TOTO
收藏arXiv2023-07-01 更新2024-06-21 收录
下载链接:
https://toto-benchmark.org/
下载链接
链接失效反馈官方服务:
资源简介:
TOTO数据集是由卡内基梅隆大学机器人研究所创建的,专注于机器人操作学习的基准数据集。该数据集包含2898条轨迹,涵盖了日常生活中的两个操作任务:倾倒和舀取。数据收集过程中采用了远程操作和行为克隆等技术,以确保数据的多样性和实用性。TOTO数据集的应用领域主要集中在机器人学习算法的评估和改进,特别是在处理未知物体、位置和光照条件下的操作任务。
The TOTO dataset, developed by the Robotics Institute at Carnegie Mellon University, is a benchmark dataset dedicated to robotic manipulation learning. This dataset contains 2898 trajectories, covering two daily manipulation tasks: pouring and scooping. Technologies such as teleoperation and behavior cloning were employed during the data collection process to ensure the diversity and practicality of the dataset. The primary application scenarios of the TOTO dataset lie in the evaluation and improvement of robotic learning algorithms, particularly for manipulation tasks involving unknown objects, positions, and lighting conditions.
提供机构:
卡内基梅隆大学机器人研究所
创建时间:
2023-06-02
搜集汇总
数据集介绍
构建方式
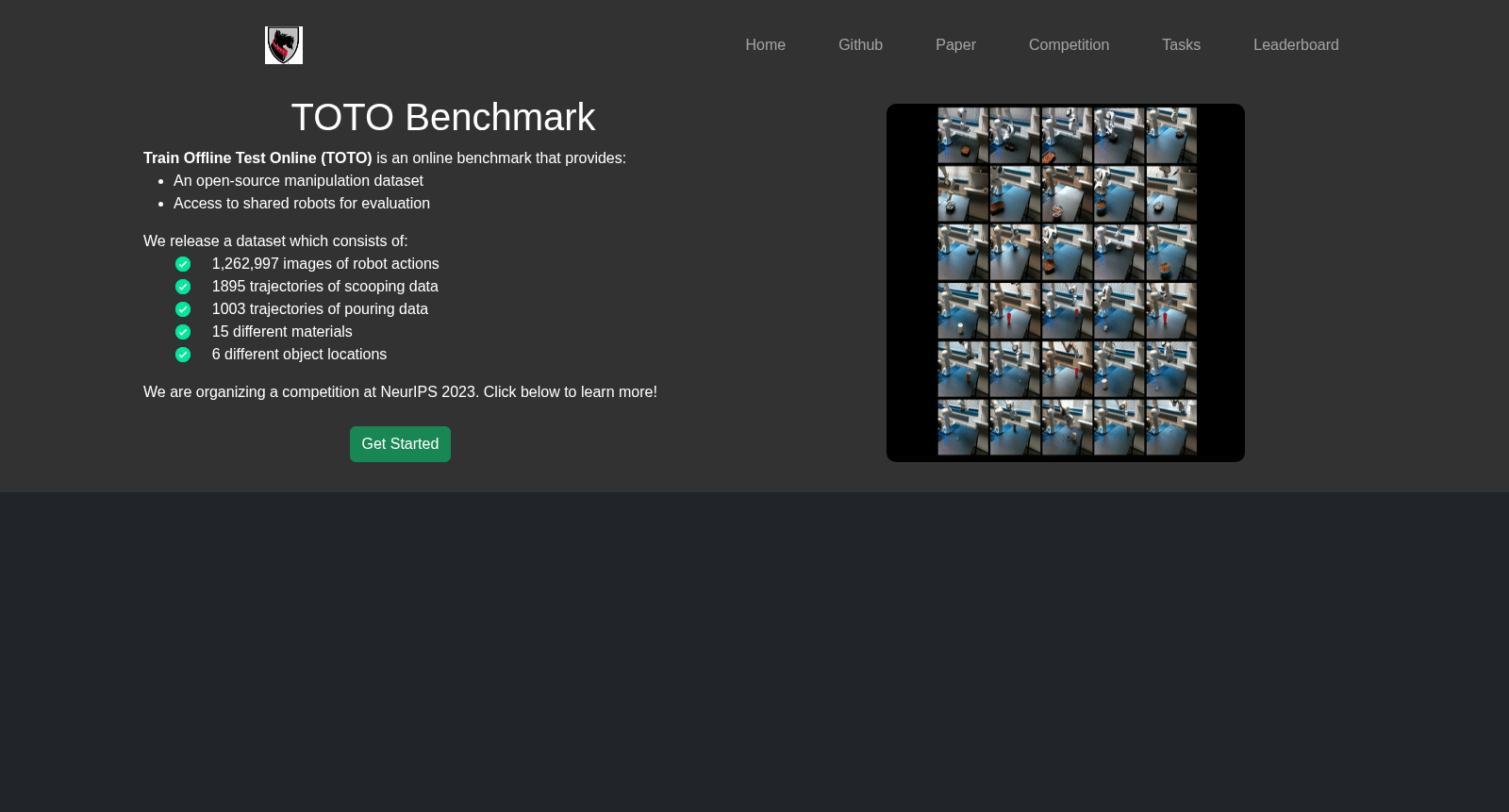
在机器人学习领域,构建具有广泛适用性的数据集是推动算法进步的关键。TOTO数据集的构建采用了多模态数据采集策略,通过Franka Emika Panda机械臂与Intel D435 RealSense相机系统,在真实物理环境中收集了涵盖舀取和倾倒两项日常操作任务的轨迹数据。数据采集融合了三种技术:基于虚拟现实设备的遥操作,确保了高质量示范;行为克隆滚动执行,通过注入噪声增强多样性;以及轨迹回放,结合环境光照变化扩展数据分布。初始版本包含约2,898条轨迹,每条轨迹均记录了图像观察、关节状态、动作指令及奖励信号,形成了结构化的离线学习资源。
使用方法
使用TOTO数据集进行研究遵循一套清晰的工作流程。研究者首先下载开源的轨迹数据,可在本地利用提供的软件工具包训练离线策略,如模仿学习或离线强化学习算法。训练完成后,用户通过指定表单提交策略模型至TOTO平台,由平台在共享的机器人硬件上自动执行评估。评估过程在受控环境下进行,使用预设的未见物体与位置组合,并最终反馈执行视频与量化奖励指标。这一流程使得研究者无需自行搭建昂贵硬件或收集数据,即可高效验证算法在真实机器人任务上的性能,并通过公开排行榜与不断扩充的社区数据持续推动领域进展。
背景与挑战
背景概述
