert_io")
---
语言:
- 法语
多语言属性:
- 单语言
任务类别:
- 词元分类(Token Classification)
---
# m1_qualitative_analysis_ref_cmbert_io
## 简介
本数据集用于基于独立NER层方法[M1],对[Jean-Baptiste/camembert-ner](https://huggingface.co/Jean-Baptiste/camembert-ner)模型开展**嵌套命名实体识别(Nested NER)任务**的定性分析。数据集包含19世纪巴黎工商名录条目。
## 数据集参数
* 方法:M1
* 数据集类型:真值标注数据集
* 分词器(Tokenizer):[Jean-Baptiste/camembert-ner](https://huggingface.co/Jean-Baptiste/camembert-ner)
* 标注格式:IO格式
* 样本数量:
* 训练集:6084条
* 验证集:676条
* 测试集:1685条
* 关联微调模型:
* 层级1:[nlpso/m1_ind_layers_ref_cmbert_io_level_1](https://huggingface.co/nlpso/m1_ind_layers_ref_cmbert_io_level_1)
* 层级2:[nlpso/m1_ind_layers_ref_cmbert_io_level_2](https://huggingface.co/nlpso/m1_ind_layers_ref_cmbert_io_level_2)
## 实体类型
|缩写|实体组(层级)|说明|
|-|-|-|
|O|1、2层级|非命名实体区域|
|PER|层级1|人物或企业名称|
|ACT|1、2层级|人物或企业的职业/经营活动|
|TITREH|层级2|军事或民事荣誉称号|
|DESC|层级1|条目完整描述|
|TITREP|层级2|职业荣誉奖励|
|SPAT|层级1|地址|
|LOC|层级2|街道名称|
|CARDINAL|层级2|街道门牌号|
|FT|层级2|地理实体|
## 数据集使用方法
python
from datasets import load_dataset
train_dev_test = load_dataset("nlpso/m1_qualitative_analysis_ref_cmbert_io")
提供机构:
nlpso
原始信息汇总
数据集概述
数据集名称
m1_qualitative_analysis_ref_cmbert_io
数据集描述
该数据集用于对Jean-Baptiste/camembert-ner进行嵌套命名实体识别任务的定性分析,采用独立NER层方法[M1]。数据集包含19世纪巴黎贸易目录的条目。
数据集参数
- 方法:M1
- 数据集类型:ground-truth
- 分词器:Jean-Baptiste/camembert-ner
- 标记格式:IO
- 数据集大小:
- 训练集:6084
- 验证集:676
- 测试集:1685
- 相关联的微调模型:
实体类型
| 缩写 | 实体组(级别) | 描述 |
|---|---|---|
| O | 1 & 2 | 非命名实体 |
| PER | 1 | 个人或公司名称 |
| ACT | 1 & 2 | 个人或公司职业活动 |
| TITREH | 2 | 军事或民事区别 |
| DESC | 1 | 条目全描述 |
| TITREP | 2 | 职业奖励 |
| SPAT | 1 | 地址 |
| LOC | 2 | 街道名称 |
| CARDINAL | 2 | 街道号码 |
| FT | 2 | 地理特征 |
如何使用数据集
python from datasets import load_dataset
