databricks/databricks-dolly-15k
收藏Hugging Face2023-06-30 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/databricks/databricks-dolly-15k
下载链接
链接失效反馈资源简介:
---
license: cc-by-sa-3.0
task_categories:
- question-answering
- summarization
language:
- en
size_categories:
- 10K<n<100K
---
# Summary
`databricks-dolly-15k` is an open source dataset of instruction-following records generated by thousands of Databricks employees in several
of the behavioral categories outlined in the [InstructGPT](https://arxiv.org/abs/2203.02155) paper, including brainstorming, classification,
closed QA, generation, information extraction, open QA, and summarization.
This dataset can be used for any purpose, whether academic or commercial, under the terms of the
[Creative Commons Attribution-ShareAlike 3.0 Unported License](https://creativecommons.org/licenses/by-sa/3.0/legalcode).
Supported Tasks:
- Training LLMs
- Synthetic Data Generation
- Data Augmentation
Languages: English
Version: 1.0
**Owner: Databricks, Inc.**
# Dataset Overview
`databricks-dolly-15k` is a corpus of more than 15,000 records generated by thousands of Databricks employees to enable large language
models to exhibit the magical interactivity of ChatGPT.
Databricks employees were invited to create prompt / response pairs in each of eight different instruction categories, including
the seven outlined in the InstructGPT paper, as well as an open-ended free-form category. The contributors were instructed to avoid using
information from any source on the web with the exception of Wikipedia (for particular subsets of instruction categories), and explicitly
instructed to avoid using generative AI in formulating instructions or responses. Examples of each behavior were provided to motivate the
types of questions and instructions appropriate to each category.
Halfway through the data generation process, contributors were given the option of answering questions posed by other contributors.
They were asked to rephrase the original question and only select questions they could be reasonably expected to answer correctly.
For certain categories contributors were asked to provide reference texts copied from Wikipedia. Reference text (indicated by the `context`
field in the actual dataset) may contain bracketed Wikipedia citation numbers (e.g. `[42]`) which we recommend users remove for downstream applications.
# Intended Uses
While immediately valuable for instruction fine tuning large language models, as a corpus of human-generated instruction prompts,
this dataset also presents a valuable opportunity for synthetic data generation in the methods outlined in the Self-Instruct paper.
For example, contributor--generated prompts could be submitted as few-shot examples to a large open language model to generate a
corpus of millions of examples of instructions in each of the respective InstructGPT categories.
Likewise, both the instructions and responses present fertile ground for data augmentation. A paraphrasing model might be used to
restate each prompt or short responses, with the resulting text associated to the respective ground-truth sample. Such an approach might
provide a form of regularization on the dataset that could allow for more robust instruction-following behavior in models derived from
these synthetic datasets.
# Dataset
## Purpose of Collection
As part of our continuing commitment to open source, Databricks developed what is, to the best of our knowledge, the first open source,
human-generated instruction corpus specifically designed to enable large language models to exhibit the magical interactivity of ChatGPT.
Unlike other datasets that are limited to non-commercial use, this dataset can be used, modified, and extended for any purpose, including
academic or commercial applications.
## Sources
- **Human-generated data**: Databricks employees were invited to create prompt / response pairs in each of eight different instruction categories.
- **Wikipedia**: For instruction categories that require an annotator to consult a reference text (information extraction, closed QA, summarization)
contributors selected passages from Wikipedia for particular subsets of instruction categories. No guidance was given to annotators as to how to select the
target passages.
## Annotator Guidelines
To create a record, employees were given a brief description of the annotation task as well as examples of the types of prompts typical
of each annotation task. Guidelines were succinct by design so as to encourage a high task completion rate, possibly at the cost of
rigorous compliance to an annotation rubric that concretely and reliably operationalizes the specific task. Caveat emptor.
The annotation guidelines for each of the categories are as follows:
- **Creative Writing**: Write a question or instruction that requires a creative, open-ended written response. The instruction should be reasonable to ask of a person with general world knowledge and should not require searching. In this task, your prompt should give very specific instructions to follow. Constraints, instructions, guidelines, or requirements all work, and the more of them the better.
- **Closed QA**: Write a question or instruction that requires factually correct response based on a passage of text from Wikipedia. The question can be complex and can involve human-level reasoning capabilities, but should not require special knowledge. To create a question for this task include both the text of the question as well as the reference text in the form.