机器人学习领域长期面临硬件成本高昂、实验平台异构以及缺乏大规模真实世界数据等核心瓶颈,制约着研究的可复现性与可比性。为应对这些挑战,卡内基梅隆大学、斯坦福大学、加州大学伯克利分校等机构的研究团队于2022年联合推出了TOTO(Train Offline, Test Online)基准测试平台。该平台聚焦于机器人操作任务,旨在通过提供统一的离线数据集与远程共享硬件评估环境,建立公平、低门槛的算法评测标准。TOTO的核心研究问题在于探索离线策略学习与视觉表征在真实机器人泛化任务中的有效性,其设计显著降低了机器人学习的研究门槛,促进了跨机构协作与算法迭代,对推动机器人学习从仿真向真实世界过渡具有重要影响力。
当前挑战
TOTO基准致力于解决机器人操作任务中策略与视觉表征的泛化能力评估问题,其核心挑战在于要求算法在未见过的物体、位置及光照条件下完成舀取和倾倒等精细操作。这涉及从高维图像输入到连续动作输出的复杂映射,并需克服任务中的非马尔可夫特性与动态不确定性。在数据集构建过程中,研究团队面临多重挑战:真实机器人数据采集成本高昂且易受硬件故障干扰;需通过遥操作、行为克隆回放与轨迹重播等多种技术平衡数据多样性与质量;同时,评估协议的设计需兼顾自动化程度与公平性,例如奖励度量与场景重置仍部分依赖人工干预,未来需进一步探索自动化解决方案以支撑大规模评估。
常用场景
经典使用场景
在机器人学习领域,TOTO数据集为离线策略评估提供了标准化平台。该数据集通过共享硬件设施和开源数据,使研究人员能够在统一环境中测试模仿学习与离线强化学习算法。经典使用场景涉及在固定数据集上训练视觉表示模型与策略,随后在真实机器人硬件上远程评估其泛化能力,涵盖舀取和倾倒等日常操作任务。这种设置促进了跨实验室的公平比较,显著降低了机器人研究的参与门槛。
解决学术问题
TOTO数据集主要解决了机器人学习研究中硬件成本高昂、实验条件不一致以及缺乏大规模真实世界数据的问题。通过提供共享的离线数据集和远程评估硬件,该数据集使得不同算法能够在相同条件下进行对比,从而推动视觉表示学习、策略泛化以及跨领域迁移等核心学术问题的探索。其标准化协议有助于识别算法在物体、位置和光照变化下的鲁棒性,为机器人学习社区提供了可靠的性能基准。
实际应用
在实际应用层面,TOTO数据集为机器人技能学习提供了可扩展的测试框架。其远程评估机制允许研究机构无需购置昂贵硬件即可验证算法在真实场景中的有效性,特别适用于服务机器人、工业自动化等领域的技能开发。例如,通过该数据集训练的舀取和倾倒策略可直接应用于家庭辅助或物流分拣任务,加速了从仿真到现实世界的技术迁移。
数据集最近研究
最新研究方向
在机器人学习领域,TOTO(Train Offline, Test Online)基准测试的推出,标志着离线学习与真实硬件评估结合的范式转变。该数据集聚焦于日常操作任务,如舀取和倾倒,通过提供共享的机器人硬件访问和开源数据集,降低了研究门槛,促进了跨实验室的公平比较。前沿研究方向集中在视觉表示学习与离线策略学习的协同优化,特别是在未见物体、位置和光照条件下的泛化能力。热点事件包括基于自监督学习的视觉模型(如BYOL和MoCo)与离线强化学习算法(如IQL和决策变换器)的性能对比,这些探索揭示了领域内数据表示对策略泛化的关键影响。TOTO的意义在于构建了一个可扩展的社区驱动平台,加速了真实世界机器人学习的迭代进程,为算法鲁棒性和通用性设立了新标准。
相关研究论文
- 1Train Offline, Test Online: A Real Robot Learning Benchmark卡内基梅隆大学机器人研究所 · 2023年
以上内容由遇见数据集搜集并总结生成