train_dev_test = load_dataset("nlpso/m1_qualitative_analysis_ref_cmbert_io")
搜集汇总
数据集介绍
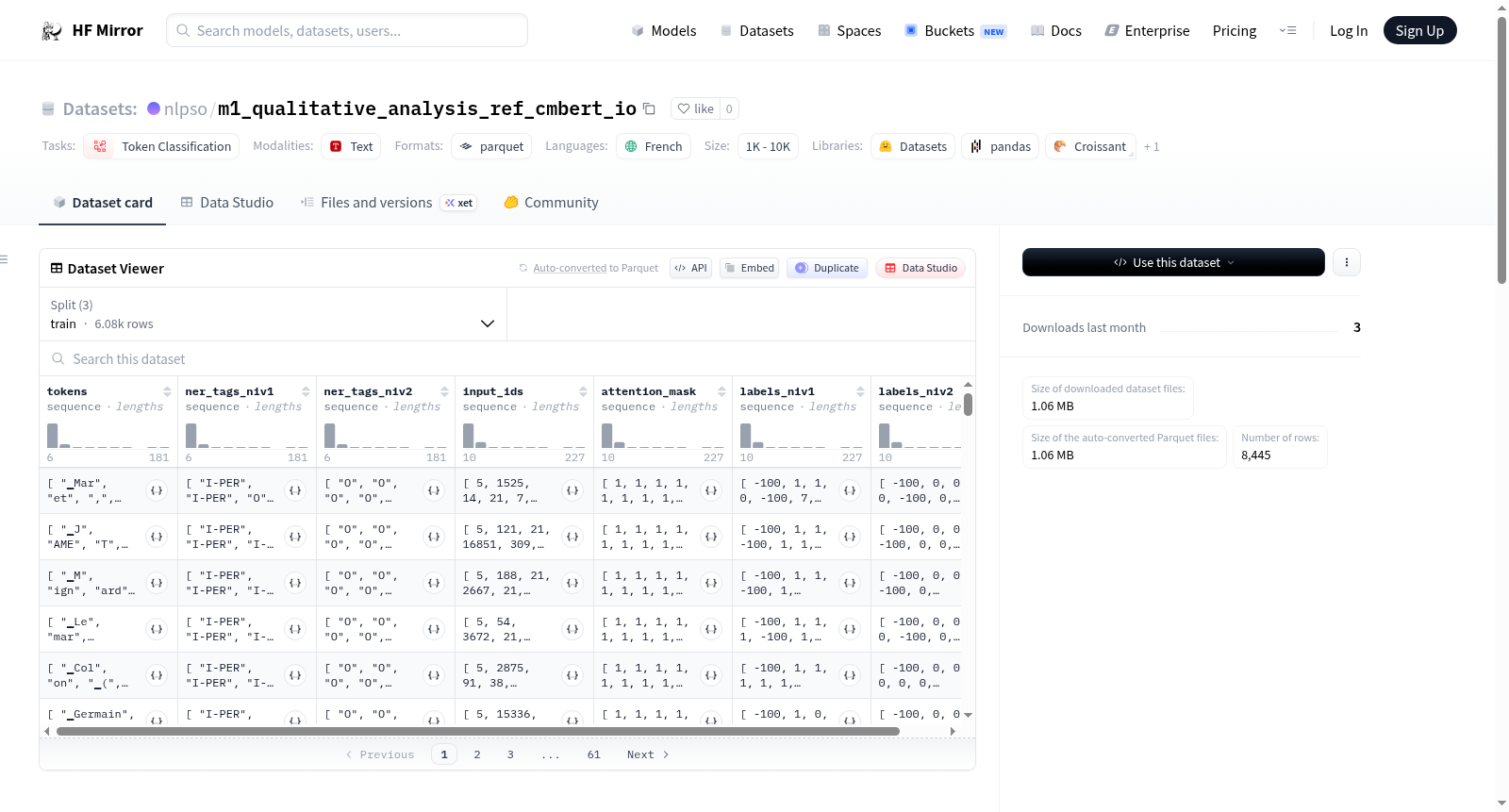
构建方式
在历史语言学与数字人文的交叉领域,该数据集以19世纪巴黎商业名录条目为原始语料,采用独立命名实体识别层方法(M1)构建而成。其构建过程首先运用CamemBERT-NER分词器对法语文本进行精细化处理,随后依据IO标注格式对嵌套命名实体进行层级化标注,形成了包含训练集、开发集与测试集的完整语料体系,为嵌套命名实体识别任务提供了结构化的评估基准。
特点
该数据集在法语历史文献处理领域展现出鲜明的专业特性,其核心特征在于采用双层实体标注架构,将传统命名实体(如人物、地址)与专业语义范畴(如军事头衔、职业荣誉)进行解耦标注。数据集涵盖PER、ACT、SPAT等基础实体类型,同时包含TITREH、TITREP等历史文献特有的细粒度类别,这种层级化标签体系为分析嵌套实体识别模型的语义解耦能力提供了多维度的观察视角。
使用方法
研究人员可通过HuggingFace数据集库直接加载该语料,使用标准接口即可获取已划分的训练、开发与测试子集。该数据集主要服务于嵌套命名实体识别模型的定性评估,用户可结合配套的微调模型进行层级化性能分析,通过对比基础实体与嵌套实体的识别效果,深入探究独立层方法在历史文献处理任务中的语义边界划分能力与结构化解码特性。
背景与挑战
背景概述
在自然语言处理领域,历史文献的数字化与信息提取是连接过去与未来的重要桥梁。数据集nlpso/m1_qualitative_analysis_ref_cmbert_io由相关研究团队于近期构建,专注于19世纪巴黎商业名录条目的嵌套命名实体识别任务。该数据集依托CamemBERT模型,采用独立层方法(M1),旨在深入分析模型在复杂历史文本上的性能表现。其核心研究问题聚焦于如何从非结构化的历史档案中自动识别多层次实体,如人物、职业、地址等,为数字人文和计算历史学提供了宝贵的标注资源,推动了跨学科研究的发展。
当前挑战
该数据集所解决的领域问题是嵌套命名实体识别,其挑战在于历史文本中实体边界模糊、嵌套结构复杂,且语言表达与现代法语存在差异,导致模型难以准确区分不同层次的语义信息。构建过程中的挑战则体现在数据标注上:19世纪商业名录条目格式多样、缩写频繁,需要领域专家进行精细的层级标注,确保实体类型如军事头衔、地理特征等的准确划分,同时保持标注一致性,这增加了数据收集与验证的难度。
常用场景
经典使用场景
在历史语言学与数字人文领域,该数据集为研究19世纪巴黎商业目录的嵌套命名实体识别提供了珍贵语料。其经典应用场景在于评估独立层方法(M1)在法语嵌套实体抽取任务中的性能,通过精细标注的实体层级结构,支持对CamemBERT-ner模型在复杂历史文本上的表现进行系统性分析。
衍生相关工作
基于该数据集衍生的经典工作包括独立层嵌套NER架构的优化研究,以及跨世纪法语文本的领域自适应方法探索。相关研究进一步拓展至欧洲多语言历史文献的联合标注范式,催生了如HISTNER等系列历史文本处理框架的演进。
数据集最近研究
最新研究方向
在历史档案文本挖掘领域,嵌套命名实体识别(NER)任务正成为前沿探索的核心。该数据集聚焦于19世纪巴黎商业目录条目,为CamemBERT模型在嵌套NER上的定性分析提供了基准。当前研究热点集中于独立层级方法(M1)在处理复杂实体结构时的效能评估,特别是针对人物、地址及职业活动等多层次标签的细粒度解析。这一方向不仅推动了法语历史文献的自动化处理进程,也为跨时代社会经济模式的量化研究开辟了新途径,具有重要的文化遗产数字化意义。
以上内容由遇见数据集搜集并总结生成


