medfit-dataset
收藏Hugging Face2025-09-16 更新2025-09-17 收录
下载链接:
https://huggingface.co/datasets/mlx-community/medfit-dataset
下载链接
链接失效反馈官方服务:
资源简介:
MEDFIT医疗问答数据集包含6444个独特的与医疗保健相关的问答对,专为医疗聊天机器人应用的语言模型微调而设计。该数据集是合成的,专注于特定领域,并针对聊天机器人训练进行了优化。它已在研究中使用,并在模型性能上取得了显著提升。该数据集遵循CC-BY-NC-4.0许可证,适用于非商业性研究和开发。
提供机构:
MLX Community创建时间:
2025-09-16
原始信息汇总
MEDFIT Medical QA Dataset 概述
基本属性
- 许可证: CC-BY-NC-4.0
- 语言: 英语
- 领域: 医疗保健和医疗信息
- 任务: 医疗聊天机器人的问答
- 规模: 6,444个独特的问答对
数据集构成
- 训练集: 5,155个样本(80%)
- 验证集: 644个样本(10%)
- 测试集: 645个样本(10%)
数据特征
- 高质量的医疗问答对
- 专注于医疗聊天机器人应用
- 平衡的医疗主题和场景覆盖
- 针对聊天机器人训练优化的格式
- 经过研究验证的有效性
数据创建流程
- 使用Phi-4生成10,000个医疗相关问答对的初始数据集
- 专注于医疗应用和医疗信息的问题筛选
- 去重处理,得到6,444个独特样本
- 医疗准确性的手动审查和验证
- 为聊天机器人训练和评估优化的结构化格式
性能表现
使用Llama-3.2-3B-Instruct模型微调后:
- 直接回答能力提升30个百分点(6.0% → 36.0%)
- 组织结构化回答提升18%
- 总体改进得分108.2(评估模型中最高的)
- 更好的医疗领域理解和上下文相关性
数据集统计
- 总样本数: 6,444个独特问答对
- 平均问题长度: 约15-20个词
- 平均回答长度: 约50-100个词
- 主题覆盖: 普通医学、症状、治疗、预防、健康教育
- 数据质量: 合成生成加手动整理和验证
主要应用
- 医疗聊天机器人训练
- 医疗保健AI开发
- 医疗信息系统开发
- 学术研究
限制与注意事项
- 不用于医疗诊断
- 需要专业监督
- 教育重点设计
- 需要持续验证
引用信息
bibtex @inproceedings{rao2025medfit, title={MEDFIT-LLM: Medical Enhancements through Domain-Focused Fine Tuning of Small Language Models}, author={Rao, Aditya Karnam Gururaj and Jaggi, Arjun and Naidu, Sonam}, booktitle={2025 2nd International Conference on Research Methodologies in Knowledge Management, Artificial Intelligence and Telecommunication Engineering (RMKMATE)}, year={2025}, organization={IEEE} }
相关资源
- 模型: https://huggingface.co/adityak74/medfit-llm-3B
