MeasureBench
收藏arXiv2025-10-31 更新2025-11-04 收录
下载链接:
https://hf-mirror.com/datasets/FlagEval/MeasureBench
下载链接
链接失效反馈官方服务:
资源简介:
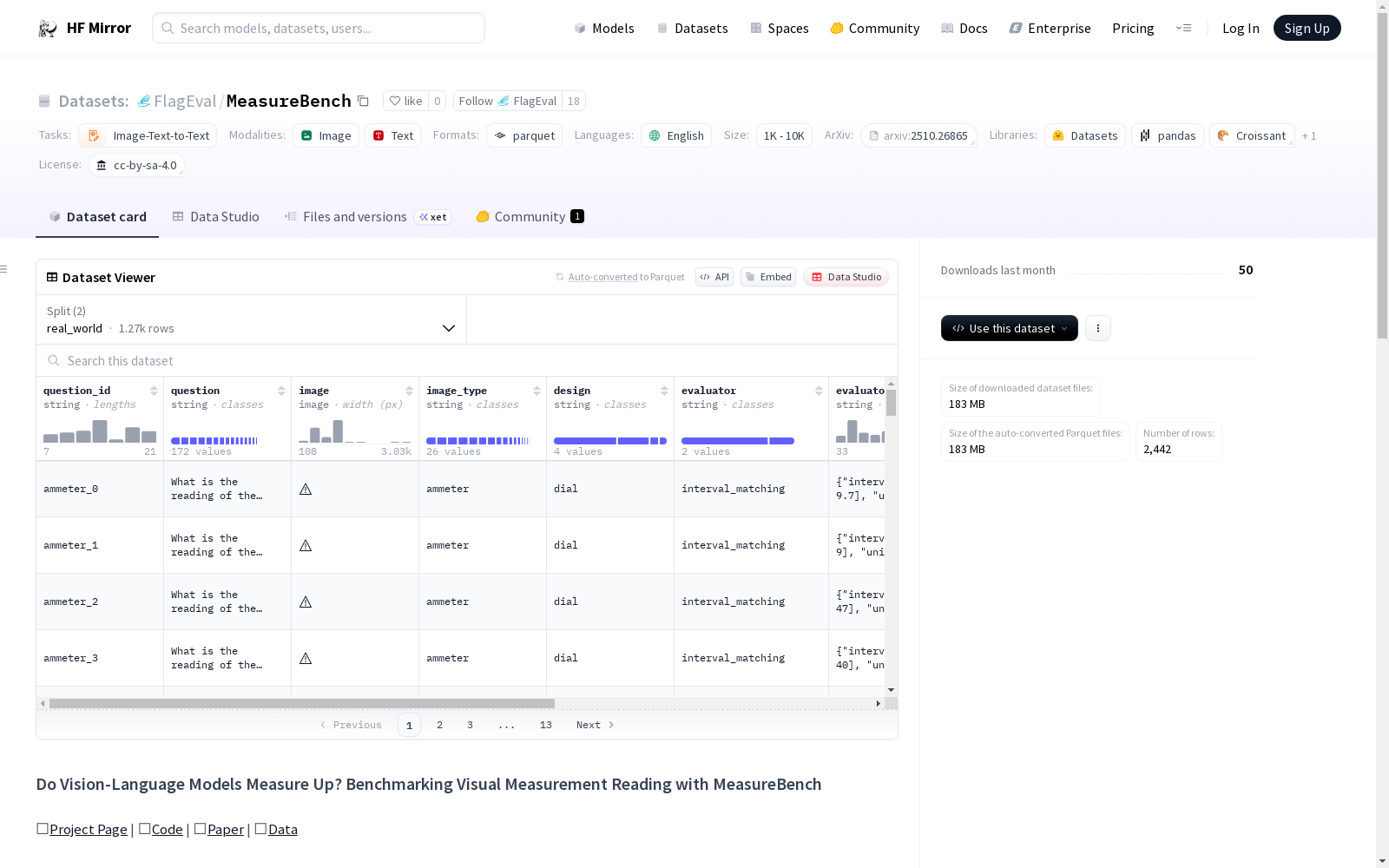
MeasureBench 是一个用于评估视觉语言模型(VLM)在读取测量仪器方面的能力的基准数据集。它包含了来自现实世界和合成图像的各种类型的测量仪器的多样化图像。数据集由 2,442 张图像组成,其中 1,272 张是现实世界的图像,1,170 张是合成的图像。现实世界的图像覆盖了 26 种仪器类型,而合成的图像覆盖了 16 种类型,共有 39 种不同的外观。MeasureBench 的目标是解决 VLM 在细粒度视觉感知和精确几何推理方面的局限性,以帮助未来的模型更好地理解和推理视觉线索。
MeasureBench is a benchmark dataset for evaluating the capability of Vision-Language Models (VLMs) in reading measuring instruments. It comprises diverse images of various types of measuring instruments from both real-world and synthetic sources. The dataset consists of 2,442 images in total, among which 1,272 are real-world images and 1,170 are synthetic ones. The real-world images cover 26 instrument types, while the synthetic ones cover 16 types, with a total of 39 distinct appearances. The core goal of MeasureBench is to address the limitations of VLMs in fine-grained visual perception and precise geometric reasoning, so as to assist future models in better understanding and reasoning about visual cues.