- **Open QA**: Write a question that can be answered using general world knowledge or at most a single search. This task asks for opinions and facts about the world at large and does not provide any reference text for consultation.
- **Summarization**: Give a summary of a paragraph from Wikipedia. Please don't ask questions that will require more than 3-5 minutes to answer. To create a question for this task include both the text of the question as well as the reference text in the form.
- **Information Extraction**: These questions involve reading a paragraph from Wikipedia and extracting information from the passage. Everything required to produce an answer (e.g. a list, keywords etc) should be included in the passages. To create a question for this task include both the text of the question as well as the reference text in the form.
- **Classification**: These prompts contain lists or examples of entities to be classified, e.g. movie reviews, products, etc. In this task the text or list of entities under consideration is contained in the prompt (e.g. there is no reference text.). You can choose any categories for classification you like, the more diverse the better.
- **Brainstorming**: Think up lots of examples in response to a question asking to brainstorm ideas.
## Personal or Sensitive Data
This dataset contains public information (e.g., some information from Wikipedia). To our knowledge, there are no private person’s personal identifiers or sensitive information.
## Language
American English
# Known Limitations
- Wikipedia is a crowdsourced corpus and the contents of this dataset may reflect the bias, factual errors and topical focus found in Wikipedia
- Some annotators may not be native English speakers
- Annotator demographics and subject matter may reflect the makeup of Databricks employees
# Citation
```
@online{DatabricksBlog2023DollyV2,
