fnlp/moss-003-sft-data
收藏Hugging Face2024-07-16 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/fnlp/moss-003-sft-data
下载链接
链接失效反馈资源简介:
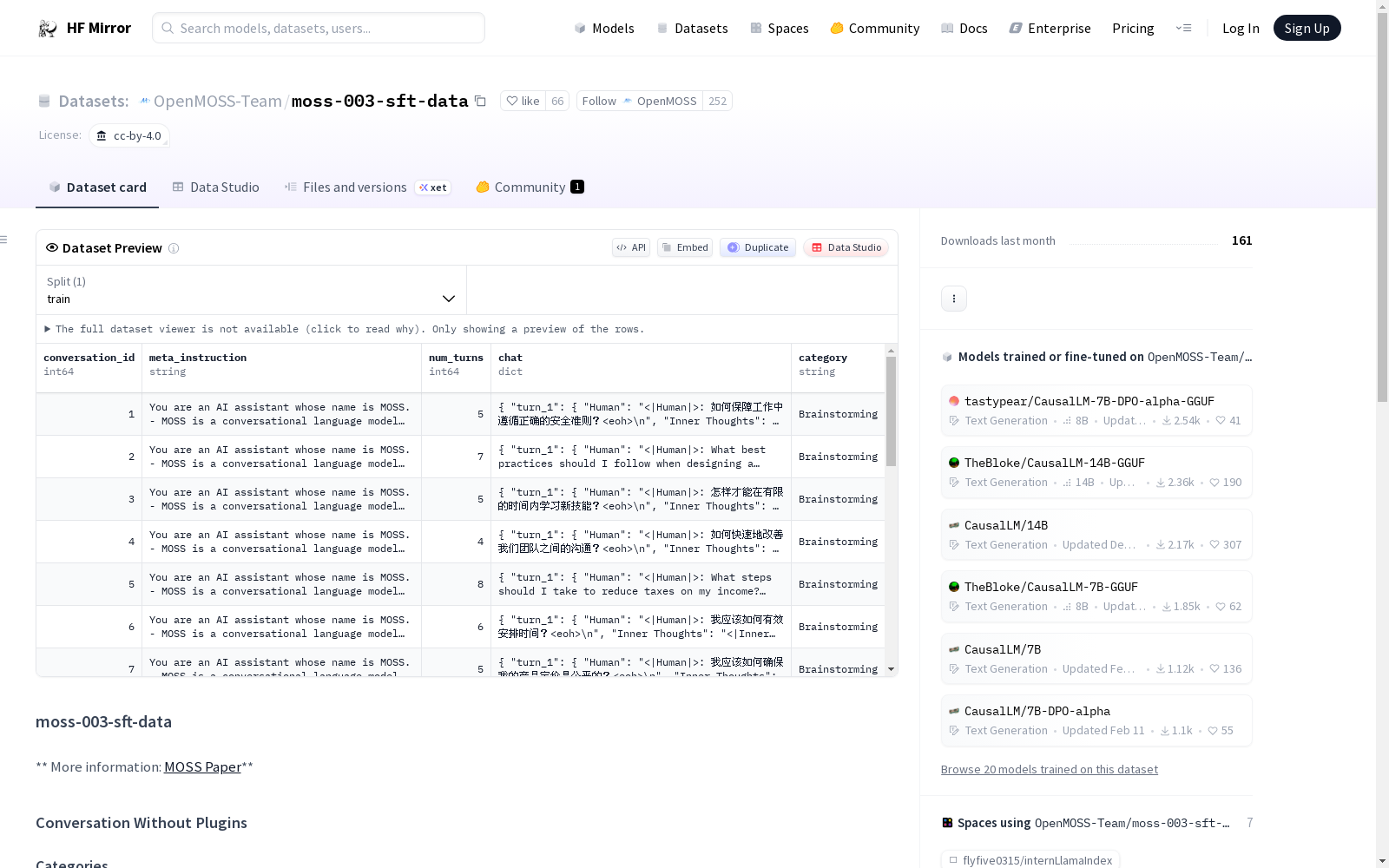
moss-003-sft-data数据集包含两个主要部分:无插件对话和有插件对话。无插件对话部分涵盖了多种对话类别,包括头脑风暴、复杂指令、代码、角色扮演、写作、无害等,总计1,074,551个样本。Others类别包含Continue和Switching子类别,分别指用户要求系统继续输出未完成的响应和用户切换使用语言的实例。有插件对话部分包括使用搜索引擎、计算器、方程求解器和指令到图像转换插件的对话,总计约350,000个样本。
The moss-003-sft-data dataset consists of two main parts: conversations without plugins and conversations with plugins. The part without plugins covers various categories such as brainstorming, complex instructions, code, role-playing, writing, harmless, etc., totaling 1,074,551 samples. The Others category includes subcategories Continue and Switching, referring to instances where the user asks the system to continue outputting an incomplete response and where the user switches the language they are using, respectively. The part with plugins includes conversations using plugins like search engines, calculators, equation solvers, and instruction-to-image conversion, totaling approximately 350,000 samples.