- 论文: https://github.com/adityak74/medfit-llm
- 代码: https://github.com/adityak74/medfit-llm
许可证条款
- 允许研究和非商业用途
- 需要提供适当的署名
- 确保符合医疗数据使用指南
- 在医疗应用中实施适当的保障措施
- 保持医疗AI开发的道德标准
搜集汇总
数据集介绍
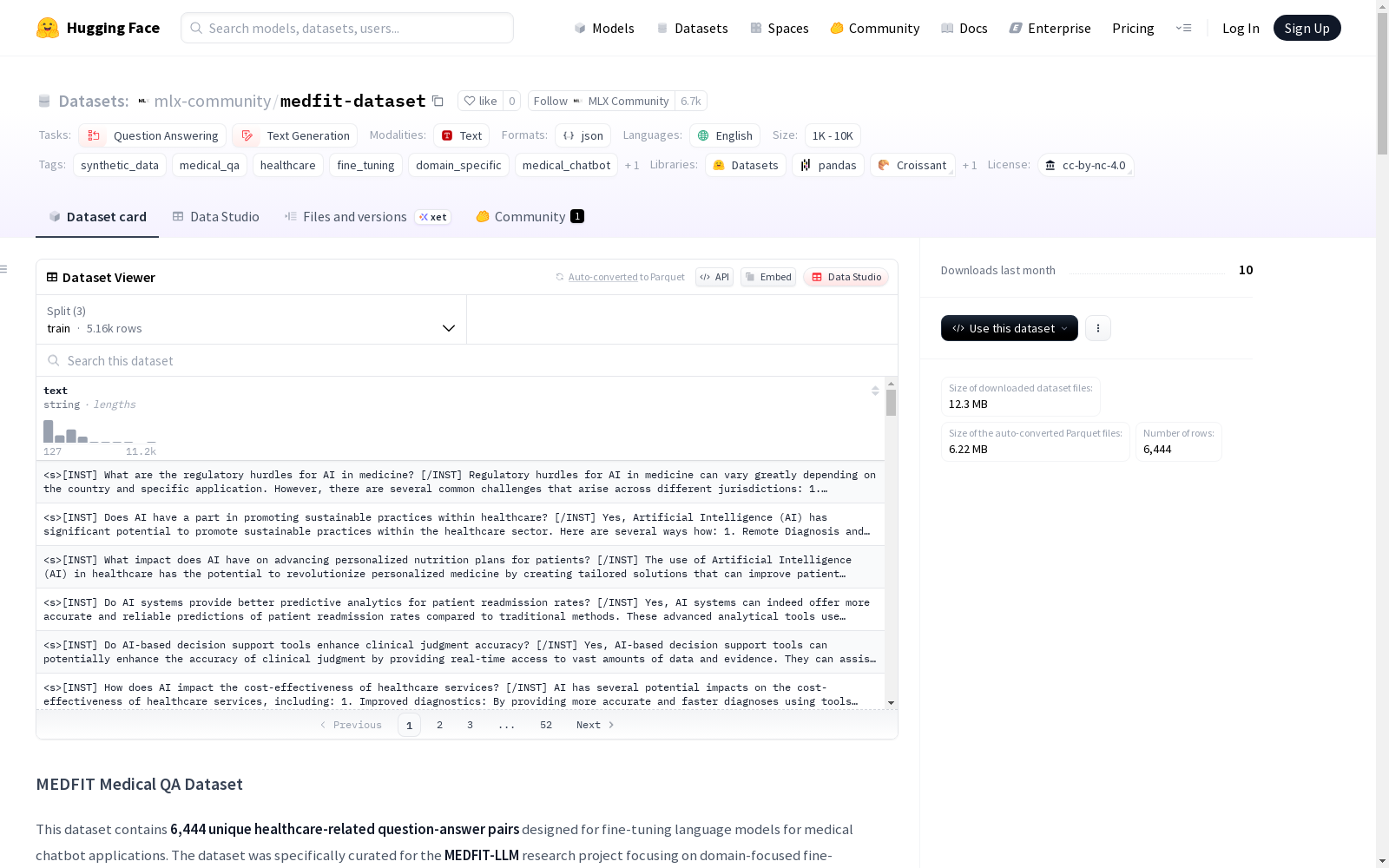
构建方式
在医疗问答数据集构建领域,MEDFIT数据集采用多阶段合成生成与人工筛选相结合的方法。研究团队首先运用Phi-4模型生成初始的10,000组医疗相关问答对,随后通过领域特异性筛选机制聚焦医疗健康应用场景,经过严格的重复数据消除流程后保留6,444组独特样本,最终通过人工医学准确性验证确保数据质量。
特点
该数据集展现出显著的领域专业化特征,涵盖广泛的医疗场景与健康话题,每个问答对都经过精心设计以符合医疗聊天机器人的应用需求。数据格式针对直接答案训练进行优化,具有结构化的响应模式,且经过同行评审研究验证能显著提升模型在医疗领域的理解能力与回答准确性。
使用方法
研究人员可通过Hugging Face的datasets库直接加载数据集,支持训练、验证和测试三个标准分割。该数据集特别适配MLX-LM框架进行参数高效微调,也兼容主流Transformer架构。使用时可配置不同超参数进行模型训练,最终生成适用于医疗对话场景的专业适配器。
背景与挑战
背景概述
医疗问答数据集MEDFIT由Aditya Karnam Gururaj Rao、Arjun Jaggi和Sonam Naidu团队于2025年创建,旨在推动小参数语言模型在医疗领域的专业化微调研究。该数据集包含6,444对高质量医患问答数据,专门针对MEDFIT-LLM研究项目设计,致力于解决医疗对话系统中自然语言处理的领域适应性问题。通过合成数据生成与人工校验相结合的方法,该数据集显著提升了模型在医疗咨询场景中的应答准确性与专业性,为医疗人工智能的发展提供了重要数据支撑。
当前挑战
医疗问答数据集构建面临双重挑战:在领域问题层面,需确保医学知识的准确性与时效性,同时处理医学术语的复杂性和多义性,这对模型的领域知识理解与推理能力提出极高要求;在构建过程中,合成数据生成需要克服语义一致性与医学逻辑严谨性的平衡难题,后续还需通过人工校验消除潜在错误,并解决数据去重与质量控制的技术瓶颈,这些环节均需跨学科协作与精密设计。
常用场景
经典使用场景
在医疗人工智能领域,MEDFIT数据集为语言模型的领域适应性微调提供了高质量的训练资源。该数据集通过精心设计的医疗问答对,支持研究人员构建专业医疗聊天机器人,使其能够准确理解医学问题并生成结构化的专业回答。典型应用包括使用Llama等基础模型进行参数高效微调,显著提升模型在医疗对话任务中的表现。
解决学术问题
该数据集有效解决了医疗自然语言处理中领域知识匮乏的核心问题。通过提供经过专业验证的医疗问答数据,它支持小参数语言模型获得准确的医学知识表示能力,显著改善了模型在医疗对话中的事实准确性和逻辑连贯性。这项工作为资源受限环境下的专业领域模型适配提供了重要范例,推动了医疗AI的可及性发展。
衍生相关工作
基于该数据集衍生的MEDFIT-LLM研究项目展示了显著的性能提升,相关成果已发表于IEEE国际会议。后续工作围绕医疗对话系统的优化展开,包括多轮对话增强、多模态医疗问答扩展等方向。该数据集还激发了医疗领域小参数模型微调的技术讨论,为专业领域的高效模型适配提供了重要基准。
以上内容由遇见数据集搜集并总结生成