author = {Mike Conover and Matt Hayes and Ankit Mathur and Jianwei Xie and Jun Wan and Sam Shah and Ali Ghodsi and Patrick Wendell and Matei Zaharia and Reynold Xin},
title = {Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM},
year = {2023},
url = {https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm},
urldate = {2023-06-30}
}
```
# License/Attribution
**Copyright (2023) Databricks, Inc.**
This dataset was developed at Databricks (https://www.databricks.com) and its use is subject to the CC BY-SA 3.0 license.
Certain categories of material in the dataset include materials from the following sources, licensed under the CC BY-SA 3.0 license:
Wikipedia (various pages) - https://www.wikipedia.org/
Copyright © Wikipedia editors and contributors.
---
许可证:CC BY-SA 3.0
任务类别:
- 问答
- 摘要生成
语言:
- 英语
规模类别:
- 10K < 样本数 < 100K
---
# 摘要
`databricks-dolly-15k` 是一款开源指令跟随数据集,由数千名Databricks员工基于InstructGPT论文(https://arxiv.org/abs/2203.02155)所提出的数种行为类别生成,涵盖头脑风暴、分类、封闭域问答、生成、信息抽取、开放域问答以及摘要生成等任务。
本数据集可在《知识共享署名-相同方式共享3.0未移植许可》(Creative Commons Attribution-ShareAlike 3.0 Unported License,https://creativecommons.org/licenses/by-sa/3.0/legalcode)条款下,用于学术及商业等任意用途。
支持的任务:
- 训练大语言模型(Large Language Model,LLM)
- 合成数据生成
- 数据增强
语言:英语
版本:1.0
**所有者:Databricks公司**
# 数据集概览
`databricks-dolly-15k` 是一个包含逾15000条记录的语料库,由数千名Databricks员工生成,旨在让大语言模型(Large Language Model,LLM)具备ChatGPT般的神奇交互能力。
Databricks员工受邀创建8种不同指令类别的提示词-应答对,其中包含InstructGPT论文中提及的7种类别,以及一种开放式自由格式类别。参与者被要求不得使用网络上除维基百科外的任何来源信息(特定指令类别除外),并明确禁止在撰写提示词或应答时使用生成式AI。每个类别均配有示例,以引导参与者生成符合该类别的问题与指令。
在数据生成流程进行至一半时,参与者可选择应答其他参与者提出的问题,同时需对原问题进行改写,并仅选择自身有能力正确作答的问题。
对于部分类别,参与者需提供从维基百科摘抄的参考文本。实际数据集中以`context`字段表示的参考文本可能包含带方括号的维基百科引用编号(例如`[42]`),我们建议下游应用使用者将其移除。
# 预期用途
本数据集作为人类生成的指令提示词语料库,可直接用于大语言模型的指令微调,同时也为基于《Self-Instruct》论文所述方法开展合成数据生成提供了宝贵契机。例如,可将参与者生成的提示词作为少样本(Few-shot)示例输入至开源大语言模型,为InstructGPT的各类别生成百万级的指令示例语料库。
同理,提示词与应答均可作为数据增强的优质素材。可利用释义模型改写每条提示词或短应答,并将生成文本与对应的真实样本绑定。此类方法可对数据集实现正则化处理,使基于该合成数据集训练的模型能够更稳健地遵循指令进行交互。
# 数据集
## 收集目的
作为Databricks对开源社区持续承诺的一部分,本团队开发了据我们所知首个专为让大语言模型具备ChatGPT般神奇交互能力而设计的人类生成开源指令语料库。与其他仅限非商业用途的数据集不同,本数据集可用于包括学术及商业在内的任意用途,亦可进行修改与扩展。