提供机构:
fnlp
原始信息汇总
moss-003-sft-data
数据集概述
- 许可协议:cc-by-4.0
- 总样本数:1,074,551
数据集分类及样本数
| 类别 | 样本数 |
|---|---|
| Brainstorming | 99,162 |
| Complex Instruction | 95,574 |
| Code | 198,079 |
| Role Playing | 246,375 |
| Writing | 341,087 |
| Harmless | 74,573 |
| Others | 19,701 |
Others类别细分
- Continue:9,839
- Switching:9,862
其他信息
- Continue类别:指用户要求系统继续输出前一轮未完成的响应的对话实例。
- Switching类别:指用户在对话中切换使用语言的实例。
- 移除的数据:因包含私人信息,移除了诚实相关的数据。
搜集汇总
数据集介绍
构建方式
fnlp/moss-003-sft-data数据集的构建,是在遵循cc-by-4.0版权协议的基础上,通过对大量对话数据进行分类和筛选而形成。该数据集涵盖了脑力激荡、复杂指令、代码编写、角色扮演、写作、无害性对话等多个类别,总计约107万余条样本。在构建过程中,特别区分了继续对话和切换语言两种特殊场景,并删除了涉及隐私的信息,以保障数据的安全性和可用性。
特点
该数据集的特点在于其多样性及实用性,不仅包含了无插件的纯对话数据,还包含了使用搜索引擎、计算器、方程求解器等插件的对话数据。这种分类使得数据集能够满足不同场景下的研究需求,特别是在自然语言处理、对话系统评估和优化等领域具有极高的应用价值。此外,数据集的样本量之大,也为其提供了丰富的学习和分析资源。
使用方法
使用fnlp/moss-003-sft-data数据集时,用户可根据具体的研究需求,选择相应的对话类别。数据集的开放协议使得用户可以在尊重版权的前提下,自由地使用和分享这些数据。针对数据集的预处理和使用,用户应遵循数据安全和个人隐私保护的相关规定,确保数据使用的合法性和道德性。
背景与挑战
背景概述
moss-003-sft-data数据集,作为自然语言处理领域的重要资源,其创建旨在推进对话系统的智能化与实用化。该数据集由.fnlp团队开发,并于近年来公布于众。数据集汇集了大规模的对话样本,包含多种对话类型,如头脑风暴、复杂指令、代码编写等,总样本量超过百万。moss-003-sft-data的构建,不仅丰富了对话系统的训练素材,也为相关领域的研究提供了有力支撑,对于推动对话系统的自然性和有效性研究具有重要影响。
当前挑战
尽管moss-003-sft-data数据集为对话系统研究提供了丰富的资源,但在实际应用中仍面临诸多挑战。首先,数据集在构建过程中需处理隐私信息,导致部分数据被移除,这可能影响数据集的完整性和实用性。其次,数据集中涉及的语言切换和多轮对话的连贯性,为对话系统的理解和响应增加了难度。此外,如何有效利用插件数据进行指令理解与执行,也是当前研究的一大挑战。
常用场景
经典使用场景
在自然语言处理领域,fnlp/moss-003-sft-data数据集的典型应用场景在于构建与评估对话系统。该数据集涵盖了大量未经插件干预的自然对话与涉及插件使用的复杂对话,为研究人员提供了丰富的样本资源,以训练对话模型以实现更流畅、自然的交互体验。
实际应用
在实用层面,fnlp/moss-003-sft-data数据集的应用推动了智能客服、语音助手等实际对话系统的优化。这些系统可以利用该数据集进行训练,从而更好地理解用户需求,并提供连贯、准确的响应,进而提升用户体验和服务质量。
衍生相关工作
基于fnlp/moss-003-sft-data数据集,研究者们衍生出了一系列相关工作,包括对话系统的多语言适应性研究、对话上下文理解技术的改进,以及对话生成模型的优化等。这些工作进一步拓展了自然语言处理领域的研究边界,推动了相关技术的商业化应用。
以上内容由遇见数据集搜集并总结生成