提供机构:
BAAI FlagEval Team
创建时间:
2025-10-31
原始信息汇总
MeasureBench 数据集概述
基本信息
- 数据集名称: MeasureBench
- 创建者: FlagEval
- 许可证: cc-by-sa-4.0
- 论文: arxiv: 2510.26865
技术规格
- 任务类型: Image-Text-to-Text
- 数据模态: 图像、文本
- 数据格式: parquet
- 编程库: Datasets、pandas、Croissant
- 语言: 英语
- 数据规模: 1K - 10K
数据结构
子集划分
- default: 2.44k 行
数据分割
- real_world: 1.27k 行
- synthetic_test: 1.17k 行
数据字段
- question_id: 字符串类型,长度范围 7-21
- question: 字符串类型,172 个不同取值
- image: 图像类型,宽度范围 108-3.03k 像素
- image_type: 字符串类型,26 个不同取值
- design: 字符串类型,4 个不同取值
- evaluator: 字符串类型,2 个不同取值
- evaluator_kwargs: 字符串类型,长度范围 33-144
- meta_info: 字典类型
- split: 字符串类型,1 个取值
数据示例特征
数据集中包含大量关于电流表读数的问题,涉及多种单位(安培、毫安培、微安培等),数据来源主要为 YouTube 视频和图片资源。
搜集汇总
数据集介绍
构建方式
在视觉语言模型快速发展的背景下,MeasureBench通过双轨制数据构建策略实现了测量仪器读取能力的系统评估。其实世界子集包含1,272张图像,源自网络搜索、团队采集与商业图库,经过专业标注者采用标准化流程进行多轮标注验证;合成子集则依托可扩展的生成框架,通过2D程序化渲染与3D物理渲染两种路径,实现了39种仪器外观的1,170张图像生成,该框架支持对指针角度、刻度范围、光照条件等关键参数进行精细化控制。
特点
该数据集在仪器类型覆盖与任务设计上展现出显著的系统性特征,涵盖26种仪器类型与四种读数设计(表盘、线性、数字、复合式),构建了2,442个图像-问题对。其核心优势在于通过区间匹配机制处理测量误差,并采用分层评估指标区分数值准确性与单位识别能力。合成数据生成框架更具备多维度变异能力,可在样式、尺度、朝向和类别四个轴向实现可控变化,为模型鲁棒性测试提供了丰富场景。
使用方法
研究者可通过标准化评估流程对视觉语言模型进行系统测试,重点关注指针定位、刻度解读等细粒度视觉理解能力。数据集支持答案提取与区间匹配的双重验证机制,可自动解析模型输出的数值与单位信息。基于合成数据的强化学习实验表明,该数据集能有效支撑模型微调与领域适应研究,其提供的程序化生成管道还可扩展用于训练数据增强,为提升模型在几何对齐与空间感知方面的能力提供重要支撑。
背景与挑战
背景概述
视觉语言模型在复杂推理任务中展现出卓越能力的同时,在细粒度视觉感知领域仍面临显著挑战。MeasureBench由北京智源人工智能研究院FlagEval团队于2025年提出,专注于测量仪器读数这一关键任务。该数据集包含26种仪器类型和2442个图像-问题对,涵盖真实世界图像与程序化合成数据,旨在系统评估模型在指针定位、刻度识别和数值映射等核心能力上的表现。其创新性数据合成框架通过可控的2D程序化渲染与3D物理渲染技术,为视觉语言模型的细粒度空间感知研究提供了重要基准。
当前挑战
测量仪器读数任务面临双重挑战:在领域问题层面,现有视觉语言模型在指针精确定位、刻度对应关系理解和数值映射等关键环节存在系统性缺陷,即使最优模型在真实数据集上的准确率仅达30.3%;在构建过程中,需克服真实图像采集的标注一致性难题,同时通过混合渲染技术平衡合成数据的视觉逼真度与几何精度。特别在复合式仪器评估中,模型需同步处理多组件读数并执行相应数值计算,这对当前模型的视觉-数值对应能力提出了严峻考验。
常用场景
实际应用
在实际应用层面,MeasureBench的评估能力直接关联到工业自动化、智能医疗设备和日常测量工具等多个关键领域。在工业环境中,压力表、电流表等仪器的自动读数对设备监控和安全生产至关重要;在医疗场景中,血氧仪、体温计等设备的准确识别直接关系到诊断质量;而在智能家居领域,水表、电表等公用事业仪表的自动化读数能够显著提升管理效率。这些实际应用场景对模型的精确感知能力提出了严格要求。
衍生相关工作
基于MeasureBench的基准特性,研究社区已经衍生出多个重要的相关研究方向。在模型架构方面,出现了专注于提升视觉编码器分辨率和细粒度特征提取能力的新方法;在训练策略上,研究者探索了基于合成数据的强化学习方案,如GRPO算法在测量读数任务上的应用;同时,针对特定仪器类型的专业化模型也不断涌现,这些工作共同推动了视觉语言模型在精确视觉理解方向的技术进步。
以上内容由遇见数据集搜集并总结生成