## 数据来源
- **人工生成数据**:Databricks员工受邀创建8种不同指令类别的提示词-应答对。
- **维基百科**:对于需要参考文本的指令类别(信息抽取、封闭域问答、摘要生成),参与者从维基百科中选取段落用于特定指令子类别的生成。未向标注者提供选取目标段落的相关指引。
## 标注指南
为生成一条数据记录,参与者会收到标注任务的简要说明以及各类别典型提示词示例。标注指南设计得简洁明了,以提升任务完成率,但可能导致标注者无法严格遵循精准且可复现的任务操作规范。特此声明:概不负责(Caveat emptor)。
各分类的标注指南如下:
- **创意写作**:编写需要以创造性、开放式书面应答完成的问题或指令。该指令应符合具备通用世界知识的普通人的作答逻辑,且无需额外检索。本任务中,提示词需给出明确的遵循要求,约束条件、操作指引或具体要求均可,且内容越详尽越好。
- **封闭域问答**:编写需要基于维基百科段落给出事实准确应答的问题或指令。问题可具备复杂性,需达到人类水平的推理能力,但无需特殊专业知识。本任务需在表单中同时包含问题文本与参考文本。
- **开放域问答**:编写可通过通用世界知识或至多一次检索即可作答的问题。本任务需回答关于宏观世界的观点与事实,且无需提供参考文本。
- **摘要生成**:对维基百科中的某一段落生成摘要。请勿设置需要3-5分钟以上作答时间的问题。本任务需在表单中同时包含问题文本与参考文本。
- **信息抽取**:此类问题需阅读维基百科段落并从中抽取信息。生成应答所需的全部内容(例如列表、关键词等)均应包含在段落中。本任务需在表单中同时包含问题文本与参考文本。
- **分类**:此类提示词包含待分类的实体列表或示例,例如影评、商品等。本任务中,待处理的文本或实体列表均包含在提示词内(无需参考文本)。可自选任意分类标准,分类维度越多样越好。
- **头脑风暴**:针对需要构思创意的问题,生成大量相关示例。
## 个人与敏感数据
本数据集包含公开信息(例如部分维基百科内容)。据我们所知,数据中未包含任何个人身份标识或敏感信息。
## 语言
美式英语
# 已知局限性
- 维基百科是众包语料库,本数据集的内容可能反映维基百科中存在的偏见、事实错误与主题侧重。
- 部分标注者并非以英语为母语。
- 标注者的人口统计学特征与主题选择可能反映Databricks员工的群体构成。
# 引用
@online{DatabricksBlog2023DollyV2,
author = {Mike Conover and Matt Hayes and Ankit Mathur and Jianwei Xie and Jun Wan and Sam Shah and Ali Ghodsi and Patrick Wendell and Matei Zaharia and Reynold Xin},
title = {Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM},
year = {2023},
url = {https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm},
urldate = {2023-06-30}
}
# 许可与归因
**版权所有(2023)Databricks公司**
本数据集由Databricks开发(https://www.databricks.com),使用需遵循CC BY-SA 3.0许可协议。
本数据集中部分类别素材包含以下来源的内容,其使用需遵循CC BY-SA 3.0许可协议:
维基百科(各页面)- https://www.wikipedia.org/
版权所有 © 维基百科编辑与贡献者。
提供机构:
databricks
原始信息汇总
数据集概述
名称: databricks-dolly-15k
描述: 该数据集包含超过15,000条记录,由数千名Databricks员工生成,旨在使大型语言模型展现出ChatGPT的交互特性。数据集涵盖了八个不同的指令类别,包括创意写作、封闭式问答、开放式问答、总结、信息提取、分类和头脑风暴等。
语言: 英语
规模: 10K<n<100K
许可: Creative Commons Attribution-ShareAlike 3.0 Unported License
数据集用途
- 训练LLMs: 用于微调大型语言模型。
- 合成数据生成: 利用人类生成的指令提示进行数据生成。
- 数据增强: 通过重述每个提示或简短响应,提供数据集的正则化。
数据集收集目的
- 作为开放源代码的一部分,Databricks开发了首个开放源代码、人类生成的指令语料库,旨在使大型语言模型展现出ChatGPT的交互特性。
数据来源
- 人类生成数据: Databricks员工创建的提示/响应对。
- Wikipedia: 特定指令类别中,从Wikipedia选取的段落。
标注指南
- 创意写作: 要求创造性、开放式的书面响应。
- 封闭式问答: 基于Wikipedia文本的事实正确响应。
- 开放式问答: 使用通用世界知识或单一搜索即可回答的问题。
- 总结: 对Wikipedia段落的总结。
- 信息提取: 从Wikipedia段落中提取信息。
- 分类: 包含实体列表或示例的分类任务。
- 头脑风暴: 针对问题提出大量想法。
语言
- 美式英语
已知限制
- 数据集内容可能反映Wikipedia的偏见、事实错误和主题焦点。
- 部分标注者可能不是英语母语者。
- 标注者的背景和主题可能反映Databricks员工的构成。
搜集汇总
数据集介绍
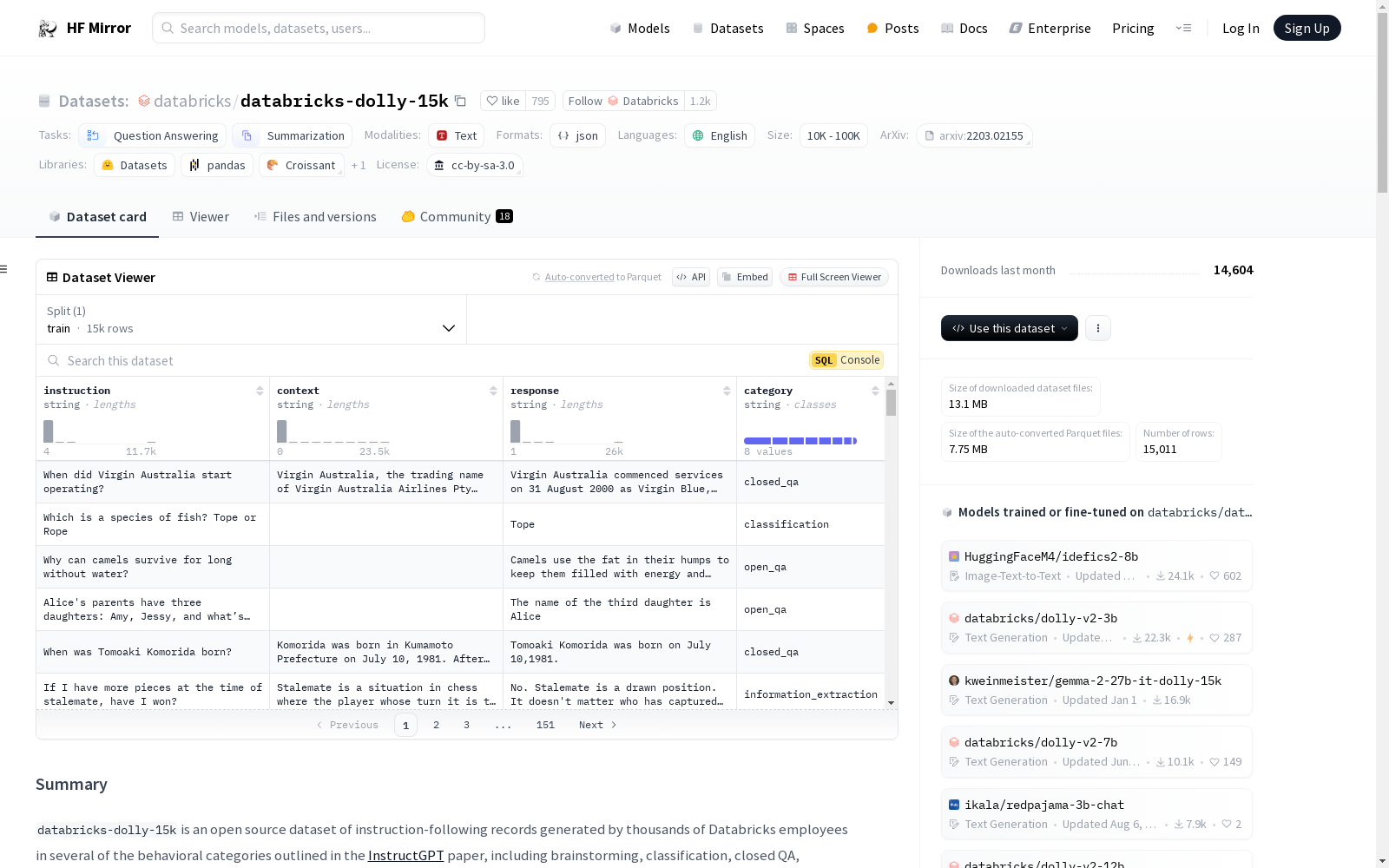
构建方式
databricks-dolly-15k数据集是由Databricks公司的员工生成的,包含超过15000条指令遵循记录的语料库。这些记录是在八个不同的指令类别中创建的,包括InstructGPT论文中概述的七个类别以及一个开放式自由形式类别。参与者被指示避免使用来自网络的任何信息,除维基百科外,并且在制定指令或响应时明确指示不要使用生成式AI。在数据生成过程的中途,参与者还被提供了回答其他参与者提出问题的选项,以此方式丰富数据集的内容。
特点
该数据集的特点在于其开放性和多样性,可用于学术或商业目的。它不仅包含了人类生成的指令和响应对,还提供了从维基百科摘录的参考文本,有助于模型在信息提取、封闭式问答、总结等任务上的训练。此外,数据集中的注释者指南旨在鼓励创造性思维和开放性指令,尽管这可能以对任务严格规范的遵守为代价。
使用方法
使用databricks-dolly-15k数据集时,用户可以根据数据集中的指令类别进行相应的模型训练,如大型语言模型的指令微调、合成数据生成和数据增强。用户可以利用贡献者生成的提示作为少量样本,以生成数百万个各种InstructGPT类别的指令语料库。同时,指令和响应均可用于数据增强,例如使用释义模型重新表达每个提示或简短响应,以提供对数据集的正则化,从而允许从这些合成数据集中派生的模型表现出更加稳健的指令遵循行为。
背景与挑战
背景概述
在人工智能领域,语言模型的发展日新月异。`databricks-dolly-15k`数据集,由Databricks公司于2023年推出,汇聚了15000余条由员工创作的指令遵循记录,旨在推动大型语言模型展现出类似ChatGPT的神奇交互性。该数据集涵盖了包括创意写作、分类、封闭式问答、生成、信息提取、开放式问答和总结在内的多种行为类别,是首个开源的、专门为大型语言模型设计的、人类生成的指令语料库,对学术和商业应用均开放使用,具有重要的研究价值和广泛的应用前景。
当前挑战
尽管`databricks-dolly-15k`数据集在促进大型语言模型训练方面具有显著作用,但其构建过程中亦面临诸多挑战。首先,数据集的来源几乎完全依赖于Databricks员工,这可能导致数据来源的同质化。其次,数据集中部分内容来源于维基百科,可能携带维基百科的偏见和事实错误。此外,数据集中可能存在非英语母语标注者的语言误差,以及标注者人群可能不能完全代表广泛的社会多样性,这些都是未来研究和应用中需要注意的问题。
常用场景
经典使用场景
在自然语言处理领域,`databricks-dolly-15k` 数据集的显著应用便是作为大型语言模型指令微调的典范。其包含的指令遵循记录,为训练模型在诸如问答、总结等任务上的指令跟随能力提供了丰富的素材,使得模型能够模拟ChatGPT般的神奇交互性。
实际应用
在实际应用中,`databricks-dolly-15k` 数据集可用于合成数据生成,为各种任务提供丰富的指令样例。此外,它也可用于数据增强,通过指令和响应的改写,为模型训练提供更加多样化的数据,增强模型的泛化能力。
衍生相关工作
基于`databricks-dolly-15k` 数据集,研究者可以开展一系列相关工作,如开发新的指令微调框架、探索更高效的数据增强策略,以及构建能够更好地理解和执行复杂人类指令的语言模型。
以上内容由遇见数据集搜集并总结生成


